Инструменты режима градуировки по сериям
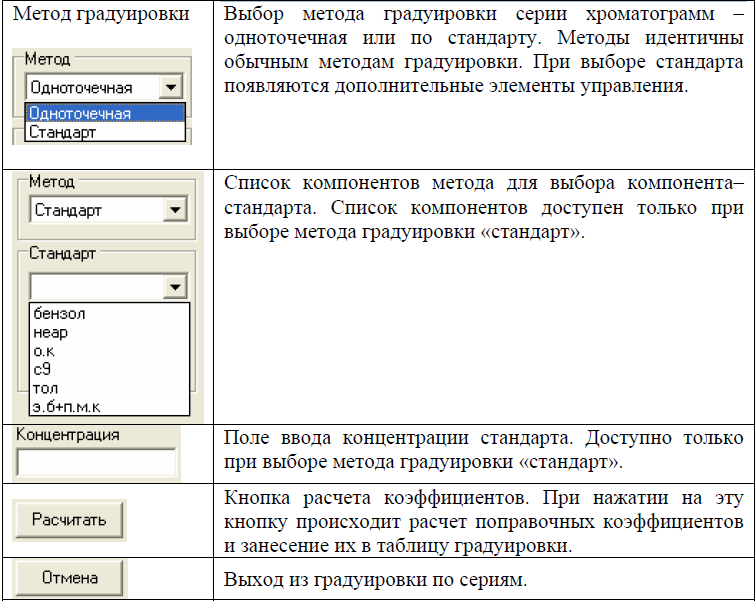
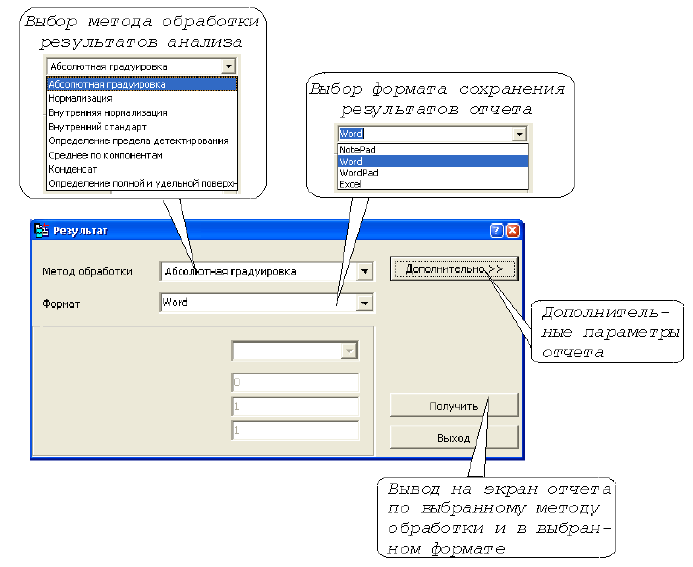
Рис. А.22. Режим «РЕЗУЛЬТАТ»
Режим «РЕЗУЛЬТАТ» предназначен для получения отчета о сделанном хроматографическом анализе. Диалоговое окно режима (рис. А.22) содержит три группы элементов:
Метод обработки. В данном элементе указывается метод обработки результата. На данный момент в программе заложены следующие методы обработки: Абсолютная градуировка, Нормализация, Внутренняя нормализация, Внутренний стандарт и Определение предела детектирования.
Формат. Определяет редактор, в котором будет сформирован отчет. Поддерживается 4 типа редакторов:
Notepad.Самый простой текстовый редактор Windows.
Wordpad. Также довольно простой редактор, но поддерживающий дополнительные функции.
Word. Мощный текстовый редактор. Чтобы воспользоваться данным редактором, необходимо установить MS Office 97 или выше.
