Принципы конвейеризации
Как уже отмечалось, основным подходом к увеличению быстродействия системы является принцип параллельной обработки. Он может быть реализован двумя способами:
a) во времени или конвейеризацией, при которой происходит совмещение разных вычислительных операций над одними и теми же данными;
b) в пространстве или собственно параллелизмом — совмещением во времени однотипных операций, выполняемых над разными блоками данных.
Конвейеризация в компьютере основана на разделении выполняемой функции на элементарные составляющие, для выполнения каждой из которых выделяется аппаратный блок — ступень.
Представим программу как некоторую функцию y=F(x). Ее декомпозиция может быть выражена так:
y=F(x)=fn(fn-1(…(f1(x)))).
Для каждой fk аргумент — результат вычислений fk-1. Программа может быть выполнена конвейерной схемой рис. 14. В ней аппаратные блоки (ступени) вычисляют значения функций fk. Фиксаторы служат для согласования времени работы ступеней.
Р и с. 14. Схема конвейера
f1 . . . fn – ступени, Ф1… Фn – регистры-фиксаторы
Условия эффективной работы конвейера:
a) время выполнения каждой подфункции должно быть приблизительно одинаковым,
b) каждая подфункция реализуется своей ступенью,
c) отсутствие обратных связей передачи данных в конвейере.
Определим среднее время выполнения команды в таком конвейере. Пусть общее время выполнения одной исходной команды равно T0. Через n тактов конвейер будет заполнен, и в каждом следующем такте будет выдаваться результат с периодом T0/n.
Пусть n — число ступеней конвейера; длительности выполнения микрокоманд в каждой ступени равны ti, i= 1, 2, …. , n; и K – число команд в последовательности. Число тактов для последовательности из K команд равно
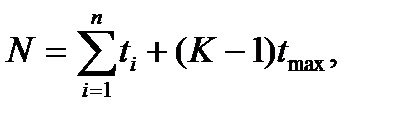
где 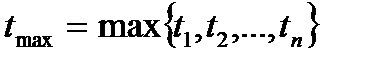 - время выполнения наиболее медленной ступени.
- время выполнения наиболее медленной ступени.
Среднее время выполнения K команд в конвейере
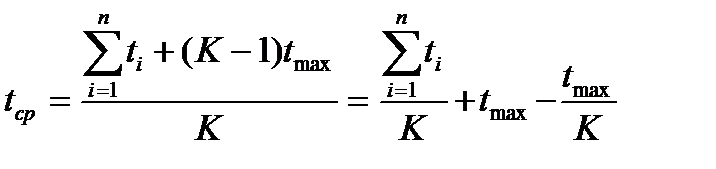
и при K 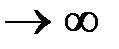 имеем
имеем 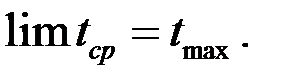
Следовательно, скорость конвейера определяется самой длинной ступенью, где бы она ни располагалась. Если длительности всех ступеней одинаковы и равны одному такту, то в пределе (при бесконечном количестве команд в программе) конвейер будет выполнять одну команду за такт.
Время заполнения или загрузки конвейера сказывается на производительности тем меньше, чем больше команд обрабатывается им. Любая остановка конвейера приводит к затратам времени на его повторное заполнение.
Причины неплановых остановок конвейера называются конфликтами. Таким образом, при конвейерной обработке возникают конфликты, когда очередная команда не может быть обработана в предназначенном ей такте. Типы конфликтов:
a) структурные,
b) по данным,
c) по управлению.
Первые вызваны недостаточностью ресурсов вычислительной системы для обеспечения и обработки возможных комбинаций команд. Их причинами могут быть:
· недостаточность конвейерных функциональных устройств системы;
· недостаточное дублирование ресурсов системы;
· кэш-промахи, которые будут рассмотрены позднее;
· общий конвейер для команд и данных.
