Организация и характеристики многопроцессорных вычислительных комплексов
13.1. Классификация и архитектура многопроцессорных вычислительных комплексов
Как было отмечено в разделе 1, к многопроцессорным вычислительным комплексам(МВК) будем относить многопроцессорные вычислительные машины (МВМ), часто именуемые «мультипроцессорами», и многомашинные вычислительные системы (ММВС) сосредоточенного типа, а также гибридные схемы МВМ и ММВС.
МВМ с общей памятью, разделяемой всеми процессорами (относительно независимыми друг от друга), строятся по двум основным архитектурным схемам, реализующим соответствующий характер доступа процессоров к общей памяти. Первая из рассматриваемых архитектур МВМ носит название SMP-архитектуры (Symmetric MultiProcessing – симметричная мультипроцессорная). Такие МВМ также относят к классу UMA-мультипроцессоров (Uniform Memory Access – однородный доступ к памяти). Существенным является то, что в UMA-мультипроцессорах каждое слово может быть считано из памяти теоретически с одинаковой скоростью. Вторую из рассматриваемых архитектур МВМ называют ASMP-архитектурой (ASymmetric MultiProcessing – асимметричная мультипроцессорная), но чаще для обозначения таких МВМ применяется термин NUMA-мультипроцессоры (NonUniform Memory Access – неоднородный доступ к памяти).
В основе простейшего схемного решения SMP-архитектуры лежит идея общей шины (рис. 13.1). В такой схеме несколько центральных процессоров (ЦП) и общая память (которая может быть представлена как совокупность нескольких модулей памяти – МП) одновременно используют одну и ту же шину для общения друг с другом. Когда какому-либо процессору необходимо прочитать слово в памяти, он сначала проверяет, свободна ли шина. Если шина свободна, процессор выставляет на нее адрес нужного ему слова, подает управляющие сигналы и ожидает, пока память не выставит нужное слово на шину. Если шина занята, то процессор просто ждет ее освобождения. При небольшом числе процессоров (например, двух или трех) состязание за шину управляемо. При количестве процессоров, исчисляемом несколькими десятками, шина будет перегружена и для каждого отдельного процессора почти все время занята. Именно пропускная способность шины является главной проблемой такой схемы.
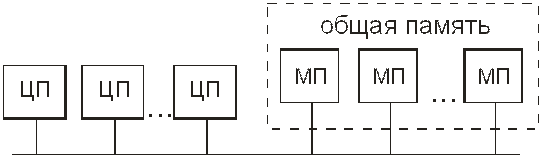
Рис. 13.1. Структурная схема многопроцессорной вычислительной
машины с SMP-архитектурой на базе общей шины
Другое более эффективное схемное решение SMP-архитектуры заключается в использовании так называемых перекрестно-координатных коммутаторов(или коммутаторов типа crossbar – «перекрестные полосы») для соединения процессоров и модулей памяти (рис. 13.2). Перекрестно-координатный коммутатор может быть замкнут или разомкнут в зависимости от того, какой из ЦП должен быть соединен с тем или другим МП. Схема с перекрестно-координатными коммутаторами представляет собой неблокирующую сеть, то есть ни один из ЦП не получает отказа в соединении по причине занятости какого-либо коммутатора (при условии, что сам требующийся МП свободен). Основным недостатком такой схемы является то, что число коммутаторов растет пропорционально квадрату числа ЦП, и при значительном числе ЦП схемное решение становится технически трудно реализуемым.
Эффективное схемное решение UMA-мультипроцессоров при большом числе ЦП реализуется на базе так называемых многоступенчатых коммутаторных сетей. В простейшей из таких сетей – баньян-сети (от названия индийского дерева «баньян») – используются так называемые «баньяновые» коммутаторы с двумя входами и двумя выходами (рис. 13.3.). Сообщения, поступающие по любой из входных линий, могут переключаться на любую выходную линию. Таким образом, любой из ЦП получает доступ к любому из требуемых МП.
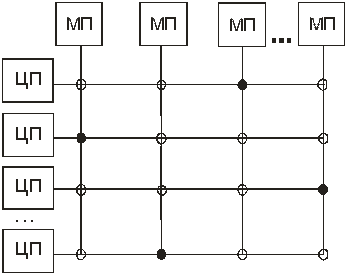
 Рис.13.2. Структурная схема многопроцессорной вычислительной машины с SMP-архитектурой на базе координатных переключателей (коммутаторов): – разомкнутые переключатели ( )
Рис.13.2. Структурная схема многопроцессорной вычислительной машины с SMP-архитектурой на базе координатных переключателей (коммутаторов): – разомкнутые переключатели ( )
 – замкнутые переключатели ( )
– замкнутые переключатели ( )
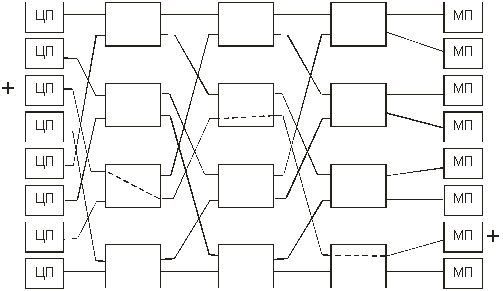
Рис.13.3. Структурная схема многопроцессорной вычислительной
машины с SMP-архитектурой на базе коммутируемой сети
В NUMA-мультипроцессорах каждый из ЦП имеет «свою», непосредственно связанную с ним память (локальную память), обращения к которой происходят наиболее часто и с самой высокой скоростью обмена информацией. Кроме того, каждый из ЦП имеет доступ и к любой локальной памяти других процессоров, однако к этим модулям памяти у данного ЦП нет непосредственной связи, а доступ осуществляется через соответствующий процессор (см. рис. 13.4). Поэтому скорость обмена информацией с удаленной («чужой») локальной памятью у каждого из ЦП гораздо ниже, чем со «своей» (этим и объясняется наименовании таких МВМ как мультипроцессоров с неоднородным доступом к памяти). В дополнение к локальным модулям памяти в NUMA-мультипроцессорах может иметься и общая память, к которой все ЦП имеют равноправный однородный доступ.
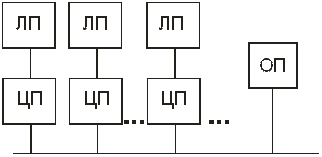
Рис.13.4. Структурная схема многопроцессорной вычислительной
машины с неоднородным доступом к памяти и шинной архитектурой
ЛП – локальная память, ОП – общая память
Для разгрузки шинного интерфейса и возможности вследствие этого существенного увеличения числа ЦП применяются комбинированные схемы NUMA-мультипроцессоров с иерархическим расположением шин. Например, в представленной на рис. 13.5 двухуровневой схеме, NUMA-мультипроцессор состоит из нескольких МВМ, имеющих SMP-архитектуру, локальные шины которых связаны общей шиной. Возможны более сложные схемные комбинации построения NUMA-мультипроцессоров с разными вариантами SMP-архитектур и с большим числом уровней шин.
В NUMA-мультипроцессорах также находят применение схемы с непосредственной связью процессоров (при небольшом их числе) и схемы с кольцевой последовательной связью процессоров (рис. 13.6, 13.7).