Excel.Редактор электронных таблиц. Чтобы воспользоваться данным
редактором необходимо установить MS Office 97 или выше. По умолчанию все числа в отчете имеют 4 знака после запятой. Пользователь может изменить точность отображения чисел. Для этого в данном поле после наименования формата вводят двоеточие и число знаков после запятой от 0 до 9. Например, после выбора формата «Word» в конец дописывается точность в 7 знаков и получается «Word:7». Теперь все числа будут представляться с семью знаками после запятой.
Дополнительные поляиспользуются для указания дополнительных параметров. Данные поля имеют различное назначение для различных методов обработки. В частности, для внутреннего стандарта добавляются два поля: для имени стандарта и количестве вещества.
Кнопка «Получить»выводит на экран отчет по выбранному методу обработки и в выбранном формате.
Кнопка «Дополнительно»расширяет диалоговое окно дополнительными параметрами (рис. А.23).
В группе «Параметры вывода»указывается, что именно необходимо включать в отчет (паспорт, параметры управления, технические данные, комментарии, рисунок).
При установлении флажка «Копию на принтер»произойдет печать отчета на принтер по завершении его формирования.
Убрать дополнительные параметры можно нажав кнопку «Свернуть».
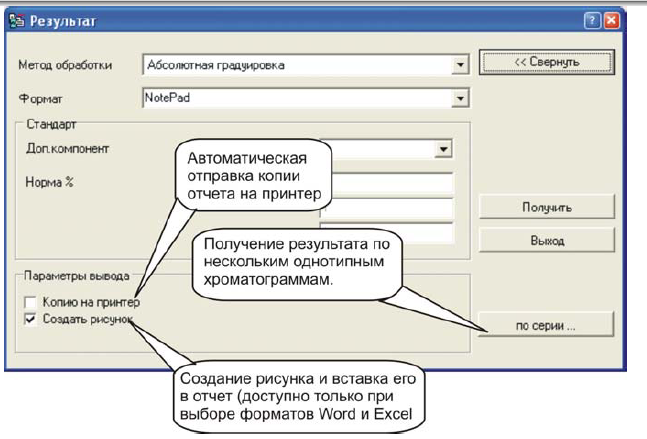
Рис. А.23. Режим «РЕЗУЛЬТАТ» с дополнительными параметрами
Методы обработки. Данный раздел описывает доступные на настоящий момент методы обработки из режима «РЕЗУЛЬТАТ».
Ниже приведен список методов, реализованных в настоящее время.
Список сокращений:
C– концентрация компонента;
S– площадь или высота пика в зависимости от выбранной базы расчета (см. раздел «Идентификация»);
ΣSi –сумма площадей всех пиков на хроматограмме (включая неидентифицированные);
К2, К1, К0– коэффициенты пропорциональности при пересчете площади или высоты в концентрацию.
Абсолютная градуировка.При этом концентрации рассчитываются по формуле
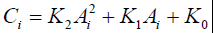 .
.
Дополнительно можно ввести наименование дополнительного компонента, который физически присутствует в анализируемой смеси, но фактически не выходит на хроматограмме. В этом случае концентрация дополнительного компонента рассчитывается как «Норма» – суммарная концентрация всех присутствующих компонентов в смеси.
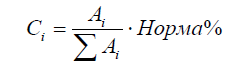 ,
,
где «Норма» – произвольное значение в процентах.
Внутренняя нормализация. Расчет концентраций в % по формуле
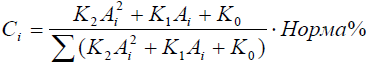 .
.
В данном случае суммирование в знаменателе проводится только по идентифицированным пикам.
Внутренний стандарт. Для обработки данных методом внутреннего стандарта необходимо, чтобы в исследуемом образце был сам стандарт – какое-либо вещество с известной концентрацией, а также известны коэффициенты чувствительности исследуемого соединения по отношению к внутреннему стандарту. При этом определяется концентрация только одного соединения в многокомпонентной смеси, в которой также присутствует стандарт. Расчет количества компонентов по следующей формуле.