Конфликт по данным возникает при использовании одной командой результата выполнения другой. В этом случае приходится приостанавливать конвейер и ждать, пока не появится результат. Таким образом возникает «пузырь» (buble) в конвейере. Для исключения рассматриваемых конфликтов изменяют последовательность команд с помощью вставки между связанными логически независимой операции. Такой подход в литературе называют спекулятивным выполнением команд программы. Обычно после окончания программы исходный порядок команд восстанавливают в выходном буфере.
Конфликты по управлению связаны с изменением линейной последовательности команд, вызванным командами безусловного и условного перехода. При этом может оказаться, что часть команд в начале конвейера загружена в него напрасно, и конвейер необходимо очистить, что приводит к дополнительным задержкам. Для сокращения этих задержек используется буфер адресов переходов BTB (Branch Target Buffer), представленный на рис. 15. Он представляет собой ассоциативную кэш-память небольшого объема. В строках BTB хранятся исполнительные адреса точек переходов нескольких последних команд, для которых переход имел место.
Р и с. 15. Буфер BTB
В качестве тегов используются адреса самих команд. В качестве ассоциативного признака берется адрес текущей команды из счетчика команд. Поиск в BTB производится уже на этапе выборки команд из кэш-памяти. При совпадении тега и признака адрес перехода не вычисляется, а берется из соответствующей строки BTB. Если команда в BTB не обнаружена, то она обрабатывается стандартным образом. Если затем выясняется, что это – команда перехода, то полученный исполнительный адрес перехода заносится в BTB.
Наибольший эффект использования BTB достигается при выполнении циклов - при многократном переходе в одну и туже точку.
При выполнении команд условного перехода IF(L) возникает дополнительная сложность. Требуется несколько тактов, чтобы вычислить логическое условие L и целевой адрес перехода при выполнении этого условия. Возникает вопрос: какую ветвь B1 или B2 программы (рис. 16) загружать в конвейер сразу после загрузки команды IF.
Если не угадать с выбором, то конвейер придется перезагружать.
Основные способы сокращения простоев конвейера:
· Использование буферов предвыборки;
· Задержка (задержанные переходы);
· Предсказание (прогноз) переходов.
Первый связан с аппаратной реализацией параллельных буферов выборки для двух ветвей команды IF. Его недостаток: при поступлении на конвейер новой команды IF до конца обработки предыдущей приходится организовывать дополнительный конвейерный поток.
Р и с. 16. Схема алгоритма
выполнения команды условного перехода
Наиболее эффективным является предсказание переходов. Различают статическое и динамическое предсказание.
Статическое предсказание переходов.
Этот способ использует априорную информацию о программе. Предсказание делается либо на этапе компиляции, либо в процессоре при ее выполнении.
Существует 4 стратегии статического предсказания переходов.
1. Переход происходит всегда.
2. Переход не происходит никогда.
3. Предсказание определяется кодом операции команды перехода.
4. Предсказание определяется направлением перехода (вперед или назад по программе).
Динамическое предсказание переходов
Решение о наиболее вероятном исходе условной команды принимается процессором в ходе выполнения программы по истории переходов за предыдущий отрезок времени (по содержимому ВТВ). Если в таблице данная команда IF отсутствует, то в конвейер загружают команды, следующие за ней. Затем команда IF заносится в ВТВ с адресом, по которому выполнен переход. В дальнейшем именно этот участок программы будет загружаться в конвейер при появлении команды IF.
2. Типы архитектур центральных процессоров
Мы уже отмечали, что при оптимальной загрузке конвейера он позволяет выполнить в пределе одну команду за такт. Стремление повысить производительность процессора привело к включению в его состав нескольких конвейеров. Если их n штук, то при оптимальной загрузке можно выполнить n команд за такт, т.е. повысить производительность в n раз. Оптимальность загрузки зависит от наличия конвейерных конфликтов и способов их устранения.
Существует два основных типа архитектур центральных процессоров:
a) С очень длинным командным словом (VLIW) и
b) Суперскалярная.