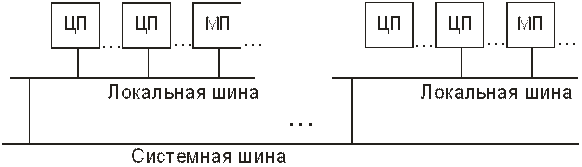
Рис.13.5. Структурная схема многопроцессорной вычислительной
машины с неоднородным доступом к памяти и двумя уровнями шин
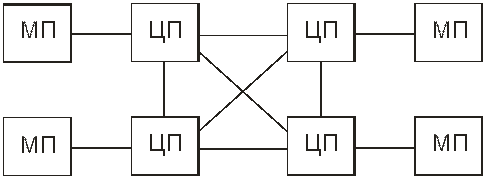
Рис. 13.6. Структурная схема многопроцессорной вычислительной машиныс неоднородным доступом к памяти и непосредственной
связью процессоров
Многомашинные вычислительные системы сосредоточенного типа (см. подраздел 1.2) относят к классу MPP-архитектуры (Massive Parallel Processing – «массово-параллельные системы» или «массивно-параллельные системы»). Переход от архитектуры SMP к MPP позволил практически бесконечно масштабировать систему машин. Такой путь оказался технически и экономически более эффективным, чем увеличение числа процессоров в архитектурах SMP и ASMP. Изначально ММВС с MPP-архитектурой строились как уникальные узко специализированные системы, в которых независимые специализированные вычислительные модули объединялись специализированными каналами связи, причем те и другие создавались под конкретную реализацию системы и ни в каких других целях фактически не могли быть использованы. Такое положение дел привело к появлению идеи так называемой кластеризацииММВС.
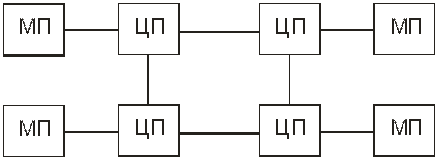
Рис. 13.7 Структурная схема многопроцессорной вычислительной
машины с неоднородным доступом к памяти и кольцевой последовательной связью процессоров
Кластерная ММВС или просто кластер (от claster – гроздь, пучок) представляет собой многопроцессорный вычислительный комплекс, который построен на базе стандартных вычислительных модулей, соединенных высокоскоростной коммуникационно-коммутационной средой (ККС). Основная идея создания кластерных систем заключается в использовании достаточно развитых и эффективных методов и технологий локальных вычислительных сетей (распределенных систем!) применительно к MPP-системам. Кластеризация получила свое практическое воплощение в середине 1990-х годов, когда благодаря оснащению компьютеров высокоскоростной шиной PCI и появлению относительно дешевой, но быстродействующей сетевой технологии Fast Ethernet, стало реальным построение кластеров, не уступающих по своим коммуникационным характеристикам специализированным MPP-системам того времени. Это означало, что высокопроизводительную MPP-систему можно было создать из стандартных серийно выпускаемых компьютеров и серийных коммуникационных программно-аппаратных средств, причем такая система может обходиться дешевле специализированных MPP-систем в сотни раз. Родственность локальных сетей и кластерных систем иногда прослеживается и в терминологии: встречается наименование кластерных систем (систем сосредоточенного типа) как COWS (Clusters of WorkStations – «гроздья рабочих станций»), а вычислительных сетей (систем распределенного типа) – как NOWS (Network of WorkStations– «сети рабочих станций»).
Современная кластерная система состоит из вычислительных модулей (ВМод) на базе стандартных аппаратных компонентов (процессоров, модулей памяти), соединенных высокоскоростной ККС, а также, как правило, вспомогательной и управляющей сетями (рис. 13.8).
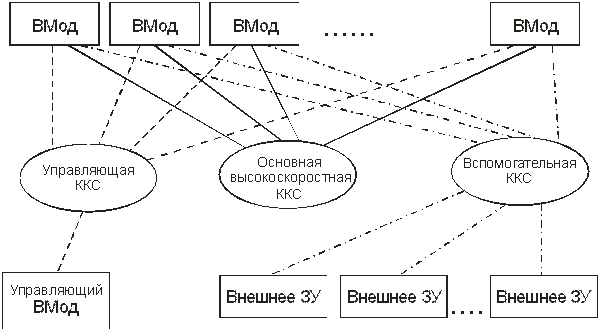
Рис.13.8. Структурная схема кластерной конфигурации многомашинных вычислительных систем
В качестве элементарных вычислительных модулей кластера могут использоваться как однопроцессорные ВМ, так и архитектуры типа SMP (чаще – двухпроцессорные), ASMP или МРР. Желательным является то, чтобы каждый модуль мог в состоянии функционировать самостоятельно и отдельно от кластера. Состав и производительность вычислительных модулей могут быть разными в рамках одного кластера, однако чаще строятся однородные кластеры. С помощью вспомогательной сети обычно решается задача эффективного доступа модулей к данным (например, к массиву внешних дисковых ЗУ). Управляющая сеть отвечает за распределение задач между модулями кластера и управление параллельно протекающими процессами. Она также используется для сетевой загрузки операционных систем модулей и управления модулями на уровне операционной системы, в том числе мониторинга температурного режима и других параметров работы модулей.
Показательными характеристиками кластерных систем являются наращиваемая масштабируемость (кластер строится так, что его можно наращивать постепенно путем добавления новых модулей), абсолютная масштабируемость (возможность создания структур, практически неограниченных по числу модулей), высокий коэффициент готовности (отказ одного или нескольких модулей кластера не приводит к потере его работоспособности, поскольку каждый из модулей является самостоятельной машиной или системой), экономное соотношение цена/производительность (кластер компонуется из стандартных серийно выпускаемых, а поэтому относительно дешевых компонентов).
Модули ММВС могут составлять различные по топологии схемы взаимного соединения. Простейшими вариантами таких схем являются классические звездообразные и кольцевые топологии. Небольшие системы часто строятся по звездообразной схеме с использованием центрального коммутатора. Альтернативная схема представляет собой кольцо, в котором каждый узел соединяется с двумя соседними узлами без помощи коммутаторов. Более сложным вариантом является двумерная топология, представляющая собой решетку или сеть. Такая схема обладает высокой степенью регулярности и легко масштабируется до достаточно больших размеров. Самый длинный путь между двумя узлами называют диаметром решетки. Диаметр решетки увеличивается пропорционально квадратному корню от общего числа узлов решетки. Один из вариантов топологии решетки, у которой крайние узлы соединены друг с другом, называется «двойным тором». Такая схема обладает большей устойчивостью к повреждениям и сбоям, чем простая решетка, к тому же дополнительные линии связи снижают ее диаметр. Регулярную трехмерную топологию представляет собой топология «куб». Из двух трехмерных кубов с помощью соединений соответствующих узлов может быть построен четырехмерный куб. Дальнейшее развитие этой идеи позволяет создавать пятимерные кубы, шестимерные кубы и т. д. Созданный таким образом N-мерный куб называется «гиперкубом». Подобная топология используется во многих многомашинных системах, реализующих параллельные вычисления. Это связано с тем, что диаметр в таких системах растет линейно в зависимости от размерности, в результате чего схема обладает низкими временными задержками. Платой за небольшой диаметр гиперкуба является большое число ответвлений на каждом узле, пропорциональное размерности гиперкуба, и, таким образом, значительное количество связей между узлами и, соответственно, их повышенная суммарная стоимость.
13.2. Организация коммуникационных сред
Выбор коммуникационной среды (так называемого интерконнекта), обеспечивающей основную информационную связь между вычислительными элементами МВК, определяется многими факторами: особенностями решаемых задач, требуемой производительностью вычислений, экономическими соображениями, вопросами масштабируемости и т.п. Наиболее доступными и компромисными типами коммуникационной среды являются сети на основе технологий Fast Ethernet и Gigabit Ethernet. Высокоскоростное сетевое соединение Gigabit Ethernet обеспечивает пропускную способность на уровне наиболее распространенного и производительного протокола передачи сообщений, применяемого в МВК, –интерфейса MPI (Message-Passing Interfase – интерфейс передачи сообщений) – около 70 Мбайт/с и задержку (промежуток времени между отправкой и получением пакета данных) примерно 50 мкс. Такие характеристики вполне приемлемы при решении задач, не требующих интенсивных обменов данными (например, визуализация трехмерных сцен или обработка геофизических данных). Однако для решения более сложных задач, особенно расчета процессов в реальном режиме времени, этих значений параметров быстродействия обмена данными становится не достаточно. В таких случаях находят применение специально разработанные для МВК технологии интерконнекта SCI, Myrinet, QsNet, InfiniBand и др.