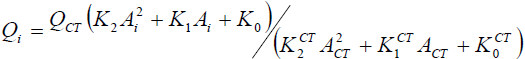 ,
,
где величины с индексом (ст) относятся к стандарту.
В данном случае используются дополнительные поля для задания имени и количества компонентов.
Определение предела детектирования. В комплект поставки входит программа для определения шума, дрейфа и предела детектирования вашего прибора в соответствии с ГОСТ Р 50205-92.
Среднее по компонентам. Расчет усредненной концентрации по нескольким одинаковым компонентам, имеющим одинаковые имена в таблице идентификации.
Конденсат. Расчет суммарной концентрации по нескольким компонентам, в том числе не имеющих имен в таблице идентификации.
Определение шума. Расчет по хроматограмме шума и дрейфа детектора.
Получение результата по сериям. Этот режим предназначен для получения усредненного результата по серии однотипных анализов. Для того, чтобы перейти в этот режим необходимо нажать кнопку «по сериям» в окне режима «РЕЗУЛЬТАТ».
Работа с программой «ПОВЕРКА». Программа «ПОВЕРКА» предназначена для автоматического расчета метрологических характеристик хроматографов и ПАК. Программа позволяет рассчитывать следующие параметры:
– СКО площадей, высот и времен выходов пиков;
– Изменение выходного сигнала за 48 часов работы;
– Уровень флуктуационных шумов;
– Уровень дрейфа нулевого сигнала;
– Предел детектирования;
Для работы с программой статистики выберите в меню «ПУСК» пункт «ПРОГРАММЫ» и подпункт «ХРОМАТОГРАФИЯ», где у Вас собраны все программы для работы с хроматографом. Далее выберите пункт «Поверка». Программа выдаст окно (рис. А.24):
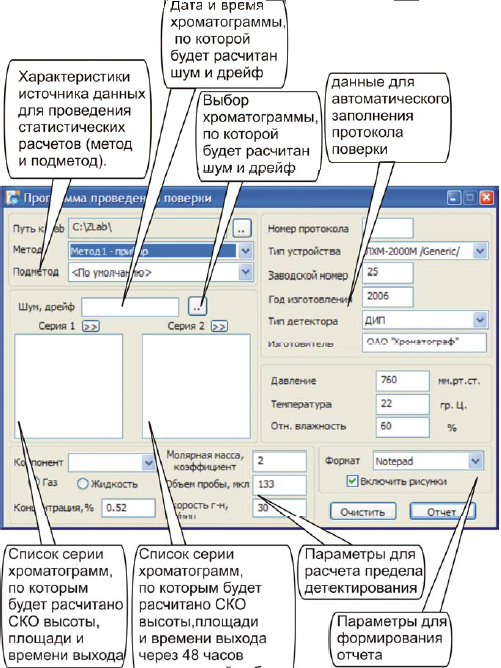
Рис. А.23. Окно программы «ПОВЕРКА»
Для проведения поверки необходимо:
1. Снять сигнал с поверяемого детектора – сформировать «пустую» хроматограмму.
2. Снять не менее 5-ти хроматограмм для расчета СКО площади, высоты и времен выхода пика.
3. Через 48 часов снять еще 5 хроматограмм для расчета изменения работы выходного сигнала.
4. Запустить программу «ПОВЕРКА»
5. Выбрать из списка необходимый метод (или окно) и подметод (при необходимости).
6. Выбрать хроматограммы для расчета шума, дрейфа и метрологических
характеристик.
7. Из списка компонентов, заполняемого по 1-й хроматограмме «Серии 1», выбрать тот (если компонентов несколько), для которого необходимо рассчитать предел детектирования. Ввести необходимые дополнительные параметры.
8. Заполнить раздел для автоматического формирования протокола поверки.
9. Выбрать формат вывода отчета (NotePad, Ms Office).
10. Нажать кнопку «Отчет».