Они различаются способом ликвидации конфликтов в конвейерных устройствах. В первых коллизии устраняются компилятором, а во вторых –динамически, при выполнении программы.
Оптимизирующий компилятор может построить код, в котором не будет конфликтов по данным и структурных. При этом количество одновременно выполняемых команд будет равно числу конвейеров, т.е. можно считать, что в процессоре выполняется одна очень длинная команда. Именно такой подход используется во VLIW-процессорах. Они имеют очень простую структуру и высокое быстродействие. Недостатком таких процессоров является то, что исполняемый код программы зависит от структуры устройства (от числа конвейеров). Для новой модели процессора программу нужно перекомпилировать. Разработчики обычно не поставляют исходный текст программы, что ограничивает применение VLIW-процессоров областью научных исследований.
В суперскалярных процессорах используются все рассмотренные ранее способы устранения конфликтов. Они реализуются динамически. С ростом числа конвейеров увеличивается сложность устройства управления (УУ) ими, а также задержки в УУ. Считается, что максимальное количество конвейеров равно 10, а число ступеней в них – 20. Фирма АМД утверждает, что оптимальным является 10 ступеней (при большем числе увеличиваются потери из-за неправильного предсказания переходов). Основным достоинством суперскалярных процессоров является независимость исполняемого кода программы от их структуры и возможность его выполнения на любой модели процессора. Это достоинство определило преимущественное распространение суперскалярных процессоров.
В последнее время много пишут о процессорах с явным параллелизмом команд (EPIC - Explicitly Parallel Instruction Computing), в которых сочетаются достоинства обеих архитектур. Эта идея реализована в процессорах семейства Itanium.
Рассмотрим структуры современных процессоров ведущих фирм.
Лекция 6
3. Суперскалярные процессоры
Рассмотрим особенности суперскалярной архитектуры на примере процессора Pentium Pro (рис. 167
В этом процессоре реализованы следующие основные решения:
· двухпотоковая суперскалярная организация, допускающая параллельное выполнение двух простых команд;
· наличие двух независимых двухвходовых множественно-ассоциативных кэш-памятей для команд и для данных;
· динамическое прогнозирование условных переходов;
· конвейерная организация (восемь ступеней) устройства с плавающей точкой;
· двоичная совместимость с процессорами младших моделей.
Р и с. 17. Процессор Pentium Pro
Блоки в процессоре выполняют следующие функции.
1. Блок выборки команд извлекает команды из кэш-памяти команд, хранит очередь выбранных команд и обрабатывает команды условного перехода.
2. Блок декодирования расшифровывает коды команд и преобразует их в последовательности микрокоманд.
3. Блоки диспетчеризации и распределения управляют потоком команд. Табло определяет порядок выдачи команд на свободные функциональные блоки (ФБ).
4. Блок возврата восстанавливает естественную последовательность команд и подготавливает полученные результаты для ожидающих их команд.
Каждый из блоков процессора в свою очередь, как правило, построен в виде конвейера. Рассмотрим эти блоки подробнее.
3.1 Выборка и декодирование команд
В процессоре Pentium Pro используется 7-ми ступенчатый конвейер (рис. 18).
В ступень IFU0 из кэш-памяти L1 команд загружаются целые 32 –байтовые строки. Регистр Next IP содержит адрес следующей команды. При этом выбирается либо команда, следующая по порядку в программе, либо команда по целевому адресу перехода.
В ступени IFU1 анализируется поток команд и определяется начало каждой команды. Архитектура процессора (IA-32) относится к типу CISC, поэтому команды имеют разную длину. В этой ступени может анализироваться до 30 команд.
В ступени IFU2 команды выравниваются для облегчения декодирования. В процессе декодирования команда превращается в последовательность микрокоманд. В ступени ID0 имеются три внутренних декодера. Два из них, D0 и D1, предназначены для простых команд, а третий, D2 – для любых.