Коммуникационная среда SCI (Scalable Coherent Interface – масштабируемый когерентный интерфейс) обеспечивает построение масштабируемой коммуникационной среды для объединения процессоров и модулей памяти, создания распределенной сети рабочих станций, организации ввода/вывода суперкомпьютеров и высокопроизводительных серверов.
Каждый отдельный вычислительный модуль МВК (обычно называемый узлом), соединяемый с другими узлами коммуникационной средой на базе SCI, имеет входной и выходной каналы (соединения, для наименования которых используется достаточно распространенный в профессиональной среде термин – «линк»). Узлы связаны однонаправленными каналами «точка-точка» либо с соседним узлом, либо подключены к коммутатору. При объединении узлов должна обязательно формироваться циклическая магистраль (кольцо) из узлов, соединенных каналами «точка-точка» между входным и выходным каналами каждого узла. Один узел в кольце, называемый «чистильщик» (scrubber), выполняет функции инициализации узлов кольца с установлением адресов, управления таймерами, уничтожения пакетов, которые не нашли адресата. Этот узел помечает проходящие через него пакеты и уничтожает уже помеченные пакеты. В кольце может быть только один чистильщик. Возможно построение многокольцевых систем, связанных через агентов. Агент-коммутатор или агент-мост обеспечивают соединение между разными кольцами или между кольцом и коммутационной средой с другим протоколом, например, шинами PCI. Посредством SCI могут быть реализованы различные структуры межсоединений.
Возможности, функционально эквивалентные тем, что предоставляются при взаимодействии устройств на шине, реализуются путем образования однонаправленной магистрали между узлами, состоящей из цепочки соединений «точка-точка» между узлами и коммутаторами межузловых соединений. Однонаправленность передач в SCI имеет принципиальный характер, так как исключает переключение выходных ножек микросхем с передачи на прием и обратно. Такое переключение создает большие электрические помехи. Таким образом, вместо физической шины используется множество парных соединений, обеспечивающих высокую скорость передачи. Вследствие этого преодолеваются, во-первых, фундаментальное ограничение шин – одна передача в каждый промежуток времени предоставления шины передающему устройству, а, во-вторых, ограничения, связанные со скоростью распространения сигналов по проводникам (в случае асинхронных шин такое ограничение обусловлено временем передачи сигналов «запрос-подтверждение», а в случае синхронных шин – разницей между временем распространения тактового сигнала от его генератора и временем распространения данных от передающего устройства).
Связи между узлами SCI реализуются как 18 пар проводов, несущих дифференциальные электрические сигналы с передачей информации по переднему и заднему фронту на частоте 250 МГц. SCI использует 16-битную магистраль данных, а также одну сигнальную линию для передачи тактового сигнала и еще одну сигнальную линию для передачи флагового бита. Информационный обмен между узлами SCI, реализуемый посредством транзакций, включает помимо обычных для шинных структур транзакций «чтения» и «записи» средства синхронизации: замки (lock), поддержку когерентности строк кэш-памяти и основной памяти, передачу сообщений и сигналов прерываний. Все транзакции пересылают SCI пакеты между узлом-источником и узлом-получателем. Транзакции предусматривают передачу пакетов с блоками данных фиксированной длины 64 и 256 байтов, а также переменной длины 1–16 байтов. Форматы транзакций не зависят от топологии. Фиксированная длина пакетов упрощает логику и увеличивает быстродействие интерфейсных схем.
В SCI реализуется 64-разрядная архитектура с 64-битным адресным пространством. Старшие 16 битов задают адрес узла и используются для маршрутизации SCI пакетов между узлами системы. Остальные 48 битов – адресация внутренней памяти узла. SCI ориентирован на поддержку строк размером 64 байта. Другие размеры строк автоматически поддерживаются в многоуровневых блоках кэш-памяти.
Узлы SCI должны отсылать сформированные в них пакеты, возможно, с одновременным приемом других пакетов, адресованных узлу, и пропуском через узел транзитных пакетов. Для транзитных пакетов, прибывающих во время передачи узлом собственного пакета, предусмотрена проходная очередь. При дисциплине, когда собственный пакет не передается до тех пор, пока есть транзитные, необходимая длина проходной очереди определяется длиной передаваемых узлами пакетов. Размер проходной очереди должен быть достаточен для приема пакетов без переполнения. В узле вводятся также входная и выходная очереди для пакетов, соответственно, принимаемых и передаваемых узлом.
Узел SCI принимает поток данных и передает другой поток данных. Эти потоки состоят из SCI пакетов и свободных (пустых) символов. Через каналы непрерывно передаются либо символы пакетов, либо свободные символы, которые заполняют интервалы между пакетами. В случае, если передавать нечего и проходная очередь узла пуста, он передает на выход свободный символ.
Интерконнект SCI обеспечивает пропускную способность на уровне MPI от 200 до 325 Мбайт/с и задержку менее 3 мкс.
Первое поколение коммуникационной среды Myrinetбыло разработано фирмой Myricom в 1994 году. В настоящее время актуально третье поколение этого интерконнекта – Myrinet 2000.
Среда Myrinet стандартизует формат пакета, способ адресации ВМ, набор управляющих символов протокола передачи пакетов. Коммуникационная среда образуется адаптерами «шина компьютера – линк сети» и коммутаторами линков сети. Каждый линк содержит пару однонаправленных каналов, образуя дуплексный канал. Стандарт Myrinet предусматривает два основных типа коммуникационных сред: SAN (System-Area Network – системная сеть) и LAN (Local-Area Network – локальная сеть). Эти среды различаются протоколами физического уровня. Среда SAN, предназначенная для объединения плат внутри стойки, имеет общее заземление и использует для передачи однофазные сигналы. В отличие от SAN среда LAN применяется для объединения ВМ, разнесенных в пространстве, например, по стойкам, расположенным на разных этажах здания. Среда LAN использует для передачи данных парафазные сигналы.
Линк коммуникационной среды SAN состоит из 20 проводников, по десять для образования каждого из противоположно направленных каналов. Канал имеет 8 линий для передачи байта данных, одну линию для передачи специального сигнала D «данные/управление» (D = 1 – данные, D = 0 – управление), одну линию, направленную противоположно предыдущим девяти, для передачи специального сигнала В блокирования передачи от приемника (B = 1 – STOP, B = 0 – GO). Получатель функционирует асинхронно и может принять символ, когда тот появится.
Линк коммуникационной среды LAN состоит из 18 витых пар проводников, по девять для образования каждого из противоположно направленных каналов. Канал имеет следующие линии: 8 линий для передачи байта данных, одну линию для передачи специального сигнала D «данные/управление» (D = 1 – данные, D = 0 – управление). Передача сигналов парафазная.
Коммуникационная среда Myrinet обеспечивает пропускную способность на уровне MPI до 250 Мбайт/с с задержкой 7 мкс, а в новое программное обеспечение этой среды позволяет сократить задержку в два раза.
Коммуникационная среда QsNet разрабатывалась специально для построения параллельных систем из серийных микропроцессоров. Среда QsNet формируется из адаптеров «шина РСI – линк QsNet» и коммутаторов. Между парой адаптеров может быть установлено как прямое соединение кабелем «адаптер-адаптер», так и коммутируемое через коммутаторы. Структуры систем, построенных с использованием QsNet, не отличаются от структур, созданных на базе среды Myrinet. Линк QsNet – 2 противоположно направленных канала, каждый шириной по 10 бит.
QsNet – достаточно производительное и дорогое оборудование, обеспечивающее пропускную способность до 900 Мбайт/с и задержку менее 2 мкс.