ПРИЛОЖЕНИЕ Б
Алгоритмы обработки результатов измерений
Алгоритмы фильтрации
Для фильтрации шумов и выбросов используются три алгоритма фильтрации:
Фильтр выбросов.
Медианный фильтр.
Фильтр Гаусса.
Ниже рассмотрены алгоритмы всех трех фильтров.
Фильтр выбросов.В основе алгоритма фильтра выбросов лежит идея удаления одиночных точек, которые являются заведомо случайными выбросами. Точка считается выбросом, если она отстоит от своего ближайшего соседа (слева или справа) на расстояние, превышающее троекратное значение шума базовой линии. В этом случае данная точка опускается (или поднимается) до уровня своего ближайшего соседа (Рис. Б.1.).
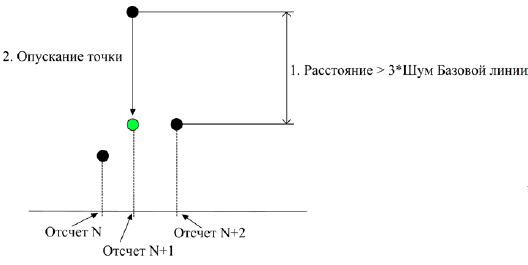
Рис. Б.1. Фильтр выбросов
После съема хроматограмма обрабатывается фильтром выбросов в обязательном порядке. Фильтр выбросов обеспечивает надежное отсеивание одиночных выбросов.
Медианный фильтр.Медианный фильтр, в отличие от фильтра выбросов, использует алгоритм сглаживания.
В поле параметра медианного фильтра пользователь вводит ширину щели, на которой будет происходить усреднение точек. При этом ширина точки может иметь только нечетное значение (если вводится четное значение, то оно автоматически изменяется на большее нечетное).
Алгоритм сглаживания следующий:
Последовательно выбираются все точки хроматограммы. Для каждой точки выбираются точки, отстоящие от текущей на полуширину щели. Таким образом, получается массив, размер которого равен ширине щели, а текущая точка является центральной точкой массива.
Полученный массив сортируется по возрастанию.
Вместо текущей точки записывается точка, стоящая в середине отсортированного массива. Таким образом, каждая точка заменяется средней точкой в щели.
Происходит переход на следующую точку хроматограммы и операция повторяется для следующей точки (рис. Б.2).
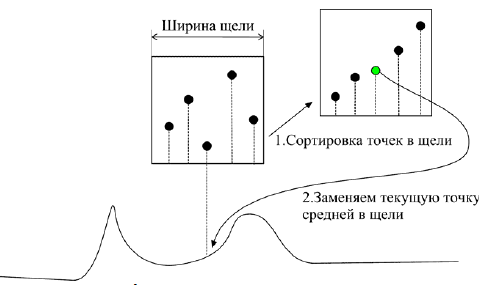
Рис. Б.2. Медианный фильтр
Фильтр Гаусса.
Алгоритм фильтрации по Гауссу основывается на том, что идеальная форма пика близка к гауссовскому распределению:
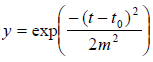 ,
,
где t0– центральная точка пика, m – ширина пика на полувысоте.
Пользователь вводит параметр, который определяет ширину ожидаемых пиков. Далее все пики, ширина которых совпадает с ожидаемой шириной, проходят фильтрацию без «потерь», а высота остальных пиков, имеющих отклонение от ожидаемой ширины, уменьшается.
Вводимый пользователем параметр для фильтра должен иметь нечетное значение (в случае четного значение происходит увеличение до ближайшего нечетного значения). Этот параметр определяет ширину щели (в отсчетах, приходящих с пробора), в которой происходит сглаживание.