Очередь микрокоманд выстраивается в ступени ID1. Здесь же происходит первичное статическое прогнозирование переходов. Для уточнения прогноза затем используется динамическое прогнозирование по схеме Смита с 4 битами предыстории.
Ступень RAT (Register Alias Table) – распределитель регистров, производит переименование логических регистров для исключения конфликтов по данным.
Регистры, использованные в команде, могут быть заменены любыми из 40 временных регистров, представленных в буфере ROB (ReOrder Buffer). Здесь же собираются операнды для команд. Микрокоманда становится доступной для выполнения в функциональных блоках, когда готовы все ее операнды.
3.2 Диспетчеризация и выполнение команд
Очереди команд часто рассредоточиваются по самостоятельным буферам в станции - резервуаре. Каждый буфер связан со своим функциональным блоком (ФБ). Блок диспетчеризации хранит список свободных функциональных блоков, который называется табло. В каждом цикле блок диспетчеризации извлекает команды из своей очереди, считывает из памяти или из регистров операнды этих команд, а затем по данным табло помещает готовые команды в очередь распределения к функциональному блоку по соответствующему порту.
Р и с. 18. Конвейер выборки и декодирования
В резервуаре образуется очередь до 20 микроопераций, ожидающих доступа к ФБ. Из него за один цикл можно выпустить 5 микроопераций. Если в очереди к одному ФБ находится несколько операций, то запускается важнейшая из них. Например, операция условного перехода имеет приоритет перед арифметическими.
Блок загрузки обеспечивает считывание данных из кэш-памяти данных. Блок сохранения выдает результаты операций в эту кэш-память.
Когда операция выполнена, она переходит обратно в резервуар, а оттуда в буфер ROB, где ожидает возврата, т.е. завершения команды. Из-за неупорядоченной выдачи и неупорядоченного исполнения команд могут возникнуть конфликты. Для возврата к естественной последовательности команд служит блок возврата, который называется буфером восстановления последовательности (БВП).
3.3 Особенности процессора Pentium 4
В процессоре Pentium IV использована архитектура Net Burst, включающая ряд новых технологий.
1. Гиперконвейерная обработка – 20 ступеней конвейера.
2. Ядро быстрого выполнения, работающее на удвоенной частоте процессора.
3. Кэш-память трасс.
4. Улучшенное предсказание переходов с ВТВ объемом 4096 строк.
5. Новый набор из 144 мультимедийных команд SSE2.
6. Интегрированная кэш-память второго уровня 256, 512 или 1024 КВ.
7. Расширенное до 126 табло команд .
8. Новая системная шина Quad Pampe FSB с шириной 64 бита, передающая за один такт генератора процессора 4 пакета данных.
В процессоре отсутствует первичный кэш команд. Вместо него используется кэш-память трасс (последовательностей микрокоманд). Трассы выполняемых команд формируются на основании механизма предсказаний переходов. После выполнения трасса сохраняется в кэше и при следующем обращении готова к передаче сразу в функциональные блоки.
3.4. Мультитредовая обработка и гипертредовая технология
Мультитредовые технологии (Multithreading) обработки данных можно отнести к макроконвейерам. Они построены с учетом особенностей взаимодействие аппаратных средств и программного обеспечения. Это позволяет наиболее полно использовать возможности аппаратуры, адаптируя их к рабочей нагрузке системы.
Суперскалярный процессор имеет один счетчик команд и является однотредовым (однопотоковым). Для организации параллельно выполняемых тредов в мультитредовом процессоре используется n процессорных элементов (ПЭ) со своими счетчиками команд и регистровыми файлами. Каждый такой файл, в свою очередь, обслуживает свой вычислительный процесс – тред. Такой подход позволяет сократить разрыв между временем доступа к оперативной памяти и быстродействием центрального процессора. Параллельные треды формируются компилятором из разных программ или из отдельных ветвей одной программы.