На сегодняшний день наиболее перспективна технология коммуникационной среды InfiniBand. Архитектура InfiniBand предлагается как комплексное решение многих проблем: увеличения пропускной способности интерфейса ввода-вывода высокопроизводительных ВМ серверов, создания эффективных универсальных коммуникационных сред для МВК, локальных и глобальных сетей. Эта архитектура вобрала в себя множество апробированных идей, часть из которых использована в выше рассмотренных технологиях коммуникационных сред. Однако именно комплексность и новизна служат источником больших затрат на пути практического использования архитектуры InfiniBand.
InfiniBand представляет собой архитектуру сетей SAN для объединения в систему множества независимых узлов – процессорных платформ, платформ ввода-вывода и устройств ввода-вывода. InfiniBand может использоваться как в небольших системах с одним процессором и несколькими устройствами ввода-вывода, так и в массово-параллельных системах с сотнями процессоров и тысячами устройств ввода-вывода. На основе InfiniBand создается коммуникационная среда, позволяющая многим устройствам устанавливать одновременные соединения с высокой пропускной способностью и малой задержкой при безопасном удаленном управлении. Устройства могут взаимодействовать через множество портов, а также использовать совокупность различных путей через коммуникационную среду, что позволяет повысить отказоустойчивость и пропускную способность. Архитектура InfiniBand описывает передачу данных и управляющую инфраструктуру как для поддержки операций ввода-вывода, так и для межпроцессорных коммуникаций. Межсетевой протокол входит составной частью в InfiniBand, что позволяет применять его как мост между системами с InfiniBand и вычислительными сетями или удаленными ВМ.
Важнейшими компонентами сетей InfiniBand являются так называемые канальные адаптеры. Канальный адаптер служит устройством, которое соединяет узел с коммуникационной средой. Канальный адаптер для процессорного узла называется процессорным адаптером, а для узла ввода-вывода – исполнительным адаптером. При коммуникации между узлами канальные адаптеры создают пакеты из сформированных в узлах сообщений. Пакеты служат информационным блоком, передаваемым через коммуникационную среду. Коммутаторы и маршрутизаторы только продвигают пакет между узлами от узла-источника до узла-получателя. Канальный адаптер узла-получателя собирает сообщения из поступивших пакетов и передает эти сообщения в память узла-получателя.
Каждый адаптер имеет уникальный глобальный идентификатор, присваиваемый производителем адаптера. Адаптер может иметь несколько портов для подсоединения линков коммуникационной среды. Каждый порт также имеет глобальный идентификатор, присваиваемый производителем. При инициализации сети InfiniBand менеджером подсети каждому порту адаптера приписывается локальный идентификатор или диапазон локальных идентификаторов.
Текущая реализация InfiniBand имеетпропускную способность на уровне MPI до 1900 Мбайт/с и время задержки от 3 до 7 мкс. Компанией PathScale разработан высокоскоростной адаптер, который реализует стандартные коммутаторы и кабельную структуру InfiniBand, используя собственный транспортный протокол. Это позволило снизить время задержки до величины 1,3 мкс.
13.3. Способы организации коммутации
Для формирования коммуникационно-коммутационных сред используются различные типы коммутационного оборудования. Коммутаторы МВК подразделяют на простые коммутаторы и составные коммутаторы, компонуемые из простых. Простые коммутаторы имеют малую задержку при установлении полнодоступных соединений, но в силу физических ограничений могут быть построены только для систем с малым числом вычислительных модулей. Составные коммутаторы с большим числом входов и выходов строятся путем объединения простых коммутаторов в разнообразные многокаскадные схемы с линиями связи типа «точка-точка». Способы такого объединения зависят от требований, предъявляемых к коммутатору как к элементу вычислительной системы.
Простые коммутаторы могут быть двух типов:с временным и пространственным разделением.
Простые коммутаторысвременным разделением называют также шинами или шинными структурами. Их особенность заключается в использовании общей информационной магистрали для передачи данных между устройствами, подключенными к шине. Как правило, шины состоят только из пассивных элементов, и все управление передачами выполняется передающим и принимающим устройствами. Так как между разными устройствами возникает состязание за пользование общим ресурсом, то необходимо управление предоставлением шины передающему устройству. Вопросы управления и разрешения конфликтов в шинных структурах рассмотрены ранее в разделе 5.
Шина как среда распространения сигналов может быть реализована не только совокупностью проводников, но и памятью. В этом случае входной порт коммутатора помещает данные либо в соответствующий ему входной буфер для дальнейшего их извлечения выходным портом, которому эти данные предназначены, либо входной порт сразу размещает данные в соответствующем буфере выходного порта. При использовании памяти арбитраж в коммутаторе выполняется на уровне доступа к элементам входных и выходных буферов.
Локальные сети, например Ethernet и Token Ring с протоколами, использующими общую среду распространения сигналов, также служат коммутаторами с временным разделением и реализуют логический протокол шинной структуры.
Хотя шина может быть достаточно надежной и требовать небольшого объема оборудования для своей реализации, она является критическим ресурсом, способным вызвать отказ всей системы. Шинным структурам присущ ряд фундаментальных ограничений. Во-первых, как бы ни была высока скорость передачи по шине, требуется время на выполнение арбитража, и при увеличении числа подключаемых к шине устройств возрастает сложность схемы арбитра. Кроме того, время арбитража также увеличивается при увеличении числа подключенных к шине устройств. При частых предоставлениях шины для использования разными устройствами время арбитража существенно ограничивает пропускную способность. Во-вторых, в каждый момент времени шина используется для передачи данных только одним устройством, что становится узким местом в системах со многими устройствами. В-третьих, пропускная способность шины ограничивается шириной шины и тактовой частотой работы шины. К серьезным проблемам приводят и физические ограничения, связанные с отражением сигналов и изменением нагрузки при изменении числа устройств.
В целом, на пропускную способность шинной структуры оказывают влияние число активных (способных передавать данные) устройств, алгоритм арбитража, способ управления (централизованный или распределенный), ширина шины, механизм обработки сбоев и отказов, способ синхронизации передачи данных по шине и возникающие задержки (из-за необходимости реализации механизма «запрос-ответ» при асинхронной передаче или из-за обеспечения надежного стробирования тактовым сигналом передающего и принимающего устройств при синхронной передаче).
Простые коммутаторыс пространственным разделениемспособны соединить любой вход с любым одним выходом (ординарные) или подмножеством выходов (неординарные). Простейшим примером такого коммутатора является перекрестно-координатный коммутатор, представленный на рис. 13.2.
В общем случае коммутатор с пространственным разделением представляет собой совокупность мультиплексоров, число которых равно количеству выходов коммутатора. Количество входов коммутатора может быть произвольным. Каждый вход должен быть заведен на все мультиплексоры коммутатора.
Основными достоинствами коммутаторов с пространственным разделением являются полнодоступность и минимальные задержки, а недостатками – высокая сложность порядка n х m (где n – число входов, m – число выходов), ограничения по количеству выходов коммутатора (связаны с возможностями размножения входов для подсоединения к каждому мультиплексору). Отметим, что для реализации шины нужен только один мультиплексор. Его выход подсоединяется к входам всех устройств, подключенных к шине. Устройство управления шины обеспечивает возможность только одному устройству подавать данные на соответствующий вход мультиплексора.
Итак, простые коммутаторы, как с временным, так и пространственным разделением, имеют ограничения по числу входов и выходов, а коммутаторы с пространственным разделением, кроме того, требуют для своего построения большого объема оборудования.
Составные коммутаторы с большим числом входов и выходов строятся из совокупности коммутаторов с меньшим числом входов и выходов путем объединения этих коммутаторов линиями «точка-точка», что снижает требования к размножению входов. Объем оборудования составного коммутатора меньше, чем у прямоугольного коммутатора с теми же количествами входов и выходов. Однако эти коммутаторы имеют задержку, пропорциональную числу каскадов (числу простых коммутаторов, которые сигнал проходит от входа до выхода составного коммутатора).