Алгоритм состоит из следующих этапов:
Составляется массив коэффициентов, число элементов которого равно ширине щели. Значения коэффициентов внутри массива распределены по закону Гаусса. Сумма всех коэффициентов в массиве равна единице. Пример массива коэффициентов для щели размером 5 приведен ниже:
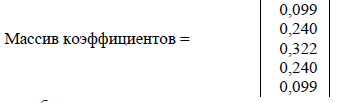
2) Последовательно выбираются все точки хроматограммы.
3) Для каждой точки выбираются точки, отстоящие от текущей на полуширину щели. Таким образом, получается массив, размер которого равен ширине щели, а текущая точка является центральной точкой массива.
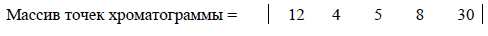
4) Полученный массив с точками хроматограммы умножается на массив коэффициентов по правилам умножения матриц. Полученный результат записывается на место текущей точки. Таким образом, происходит выделение пика идеальной формы.
Значение = Массив точек Массив
в текущей точке х коэффициентов
хроматограммы
Происходит переход к следующей точке хроматограммы и процесс повторяется.
Алгоритм разметки на пики.Процесс разметки хроматограммы на пики основан на вычислении производной и сравнении полученного значения с задаваемым порогом.
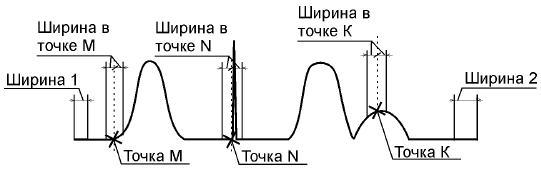
Рис. Б3. Расчет «Ширины» в каждой точке хроматограммы
Рассмотрим последовательность действий при использовании алгоритма:
1. Вычисляется шум базовой линии как усредненная сумма всех отклонений на хроматограмме.
2. Значение «Задержка» определяет начальный участок хроматограммы (в секундах), на котором пики не идентифицируются. Этот параметр используется в случае больших выбросов в начале хроматограммы в момент ввода пробы.
3. Для каждой точки хроматограммы рассчитывается значение «Ширина», путем линейной интерполяции значений «Ширина 1» (в начале хроматограммы) и «Ширина 2» (в конце хроматограммы). На рассчитанной ширине вычисляется значение производной. Таким образом, для каждой точки хроматограммы вычисляется значение производной (рис. Б3).
4. Производная в каждой точке сравнивается со значением «Порог».
Если конец одного из пиков совпадает (или перекрывается) с началом другого пика, то данные пики принимаются неразделенными.
Если после выявления вершины пика, на протяжении троекратного значения ширины не идентифицируется склон пика, то считается, что это не пик, а скачок базовой линии (рис. Б.4, Б.5).
После выявления всех пиков определяется вид базовой линии, т. е. линии, на фоне которой выходят пики. В местах отсутствия пиков базовая линия совпадает с хроматограммой. В местах, где присутствуют пики, базовая линия проходит под ними и является прямой, соединяющей начало и конец пика. В случае неразделенных пиков базовой линией является прямая соединяющая начало левого неразделенного пика и конец правого неразделенного пика.
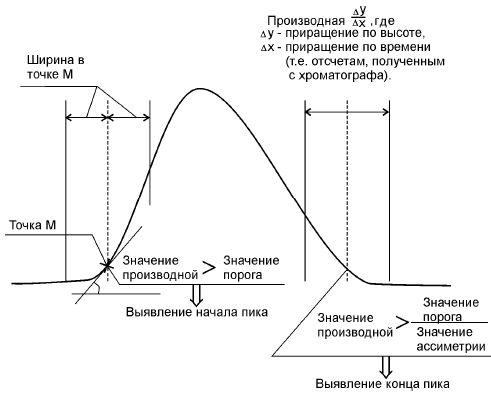
Рис.Б.4. Выявление начала и конца пика
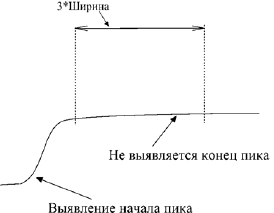
Рис.Б.5. Скачок базовой линии
Затем вычисляются площади всех пиков. Для разделенных пиков – это площадь фигуры между хроматограммой и базовой линией под пиком. Для неразделенных пиков – опускается перпендикуляр в точке соприкосновения пиков (рис. Б.6).