Основной особенностью мультитредовых архитектур является введение множества устройств выборки команд. Каждое устройство организует свое окно исполнения для одного треда. Все традиционные действия (переименование регистров, предсказание переходов и др.) выполняются для каждого треда отдельно.
Особенностями процессоров мультитредовых архитектур являются:
· большая емкость памяти внутри кристалла;
· большое количество АЛУ;
· наличие блоков мультимедийной обработки;
· интеграция на кристалле функций управления памятью и периферийными устройствами;
· реализация сетевых и телекоммуникационных интерфейсов на кристалле, что обеспечивает соединение процессоров в комплексы и сети.
При невозможности выполнения команды, относящейся к одному треду, происходит переключение на другой счетчик команд и регистровый файл, и процессор переходит к другому треду, выполняя другой контекст. Таким образом, общее количество команд, находящихся в обработке, значительно превышает размер окна команд в суперскалярном процессоре.
Структура мультитредовой системы представлена на рис. 19.
Программа разбивается на совокупность сегментов, каждому из которых соответствует свой тред. Сегмент представляет собой непрерывную область последовательности команд, например, базисный блок или его часть, множество базисных блоков, одиночную итерацию, полный цикл, обращение к функции и др. Для их обслуживания строится граф управляющих зависимостей (ГУЗ), в котором вершинами являются сегменты, а дугами задается порядок выполнения сегментов.
Р и с. 19. Мультитредовая система
Динамика выполнения программы определяется обходом ее графа. На каждом шаге обхода мультитредовый процессор задает один сегмент на свободный процессорный элемент ПЭ для выполнения треда, а затем продолжает обход ГУЗ дальше. Значения регистров, разделяемых процессорными элементами, копируются в каждый из них. Результаты модификации регистров динамически направляются множеству параллельных ПЭ.
Существует два вида мультитредовой обработки.
1. Обработка без блокирования.
Выполнение треда не может быть начато, пока не получены все необходимые для него данные. Будучи запущенным, тред выполняется без остановки.
2. Обработка с блокированием.
Запуск треда производится до получения всех операндов. Когда требуется отсутствующий операнд, тред приостанавливается (блокируется). Процессор запоминает всю информацию о состоянии и загружает на выполнение другой тред.
В мультитредовых системах компилятор выполняет самый сложный процесс: предварительный анализ программы и выборку тредов.
Мультитредовая архитектура является следующим шагом после скалярной. Она позволяет динамически организовывать параллельное выполнение программы при полном использовании результатов статического распараллеливания.
Достоинства мультитредовой технологии.
1. Эффективная загрузка большого количества функциональных устройств.
2. Преодоление разрыва между скоростью выполнения регистровых команд и команд обращения к ОП.
3. Уменьшение времени обслуживания прерываний за счет выделения отдельного треда для программы обработки прерываний.
4. Большая глубина и точность предсказания переходов в программе.
Примером мультитредовых систем являются системы на основе микропроцессоров Alpha.
Идея мультитредовой обработки использована в процессоре Pentium 4 в виде гиперпотоковой технологии (Hyper Threading или HT Technology).
Гиперпотоковая обработка призвана обеспечить максимальную загрузку конвейерных функциональных блоков процессора. Выполняемая программа разбивается на два параллельных потока, состоящих из тредов. Задача компилятора и ОС заключается в формировании тредов из последовательности независимых команд.
Отличие HT технологии от мультитредовой в том, что она не использует два физических процессора. Операционная система, поддерживающая гиперпотоковую обработку, воспринимает один физический процессор как два логических и организует подачу на них двух независимых потоков команд.
В процессоре Pentium 4 эмулируется работа двух логических процессоров. Они конкурируют за ресурсы единственного вычислительного ядра. В результате повышается степень использования аппаратных блоков процессора.
Гиперпотоковая технология под названием SMT (Simultaneous Multi-Threading) использована также в многоядерных процессорах Intel Core i7 архитектуры Nehalem.