Как правило, составные коммутаторы строятся из простых коммутаторов 2 x 2 с двумя входами и двумя выходами. Эти коммутаторы имеют два состояния: прямое пропускание с соответствующих входов на выходы и перекрестное пропускание. Отметим, что если используется коммутатор с временным разделением, то коммутации входов с соответствующими выходами разносятся во времени.
Подчеркнем два важных свойства коммутаторов 2 x 2:
1) если два входа хотят соединиться с одним выходом, то коммутатор разрешает конфликт и связывает только один вход с этим выходом, блокируя или отвергая второе соединение;
2) коммутаторы могут иметь или не иметь внутреннюю буферизацию, что связано с эффективностью строящихся составных коммутаторов.
Аналогично простым коммутаторам 2 x 2 могут быть построены простые коммутаторы m х n с m входами и n выходами.
Составной коммутатор создается путем объединения совокупности простых коммутаторов m х n , входы которых либо являются входами составного коммутатора, либо подключены к выходам одного или разных других простых коммутаторов этой совокупности. Соответственно оставшиеся при таком объединении свободными выходы простых коммутаторов служат выходами составного коммутатора. Структура такого составного коммутатора задается ориентированным графом, каждая вершина которого имеет m входящих ребер и n выходящих. Установление соединений входов с выходами называется коммутацией. Для установления коммутации требуется подать управляющие числа на каждый вход каждого из простых коммутаторов, образующих составной.
Составные коммутаторы могут быть:
1) полнодоступными и частично доступными (неполнодоступными);
2) неблокируемыми, блокируемыми и неблокируемыми с перекоммутацией;
3) ординарными и неординарными.
Коммутатор называется полнодоступным, если может быть установлено соединение любого входа с любым его выходом. Если любой вход не может быть соединен, по крайней мере, с одним выходом, то коммутатор является неполнодоступным.
Коммутатор называется неблокируемым, если может быть установлено соединение свободных входа и выхода при наличии установленных соединений других входов и выходов. Если хотя бы одно такое соединение не может быть установлено, коммутатор называется блокируемым. Если для вновь соединяемых входа и выхода может быть установлено соединение путем перекоммутации уже существующих соединений с их сохранением, то такой коммутатор называется неблокируемым с перекоммутацией.
Коммутатор называется ординарным, если он соединяет только один вход с одним выходом. Если возможно установление соединения входа с произвольным подмножеством выходов, то коммутатор называется неординарным.
Составные коммутаторы с числом входов N и выходов M могут быть построены с использованием различного числа по-разному соединенных друг с другом простых коммутаторов. Используемые простые коммутаторы могут быть как одинаковыми, так и разными, то есть иметь различное число входов и выходов. Естественными требованиями к различным способам построения составных коммутаторов являются требования минимизации количества используемых простых коммутаторов; минимизации количества коммутаторов, участвующих в соединении любого входа с любым выходом (каскадность коммутатора); минимизации сложности алгоритма установления коммутаций.
Типичным представителем составных коммутаторов является так называемый коммутатор Клоза. Это полнодоступный, неблокируемый с перекоммутацией, ординарный коммутатор. Коммутатор Клоза представляет собой составной коммутатор с m х d входами и m х d выходами. Он формируется из m входных коммутаторов d х d, m выходных коммутаторов d х d и d промежуточных коммутаторов m х m. Таким образом, коммутатор Клоза состоит из трех каскадов коммутаторов: входных, промежуточных и выходных. Внутри составного коммутатора реализуются следующие виды соединений:
♦ k-й выход i-го входного коммутатора соединен с i-м входом k-го промежуточного коммутатора;
♦ k-й вход j-го выходного коммутатора соединен с j-м выходом k-ro промежуточного коммутатора.
Коммутатор Клоза способен соединять любой вход с любым выходом, однако при уже установленных соединениях части входов и выходов добавление соединения еще одного входа и выхода может потребовать переустановления всех соединений.
К достаточно распространенному типу составных коммутаторов относятся баньян-сети (пример описан в разделе 13.1 и представлен на рис.13.3). Такие коммутаторы являются полнодоступными неблокируемыми ординарными коммутатором, сконструированными так, чтобы предельно упростить сложность алгоритма установления коммутаций. Эти коммутаторы строятся на базе прямоугольных коммутаторов a х b таким образом, что существует только один путь от каждого входа к каждому выходу.
Важным подклассом баньян-сетей являются так называемые дельта-сети.Дельта-сеть формируется из коммутаторов a х b и представляет собой n-каскадный коммутатор с a в степени n входами и b в степени n выходами. Составляющие коммутаторы соединяются так, что образуется единственный путь одинаковой длины для соединения любого входа с любым выходом.
В сложных МВК происходит распределение ресурсов между задачами, каждая из которых исполняется на своем подмножестве процессоров. В связи с этим появляется понятие «близости» процессоров, которое должно выражаться в различных расстояниях (различной каскадности соединений) между ними. Более эффективный подход к построению составных коммутаторов заключается в реализации так называемых распределенных составных коммутаторов. В этом случае составной коммутатор строится из прямоугольных коммутаторов, а один из входов и один из выходов каждого составляющего коммутатора служат входом и выходом составного коммутатора. Такой способ построения составных коммутаторов предусматривает, что к каждому составляющему коммутатору подключаются процессор и память, образуя в совокупности вычислительный модуль с каналами для соединения с себе подобными модулями. Свободные входы и выходы каждого вычислительного модуля соединяются линиями связи типа «точка-точка» с входами и выходами других коммутаторов, образуя граф межмодульных связей.
С точки зрения простоты организации передач данных между вычислительными модулями наиболее подходящий граф межмодульных связей – полный. При полном графе между каждой парой модулей прокладывается линия, по которой, как по кратчайшему пути, выполняется обмен данными между ними. Возможны также одновременные обмены между произвольными подмножествами передающих и принимающих модулей.
Проблема выбора графа межмодульных связей возникает при невозможности связать линиями каждую пару вычислительных модулей. Отсутствие линий между модулями приводит к тому, что обмен данными между ними выполняется через цепочки транзитных модулей. Это требует определения трасс передачи данных, что является трудоемкой задачей теории графов. Поскольку обмен между модулями требует транзитных передач, увеличивается время выполнения и ограничивается возможность одновременного проведения различных обменов. Поэтому граф межмодульных связей должен выбираться исходя из минимизации времени выполнения межмодульных обменов и максимизации числа одновременно выполняемых обменов. Важный аспект в проблему выбора графа межмодульных связей вносит учет отказов и восстановлений вычислительных модулей и линий связи.
13.4. Примеры практической реализации
многопроцессорных вычислительных комплексов
Компания SGI (Silicon Graphics Intercomparated) представляет многопроцессорные SMP-компьютеры моделей PowerChallenge XL на базе суперскалярных процессоров MIPS R8000. В этих моделях устанавливается от 1 до 18 процессоров, объем адресуемой оперативной памяти достигает 16 Гбайт, объем дисковой памяти – 6,3 Тбайт. Пиковая производительность составляет от 0,36 до 6,5 GFlops, производительность системы ввода/вывода – до 1,2 Гбайт/с. Компания SGI также предлагает кластеры PowerChallenge Earray, которые могут содержать до 8 SMP-компьютеров PowerChallenge XL. Такие кластеры содержат до 144 процессоров, объем адресуемой оперативной памяти достигает 128 Гбайт, объем дисковой памяти – до 63 Тбайт, пиковая производительность составляет 52 GFlops, производительность системы ввода/вывода – до 4 Гбайт/с.