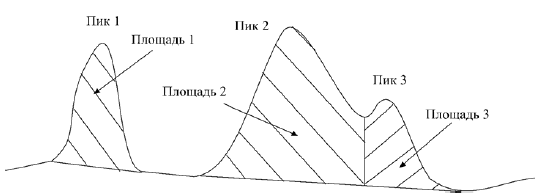
Рис.Б.6. Определение площадей пиков
Далее проводится анализ на присутствие «пиков-наездников», возможных только на заднем склоне неразделенного пика. Для этого рассчитывается соотношение площадей неразделенных пиков. Если отношение площади левого неразделенного пика к площади правого неразделенного пика меньше значения «Наездник» (значение вводится пользователем), то правый пик считается наездником (рис. Б.7).
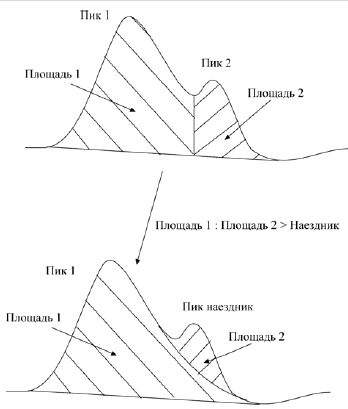
Рис.Б.7. Определения пика-наездника
После завершения разметки хроматограммы происходит отсев выявленных пиков по «Минимальной высоте» и «Минимальной площади» (данные значения задаются пользователем).
Алгоритм идентификации компонентов. В основе алгоритма идентификации лежит сопоставление ожидаемым компонентам размеченных пиков. Для каждого компонента пользователь задает в таблице идентификации (рис. Б.8):
– наименование компонента;
– ожидаемое время выхода компонента;
– допуск.
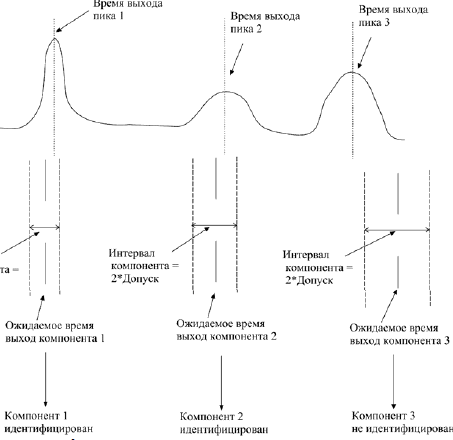
Рис. Б.8. Идентификация компонентов
На основании времени выхода и допуска составляется интервал времени от («Время выхода» – «Допуск») до («Время выхода» + «Допуск»), на котором ищется размеченный пик (интервал компонента). Если на данном интервале находится размеченный пик, то данному компоненту ставится в соответствие найденный пик. По площади пика находится концентрация компонента.
Если в интервал компонента попадают сразу несколько пиков, то идентифицируется пик, ближайший к времени выхода (рис. Б.9).