3.5. Процессоры фирмы AMD
Фирма AMD – постоянный конкурент фирмы Intel. Процессоры AMD ориентированы на систему команд х86, используемую в процессорах Intel. В то же время некоторые архитектурные решения у AMD отличаются.
Рассмотрим процессор К5. Он использует архитектуру RISC 86. Команды х86 у Intel имеют переменную длину и сложную структуру. Фирма AMD пошла по пути преобразования длинных CISC – команд в несколько небольших RISC – подобных компонент, так называемых ROP (RISC-Operation). На рис. 20 показана общая структура К5.
Р и с. 20. Архитектура процессора К5
ALU – арифметико-логическое устройство;
FPU – блок обработки команд с плавающей точкой
Основные особенности процессора К5.
1. Шесть конвейерных функциональных блоков, работающих параллельно.
2. Кэш команд – 16 КВ, кэш данных – 8 КВ.
3. Изменение последовательности выполнения команд, но не переупорядочивание.
Следующим был разработан процессор К6 также основанный на архитектуре RISC 86. Он включал 7 конвейерных функциональных блоков. Буфер планировщика содержит 24 операции RISC 86.
В процессоре К6-II использована суперскалярная обработка ММХ-команд и технология 3DNow! Это 21 команда типа SIMD, работающих с данными в формате с плавающей точкой. Отметим, что ММХ – команды работают с целыми данными. Технология 3DNow! повышает возможности графических акселераторов на ранних стадиях графического конвейера. Эта технология эффективна на следующих приложениях:
· трехмерные игры;
· мультимедийные энциклопедии;
· трехмерный звук;
· DVD – фильмы;
· CAD/CAM для проектирования.
Следующее поколение – процессор К7 Athlon использует архитектуру QuantiSpeed:
· суперскалярное суперконвейерное выполнение команд;
· аппаратная предвыборка команд в кэш-память;
· улучшенная технология предсказания переходов.
Процессор содержит 9 функциональных конвейерных блоков: 3 IEU– для целочисленных данных (по 10 ступеней в конвейере), 3 AGU - для вычисления адреса, 3 FPU– для данных с плавающей точкой и мультимедийных данных (по 15 ступеней в конвейере). Буфер планировщика содержит 24 операции RISC 86. Набор 3DNow! дополнен еще 24 командами Enhanced 3DNow! Кэш команд – 64 КВ, кэш данных - 64 КВ, кэш второго уровня 512 КВ расположен вне ядра, но на том же картридже.
Выпускаются следующие версии процессоров:
1. Athlon XP - ядро Palomino. Ориентирован на Windows XP. Набор 3DNow! Professional из 107 команд плюс поддержка SSE2.
2. Athlon MP – для серверов и мощных рабочих станций.
3.6. Архитектура IA-64
Архитектура IA-32 была революционным достижением конца 20 века. В настоящее время ее возможности для сложных и крупных задач исчерпаны. Это связано с ограничением адресного пространства в 4 ГБ и необходимостью производить точные вычисления с 64 –разрядными данными.
Существует два принципиально разных подхода к дальнейшему развитию.
1. Дополнить набор команд х86 расширением на 64-битовую арифметику.
2. Разработать принципиально новую архитектуру под 64-битовую арифметику.
Первый подход развивает фирма AMD, разработавшая систему команд х86-64 и архитектуру процессоров, аппаратно совместимых с командами х86.
Второй подход использует фирма Intel, которая разработала концепцию EPIC и архитектуру процессоров IA-64. В этой архитектуре используется встроенный декодер для 32-битных приложений, что снижает производительность.
С 2001 года фирма Intel выпускает процессоры Itanium, а затем процессоры Itanium-2, выполненные по концепции EPIC. Структура процессора Itanium представлена на рис. 21.