Еще один модельный ряд МВК от компании SGI – серия кластерных систем SGI Altix 3000. Эти системы основаны на архитектуре глобальной разделяемой памяти SGI NUMAflex, которая является реализацией архитектуры неоднородного доступа к памяти (NUMA). Дизайн NUMAflex позволяет помещать процессор, память, систему ввода/вывода, соединительные кабели, графическую подсистему в модульные компоненты, называемые блоками. Эти блоки могут комбинироваться и конфигурироваться с большой гибкостью, чтобы удовлетворять потребности клиента в ресурсах и рабочей нагрузке. Система SGI Altix 3000 построена на основе традиционных блоков ввода/вывода, хранения данных и соединительных компонентов (маршрутизирующие блоки). Процессорный блок реализован на базе процессоров Intel Itanium 2. Модели SGI Altix 3000 могут содержать до 64 процессоров.
Ключевой особенностью системы SGI Altix 3000 является использование каскадируемых коммутаторов в маршрутизирующих элементах. Каскадируемые коммутаторы обеспечивают системе малое время задержки, которое критично для машин, использующих архитектуру неоднородного доступа к памяти (так как память в NUMA-архитектуре распределяется между узлами, а не сосредоточена в одном месте). Каскадируемые коммутаторы используют каталогизируемую схему памяти для отслеживания данных, находящихся в разных модулях кэш-памяти, в результате чего сравнительно меньшие объемы данных пересылаются между частями памяти, что способствует снижению задержек по сравнению с традиционными системами, основанными на шинах.
Компанией Sun Microsystems разработана серия масштабируемых серверов Sun Ultra Enterprise. Эта серия включает группы серверов рабочих групп Sun Enterprise 10s, 250, 220R, 450 и 420R, группы серверов отделов предприятий Sun Enterprise 3500 и 4500, группы серверов масштаба предприятия Sun Enterprise 5500, 6500 и 10000. Двухпроцессорный SMP-сервер масштаба рабочей группы Sun Enterprise 250 базируется на процессорах UltraSPARC. В составе сервера Sun Enterprise 450 работают до четырех процессоров UltraSPARC, имеется возможность подключения внешних накопителей общей емкостью до 6 Тбайт. В серверах Sun Enterprise 4500 и 5500 возможна установка до 14 процессоров. Основная память расширяется от 256 Мбайт до 14 Гбайт. Поддерживается более 6 Тбайт внешней памяти. В сервере Sun Enterprise 6500 количество процессоров может изменяться от 1 до 30, основная память масштабируется от 256 Мбайт до 30 Гбайт, поддерживается более 10 Тбайт внешней памяти. Общая архитектура семейства серверов Sun Enterprise 3500 – 6500 позволяет производить локальное наращивание вычислительных возможностей путем подключения до 30 процессоров. Сервер Enterprise 10000 поддерживает до 64 процессоров UltraSPARC и до 64 Гбайт разделяемой памяти, ширина пропускания внутрисистемной магистрали достигает 12 Гбайт/с, обеспечивается поддержка до 20 Тбайт дискового пространства.
Компанией IBM в 2001 году разработан масштабируемый кластер 1350, состоящий из серверов (модулей) IBM xSeries, объединенных соответствующими коммуникационными сетями и системами управления. Схема такого кластера (или суперкластера) представляет собой несколько логических слоев, и уровень сложности возрастает при увеличении размера системы. Хотя число модулей, необходимых для решения задачи, относительно легко оценивается для любого приложения, в действительности требуемое число модулей оказывается больше из-за необходимости иметь сервисные узлы, обслуживающие инфраструктуру кластера. Так, для каждых 32-64 модулей, в зависимости от компоновки, необходим центральный управляющий модуль (узел) с соответствующей конфигурацией.
Стандартным вычислительным модулем для кластера 1350 является IBM xSeries 335 на основе одного или двух процессоров Intel Pentium Хеоn. В качестве узла управления в кластере 1350 используется сервер xSeries 345, также основанный на процессорах Хеоn. В качестве межпроцессорного соединения используются технологии Fast Ethernet, Gigabit Ethernet и Myrinet 2000. В последнем случае пропускная способность канала составляет около 200 Мбайт/с в каждом направлении со временем задержки 6-8 мкс. Число модулей кластера 1350 варьируется от 8 до 128 в зависимости от класса кластера (начальный, средний, профессиональный, высокопрофессиональный), объемы основной памяти могут составлять от 18 до 36 Гбайт.
Компания Hewlett-Packard (HP) выпускает серверы серий HP 9000 и HP Integrity. Для построения гибких масштабируемых систем эти серверы могут объединяться в кластеры. Узлы кластера, каждый из которых представляет собой самостоятельный сервер (со своими процессорами и оперативной памятью), работающий под управлением своей операционной системы, соединяются при помощи коммуникационных сред и специальных протоколов связи. и системные процессы. В состав кластера, помимо серверов, входят также массивы дисковой памяти и устройства резервного копирования. В зависимости от требуемого уровня отказоустойчивости компания HP предлагает несколько типов кластерных решений, в которых серверные узлы кластера могут быть размещены централизованно (локальный кластер), распределены по соседним зданиям (кампусный кластер), распределены по нескольким территориям в пределах одного города (метро-кластер) или представляют собой два связанных кластера, размещенных в различных городах, странах или континентах (континентальный кластер).
В моделях серии HP 9000 ранее использовались процессоры семейства PA-RISC (РА-8700, РА-8800 и РА-8900), а в последнее время осуществляется переход на использование процессоров Intel Itanium 2 с архитектурой IA64. Номенклатура серии HP 9000 насчитывает более десятка моделей – от компактных серверов rр3410-2 и rр4440-8 до суперкомпьютеров Superdome, обладающих вычислительной мощностью, достаточной для работы систем управления крупными международными корпорациями с десятками тысяч одновременно работающих пользователей.
Архитектура серверов серии HP 9000 различна – младшие модели строятся на базе архитектуры SMP в чистом виде, тогда как в старших моделях (rp7420-16, rp8420-32, Superdome) используется гибридная архитектура, сочетающая черты NUMA и SMP. Эта иерархическая модульная архитектура представляет собой совокупность вычислительных модулей, объединенных высокоскоростными матричными координатными коммутаторами.
Модели начального уровня rр3410-2, rр3440-4, rр4410-4 и rp4440-8 представляют собой многофункциональные серверы, комплектуемые разным числом процессоров (от 1 до 8) и оперативной памятью объемом до 128 Гбайт. К моделям среднего уровня относятся 16-процессорная модель rр7420-16 и 32-процессорная модель rр8420-32. В одной стандартной стойке может быть установлено до четырех серверов rр7420-16 и до двух rр8420-32. В моделях суперкомпьютеров HP 9000 Superdome число процессоров может достигать 128, а общий объем оперативной памяти – 1 Тбайт.
Серверы HP Integrity в последнее время строятся на базе двухпроцессорных модулей HP mx2 Dual-Processor Module с процессорами Intel Itanium 2. Модели начального уровня HP Integrity rx1620-2, rx 2620-2 и rx 4640-8 оснащаются процессорами Itanium 2 с тактовыми частотами 1,3; 1,5 и 1,6 ГГц. Модель rх4640-8 включает 4 двухпроцессорных модуля mх2. Максимальный объем ОЗУ для rx1620-2 составляет 16 Гбайт, для rx2620-2 – 32 Гбайт, а для rx4640-8 – 128 Гбайт. К моделям среднего уровня серии Integrity относятся 16- и 32-процессорные серверы rx7620-16 и rx8620-32. Они строятся на процессорах Itanium 2 с тактовой частотой 1,5 ГГц (кэш L3 – 4 Мбайт) и 1,6 ГГц (кэш L3 – 6 Мбайт). Объем ОЗУ в серверах rx7620-16 может достигать 128 Гбайт, а в rx8620-32 – 256 Гбайт. В суперкомпьютерах (суперсерверах) HP Integrity Superdome число процессоров Itanium 2 (1,6 ГГц с кэшем 9 Мбайт или 1,5 ГГц с кэшем 6 Мбайт) может достигать 128, а общий объем оперативной памяти – 1 Тбайт. Для предприятий с непрерывным обслуживанием компания HP предлагает масштабируемые МВК Integrity NonStop (с количеством процессоров до 4 тысяч), готовность которых выражается числом 99,99999% (это значит, что в течение года допускается не более 5 минут простоя вычислительного комплекса).