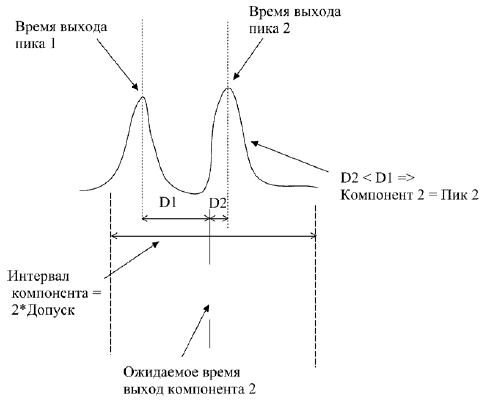
Рис. Б.9.. Идентификация при нескольких пиках в интервале компонента
Если длительное время программа функционирует без градуировки метода, то реальные времена выхода компонентов могут значительно «уплыть» относительно ожидаемых из-за изменения параметров хроматографа. Для борьбы с этим эффектом используют процедуру корректировки времени. При этом все ожидаемые времена компонентов в таблице идентификации становятся равными реальным временам выхода. Для неидентифицированных компонентов ожидаемые времена выхода корректируются по линейному закону относительно соседних идентифицированных компонентов (рис. Б.10).
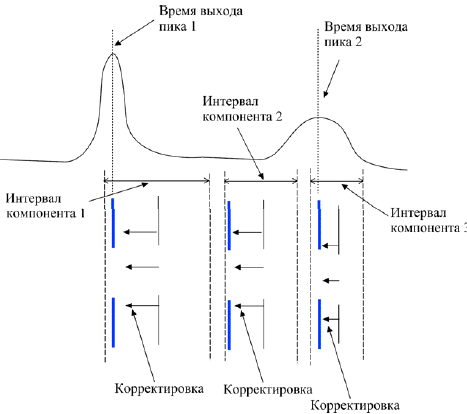
Рис.Б.10. Корректировка времени
В качестве способа борьбы с «уплыванием» реальных времен относительно ожидаемых можно применять метод реперных пиков. Пользователь вводит реперные компоненты в таблицу идентификации, указывая для них свойство «Репер». В качестве реперных пиков выбирают пики, максимальные на определенном участке хроматограммы. Для реперных пиков обычно указывают расширенный допуск (при этом на интервале компонента реперный пик должен быть заведомо максимальным по высоте).
Суть метода заключается в следующем (рис. Б.11):
Из таблицы идентификации выбираются реперные компоненты. Для каждого реперного компонента находится соответствующий ему пик: на интервале компонента находится максимальный по высоте пик (а не ближайший к ожидаемому времени выхода, как для обычных компонентов).
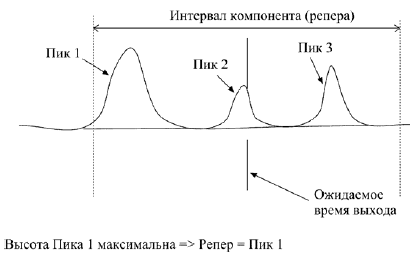
Рис. Б.11. Нахождение пика на интервале реперного компонента
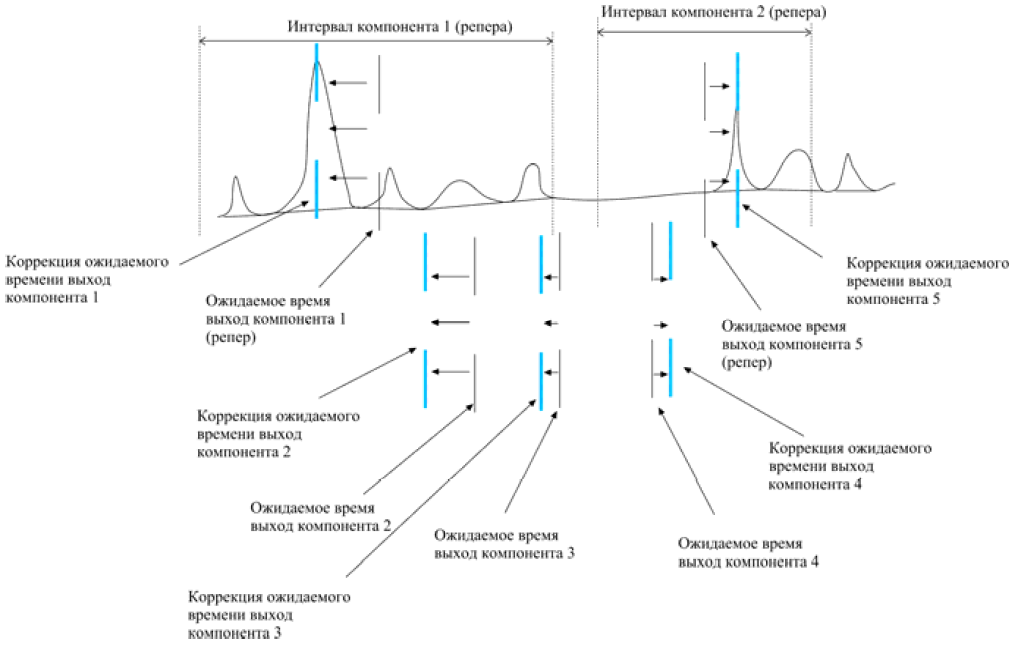
Рис.Б.12. Корректировка ожидаемых времен выхода по реперным пикам
Для каждого реперного пика определяется отклонение ожидаемого времени выхода репера от реального времени. Все ожидаемые времена выхода обычных пиков корректируются на величину, определенную по линейному закону от коррекции левого и правого реперного пика. При этом корректировка времени выхода не записывается в таблицу идентификации (в отличие от функции «Корректировка по времени»).