Р и с. 21. Структура процессора Itanium
TLB – буфер ассоциативной трансляции; IU&MMX – конвейеры целочисленных и мультимедийных операций; FPU – конвейер операций с плавающей точкой; BU – блок условных переходов; B – порты команд переходов; M – порты команд обращения к памяти; I – порты целочисленных команд; F – порты команд с плавающей точкой; РОН- регистры общего назначения; РПЗ – регистры данных с плавающей запятой; РП – регистры предикатов
1. Организация кэш-памяти.
Кэш данных L1 - 4-х канальный множественно-ассоциативный 16 КВ со строкой 32 байта. Имеет 2 порта и выполняет одновременно две операции «загрузка регистра/запись в память». Алгоритм сквозной записи.
Кэш команд L1 - 4-х канальный однопортовый множественно-ассоциативный 16 КВ со строкой 32 байта. Алгоритм сквозной записи.
Кэш L2 – 6-ти канальный 2- портовый множественно-ассоциативный 96 КВ со строкой 64 байта. Алгоритм обратной записи.
Загрузка операндов с плавающей точкой всегда начинается с кэша L2 второго уровня в обход кэша L1.
Кэш L3 – внешний 4-х канальный множественно-ассоциативный 4МВ со строкой 64 байта.
Когерентность кэш-памяти второго и третьего уровня обеспечивает протокол MESI.
2. Буферы TLB (Translation Look-aside Buffer) для быстрой переадресации из виртуальных адресов в физические являются полностью ассоциативными кэшами. Буфер TLB команд содержит 64 строки, TLB данных - 96 строк.
3. Команды 4 –х типов:
a) M – обращение к памяти
b) I - целочисленные
c) F –с плавающей точкой
d) B – команды перехода.
Им соответствуют четыре группы портов. Процессор обрабатывает 6 команд за такт, т.е. 2 связки по 3 команды.
4. Предсказание переходов производится с помощью таблиц BPT (Branch Predication Table) и MBPT (Multiway BPT). Обе таблицы представляют собой 4-х канальные множественно-ассоциативные кэш-памяти с 4-х разрядным полем предыстории переходов.
Таблица BPT содержит 512 строк для простых переходов, MBPT – 64 строки для переходов с несколькими ветвлениями.
5. Файл регистров общего назначения РОН содержит 128 64-битных регистра и имеет 8 портов чтения и 6 портов записи. Поддерживает две М-операции и две I- операции за один такт. Каждый РОН имеет дополнительный бит достоверности NaT.
Файл регистров с плавающей точкой РПЗ содержит 128 82-битных регистра и имеет 8 портов чтения и 4 порта записи. Поддерживает две М-операции и две FMAC- операции (умножить и сложить) за один такт.
Файл РП содержит 64 одноразрядных регистра и имеет 15 портов чтения и 11 портов записи.
6. Конвейерные функциональные устройства.
BU – устройства обработки переходов,
IU&MMX– целочисленные и мультимедийные устройства,
FPU - устройства для операций с плавающей точкой.
Процессоры Itanium-2 предназначены, в основном, для мощных серверных систем и кластеров. Они работают под управлением ОС HP-UX, Linux, Windows Server 2003.
Компания Intel планирует выпустить процессоры с кодовым обозначением Tukwila для серверов и рабочих станций, которые станут первыми четырёхядерными представителями линейки Itanium. Кроме того, чипы нового поколения установят своеобразный рекорд, так как станут первыми микропроцессорами в отрасли, объединяющими около двух миллиардов транзисторов.
Процессор имеет кэши ядер по 30 МВ, системную шину QPI, Multi-Threading технологию и встроенный двухпотоковый контроллер основной памяти.
Следует помнить, что Intel 64 и IA-64 это совершенно разные, несовместимые друг с другом, микропроцессорные архитектуры. Представители Intel 64 - это Pentium 4 (последние модели), ряд моделей Celeron D, семейство Core 2 и некоторые модели Intel Atom. Представители IA-64 - это процессоры Itanium и Itanium 2.
Лекция 7
Дата добавления: 2015-12-29; просмотров: 3711;