Компания DEC, прекратив свое самостоятельное существование и войдя в состав компании Hewlett-Packard, продолжает работы по обновлению своей линии серверов AlphaServer, на основе которых строились Alpha-кластеры. В семейство AlphaServer входит четыре серии серверов: DS, ES, GS и SC. В моделях DS, ES и GS используется до 64 процессоров Alpha EV68, в серверах AlphaServer SC может быть несколько сотен процессоров (до 512 и более). Все серверы семейства построены по коммутируемой технологии, что позволяет избежать недостатков, присущих системной шине. Серверы AlphaServer нового поколения имеют высокую степень масштабируемости, позволяя строить системы с использованием всего двух типовых процессорных модулей: 2-процессорных и 8-процессорных.
Компанией Hitachi разработаны суперсерверы серии SR8000 на основе собственных высокопроизводительных 64-разрядных RISC-процессоров. Модели этой серии могут легко масштабироваться в различные эффективные кластерные конфигурации. Так кластерная конфигурация на базе 512 узлов серии SR8000 с общим объемом оперативной памяти 8192 Гбайт может достигать производительности около 7400 GFlops.
МВК серии VPP5000 компании Fujitsu может включать от 4 до 128 процессоров (и даже 512 процессоров в специальных вариантах). Каждый процессор имеет память до 16 Гбайт и непосредственно соединяется с другими процессором со скоростью передачи 1,6 Гбайт/с. Объем оперативной памяти составляет от 16 Гбайт до 2048 Тбайт (8192 Тбайт в 512-процессорной конфигурации). Теоретическая пиковая производительность – от 38,4 GFlops до 1229 GFlops (4915 GFlops в 512-процессорной конфигурации).
Современные суперкомпьютеры Cray T3E компании Cray Research представляют собой высокопроизводительные масштабируемые МВК на базе RISK-процессоров Alpha EV5. Каждый узел Cray T3E содержит один процессорный модуль, включающий процессор, память (объемом от 64 Мбайт до 2 Гбайт) и средство коммутации, которое осуществляет связь между модулями. Разделяемая глобально адресуемая подсистема памяти делает возможным обращение к локальной памяти каждого процессорного модуля. Процессорные модули в Cray ТЗЕ связаны в трехмерный тор двунаправленной высокоскоростной сетью с малым временем задержки. Каналы ввода/вывода интегрированы в трехмерную межузловую сеть и пропорциональны размеру системы. При добавлении процессорных модулей пропускная способность каналов ввода/вывода увеличивается, и масштабируемые приложения могут выполняться на системах с большим числом процессоров так же эффективно, как и на системах с меньшим числом процессоров. Комплекс Cray ТЗЕ может конфигурироваться до 2048 процессоров. Пиковая производительность составляет 2400 GFlops.
Компанией IBM в 2004 году представлена модель суперкомпьютера RS/6000 SP с 512 SMP-узлами. Каждый узел имеет 16 процессоров, а вся система в целом – 8192 процессора. Общая оперативная память составляет 6 Тбайт, а дисковую память – 160 Тбайт. При этом обеспечивается пиковая производительность не менее 12000 GFlops.
Самые мощные вычислительные комплексы входят в состав всемирной рейтинговой таблицы, именуемой Top500. Первые строки этой таблицы в 2004 году занимали следующие МВК:
1) NEC SX-8 (4096 процессоров, 64 Тбайт ОЗУ, производительность – до 65 TFlops);
2) Silicon Graphic Columbia (512 х 20 = 10240 процессоров, производительность – до 43 TFlops);
3) IBM Blue Gene/L (16000 процессоров, производительность – до 36 TFlops);
4) NEC Earth-Simulator (5120 процессоров, производительность – до 36 TFlops).
В 2005 году модель суперкомпьютера IBM Blue Gene/L, включающая 131072 процессора, достигла производительности 136 TFlops и заняла первую строку в мировом рейтинге МВК. В этом суперкомпьютере каждый элементарный вычислительный модуль включает два процессора на базе процессорных ядер PowerPC440. По два таких вычислительных модуля размещаются на так называемой мезонинной (промежуточной) плате. На материнской плате устанавливаются 16 мезонинных плат. В стойке размещаются 32 материнских платы, а весь суперкомпьютер Blue Gene/L состоит из 64 стоек и имеет в качестве графа межмодульных связей трехмерный тор 64 х 32 х 32.
Отечественные разработки МВК базируются на стандартных комплектующих ведущих мировых производителей вычислительных устройств. Многопроцессорная вычислительная система МВС-100 была разработана НИИ «Квант» в кооперации с Институтом прикладной математики Российской академии наук и других академических институтов. МВС-100 производилась в виде типовых конструктивных модулей по 32, 64 и 128 процессоров Intel Pentium II или Pentium III. На смену ей пришла система МВС-1000 на базе процессоров Alpha 21164. Модификация МВС-1000М с производительностью около 1 TFlops впервые вошла в мировой рейтинг Top500 и заняла в нем в 2004 году весьма почетное для новичка 74-е место из 500. Эта разработка достаточно показательна для понимания общих подходов к проектированию МВК, поэтому рассмотрим построение МВС-1000М (рис. 13.9) несколько подробнее.
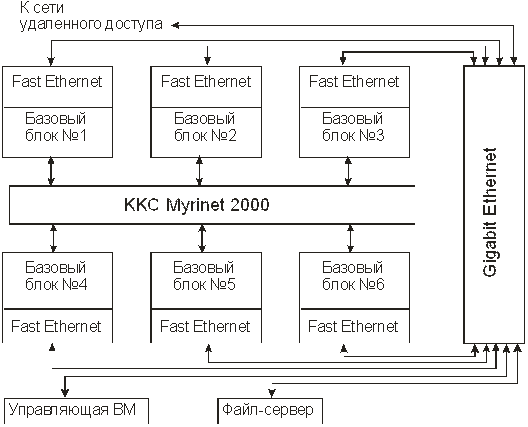
Рис. 13.9. Структурная схема многопроцессорного вычислительного комплекса МВС-1000М
МВС-1000М состоит из 6 базовых блоков, каждый из которых содержит по 64 двухпроцессорных вычислительных модуля (так называемые вычислительные модули «решающего поля»). В состав вычислительного модуля решающего поля входят 2 процессора Alpha 21264 с тактовой частотой 667 МГц и кэш-памятью второго уровня объемом 4 Мбайт, общая (разделяемая) обеими процессорами оперативная память объемом 2 Гбайт, дисковый накопитель объемом 20 Гбайт (локальная дисковая память), интерфейсная плата сети Myrinet, интерфейсная плата сети Fast Ethernet, источник питания мощностью 600 Вт. Двухпроцессорные вычислительные модули подсоединены через шины PCI к коммуникационной среде Myrinet 2000 (пропускная способность канала 2 Гбит/с) и к сети Fast Ethernet (пропускная способность канала 100 Мбит/с). Коммуникационная среда Myrinet 2000 предназначена для высокоскоростного обмена между модулями в ходе вычислений. Среда Myrinet 2000 состоит из шести 128-портовых коммутаторов, размещенных по одному в каждом базовом блоке. К каждому из коммутаторов подключено 64 вычислительных модуля соответствующего блока. Оставшиеся 64 порта каждого коммутатора блока используются для соединения коммутаторов между собой с образованием составного коммутатора. При обмене данными по типу «точка-точка» (то есть между парой двухпроцессорных модулей) с использованием интерфейса MPI достигается пропускная способность на уровне 110-150 Мбайт/с. Сеть Fast Ethernet состоит из 6 коммутаторов, каждый из которых размещен в соответствующем вычислительном блоке и подключен к вычислительному модулю этого блока. Коммутатор каждого блока подсоединен гигабитным портом к коммутатору Gigabit Ethernet, через который модули получают доступ к управляющему компьютеру и файл-серверу. Сеть Ethernet служит для начальной загрузки программ и данных в вычислительные модули, доступа модулей к внешним устройствам и файл-серверу, а также для управления и мониторинга аппаратно-программных средств в ходе вычислительного процесса. Суперкомпьютер МВС-1000М имеет систему бесперебойного электропитания с контролем параметров аппаратуры и окружающей среды. Питание вычислительных модулей и других аппаратных средств, в том числе агрегатов бесперебойного питания, автоматически отключается при достижении критичных состояний.