Далее идентификация осуществляется обычным путем, т. е. для обычных пиков находятся пики на интервале компонента (для скорректированного ожидаемого времени выхода).
Алгоритм расчета флуктуационных шумов.
Для расчета уровня флуктуационных шумов используются формулы, приведенные в ГОСТ 26703:
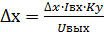 и
и 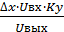 ,
,
где Iвх = 400 мА. Значение входного тока усилителя, соответствующее верхнему пределу используемого поддиапазона измерений усилителя, А.
Uвых = 2.5 В. Значение выходного напряжения усилителя, соответствующее верхнему пределу используемого поддиапазона измерений усилителя, В.
Uвх = 50 В. Значение входного напряжения усилителя, соответствующее верхнему пределу используемого поддиапазона измерений усилителя, В.
Ку = 1. Коэффициент деление выходного сигнала.
При это расчет производится по следующему алгоритму:
1. Берется 5 текущих точек.
2. Методом наименьших квадратов они аппроксимируются к прямой Y=AX+B.
3. Определяется шум как разница между прямой и действительным значением сигнала в 4-той точке.
4. Определяется дрейф как наклон аппроксимированной прямой.
5. Процедура повторяется для всей хроматограммы.
6. В качестве значения шума и дрейфа принимается максимальные значения соответствующих величин.
Алгоритм расчета статистических характеристик параметров пиков. Расчет статистических характеристик параметров пиков производится в соответствии с ГОСТ 26703.
Средние арифметические значения высоты, площади и времени выхода пика определяют по формулам:
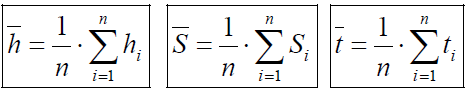
Относительное среднеквадратическое отклонение высоты (h) площади (S) и времени выхода пика (t) определяют по формулам:
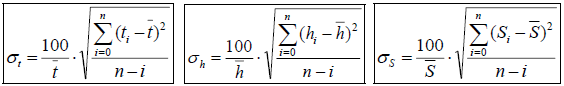
После расчета относительных среднеквадратических отклонений производится выявление анормальных хроматограмм путем сравнения значений, рассчитанных по формулам:
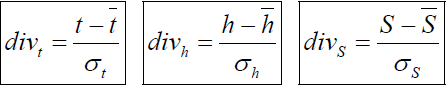
с ограничивающими значениями согласно ГОСТ 11.002 – 73, значения которых приведены в таблице Б.1:
Таблица Б1
Дата добавления: 2016-01-03; просмотров: 1814;