Другой отечественный МВК, вошедший в Top500 и занявший в рейтинге 407-е место с производительностью в 423,6 GFlops, – кластер «СКИФ К-500», построенный в 2003 году на базе 128 процессоров Intel Xeon и системной сети SCI. Следующий МВК, вошедший в Top500, – это еще один кластер «СКИФ К-1000», разработанный в рамках российско-белорусской государственной суперкомпьютерной программы «СКИФ». Этот кластер построен в 2004 году на базе 576 процессоров AMD Opteron и системной сети InfiniBand. «СКИФ К-1000» вошел в первую сотню рейтинга Top500 с производительностью 2,032 TFlops. Самый мощный отечественный кластер (на момент подготовки настоящего учебного пособия) – МВС 15000БМ с производительностью более 5,3 Tflops. Он построен из вычислительных узлов компании IBM на базе процессоров PowerPC и системной сети Myrinet. Этот кластер занимает 56-е место в Top500 и установлен в Межведомственном суперкомпьютерном центре Российской академии наук.
Резюме
Категория многопроцессорных вычислительных комплексов включает многопроцессорные вычислительные машины («мультипроцессоры») и многомашинные вычислительные системы сосредоточенного типа, а также гибридные схемы МВМ и ММВС.
МВМ с общей памятью, разделяемой всеми процессорами, строятся на основе архитектур SMP (UMA-мультипроцессоры) и ASMP (NUMA-мультипроцессоры).
ММВС сосредоточенного типа относят к классу MPP-архитектуры. Переход от архитектуры SMP к MPP позволил практически бесконечно масштабировать систему машин. Такой путь оказался технически и экономически более эффективным, чем увеличение числа процессоров в архитектурах SMP и ASMP.
Кластерная ММВС представляет собой многопроцессорный вычислительный комплекс, который построен на базе стандартных вычислительных модулей, соединенных высокоскоростной коммуникационно-коммутационной средой. В качестве элементарных вычислительных модулей кластера могут использоваться как однопроцессорные ВМ, так и архитектуры типа SMP (чаще – двухпроцессорные), ASMP или МРР.
Выбор коммуникационной среды, обеспечивающей основную информационную связь между вычислительными элементами МВК, определяется особенностями решаемых задач, требуемой производительностью вычислений, экономическими соображениями, вопросами масштабируемости и другими факторами. Наиболее доступными и отработанными типами коммуникационной среды являются сети на основе технологий Fast Ethernet и Gigabit Ethernet. Для решения сложных задач находят применение высокоскоростные специализированные технологии коммуникационных сред: SCI, Myrinet, QsNet, InfiniBand и др.
При организации МВК используются различные типы коммутационного оборудования. Коммутаторы МВК могут быть простыми и составными, компонуемыми из простых. В свою очередь простые коммутаторы могут быть коммутаторами с временным разделением и коммутаторами с пространственным разделением, а составные коммутаторы – полнодоступными и частично доступными; неблокируемыми, блокируемыми и неблокируемыми с перекоммутацией; ординарными и неординарными.
Компаниями SGI, Sun Microsystems, IBM, Hewlett-Packard, Hitachi, Fujitsu, Cray Research, NEC представлены многочисленные примеры создания эффективных МВК, достаточно широко используемых в различных практических приложениях. Отечественные разработки МВК базируются на стандартных комплектующих ведущих зарубежных производителей вычислительных устройств. Некоторые из российских разработок входят в мировой рейтинг наиболее высокопроизводительных МВК.
Контрольные вопросы и задания
1. По каким основным архитектурным схемам строятся МВМ с общей памятью, разделяемой всеми процессорами?
2. Опишите схемное решение SMP-архитектуры на основе общей шины.
3. Объясните высокую эффективность схемных решение SMP-архитектуры с использованием перекрестно-координатных коммутаторов и многоступенчатых коммутаторных сетей.
4. Какие цели преследуются при использовании комбинированных схем NUMA-мультипроцессоров с иерархическим расположением шин?
5. Охарактеризуйте многомашинные вычислительные системы, относящиеся к классу MPP-архитектуры.
6. В чем заключается принципиальная особенность построения кластерных многомашинных вычислительных систем?
7. Представьте структурную схему кластерной конфигурации многомашинной вычислительной системы.
8. Перечислите важнейшие характеристиками кластерных систем.
9. Какие топологические схемы могут составлять модули многомашинных вычислительных систем?
10. Назовите основные типы коммуникационных сред, обеспечивающих информационную связь между вычислительными элементами МВК.
11. Охарактеризуйте особенности коммуникационной среды SCI.
12. Какие значения пропускной способности обеспечиваются коммуникационной средой Myrinet?
13. В чем состоит перспективность использования в МВК технологии коммуникационной среды InfiniBand?
14. На какие типы подразделяются коммутаторы, применяемые для построения многопроцессорных вычислительных комплексов?
15. Какой тип коммутатора называется полнодоступным?
16. Чем отличаются ординарные коммутаторы от неординарных?
17. Поясните эффективность построения распределенных типов составных коммутаторов.
18. Приведите примеры практической реализации наиболее высокопроизводительных многопроцессорных вычислительных комплексов.
19. Каково состояние и перспективы разработок отечественных МВК?
Заключение
Вычислительная техника претерпела достаточно бурную и сложную эволюцию своего развития, которая начиналась с первых единичных образцов вычислительных машин, построенных на основе электронно-вакуумных ламп. К настоящему времени средства вычислительной техники представлены богатым ассортиментом современных вычислительных машин и систем, разработанных на базе полупроводниковых интегральных микросхем с высокой степенью интеграции электронных компонентов. Этот ассортимент включает массово производимые мобильные и настольные персональные компьютеры, высокопроизводительные рабочие станции, многопроцессорные и многомашинные вычислительные системы, уникальные сверхвысокопроизводительные вычислительные комплексы, а также широкий спектр периферийных, коммуникационных, коммутационных и других вспомогательных устройств. На протяжении всей истории развития вычислительных машин и систем существенно совершенствуются их архитектурные решения, повышается эффективность работы базовых функциональных элементов (особенно таких, как центральные процессоры, основные и внешние запоминающие устройства).
В процессе развития вычислительной техники проявилась тенденция связи отдельных машин между собой и построения таким образом вычислительных сетей. Эта тенденция к настоящему времени приобрела глобальный характер и привела к значительному прогрессу телекоммуникационных средств и сетевых технологий. Характерной особенностью современного этапа развития вычислительных сетей является интенсивное совершенствование не только кабельных линий связей, но и беспроводных способов передачи информации. Идея объединение нескольких компактно расположенных машин в единый вычислительный комплекс послужила предпосылкой построен
Дата добавления: 2015-12-17; просмотров: 6480;