Кэширование дисков
Очень важной, специфической формой буферизации является кэширование[2]. Этот термин означает использование сравнительно небольшой по объему, но быстродействующей памяти для того, чтобы уменьшить количество обращений к более медленной памяти большого объема.
Идея кэширования основывается на так называемой гипотезе о локальности ссылок. Эта гипотеза заключается в следующем. Если в какой-то момент времени произошло обращение к определенному участку данных, то в ближайшее время можно с высокой вероятностью ожидать повторения обращений к тем же самым данным или же к соседним участкам данных. Конечно, локальность ссылок нельзя считать законом, однако практика показывает, что эта гипотеза оправдывается для подавляющего большинства программ.
В современных вычислительных системах может использоваться несколько уровней кэширования. В данном курсе не рассматривается аппаратный кэш процессора, позволяющий сократить число обращений к основной памяти за счет использования быстродействующих регистров. К работе ОС более прямое отношение имеет программное кэширование устройств произвольного доступа (дисковых накопителей). В этом случае гипотезу о локальности ссылок можно переформулировать более конкретно: если программа выполнила чтение или запись данных из некоторого блока диска, то весьма вероятно, что в скором будущем последуют еще операции чтения или записи данных из того же блока.
В роли быстродействующей памяти (кэша) здесь выступает массив буферов, размещенный в системной памяти. Каждый буфер состоит из заголовка и блока данных, соответствующего по размеру блоку (сектору) диска. Заголовок буфера содержит адрес блока диска, копия которого в данный момент содержится в буфере, и несколько флагов, характеризующих состояние буфера.
Когда система получает запрос на чтение или запись определенного блока данных диска, она прежде всего проверяет, не содержится ли в данный момент копия этого блока в одном из буферов кэша. Для этого требуется выполнить поиск по заголовкам буферов. Если блок найден в кэше, то обращение к диску выполняться не будет. Вместо этого данные читаются из буфера или, соответственно, записываются в буфер. В случае записи данных следует также в заголовке буфера отметить с помощью специального флага, что буфер стал «грязным», т.е. его содержимое не соответствует данным на диске.
Если требуемый блок диска не найден в кэше, то для него должен быть выделен буфер. Проблема в том, что общее количество буферов кэша ограничено. Чтобы отдать один из них под требуемый блок, надо «вытеснить» из кэша один из блоков, которые там хранились. При этом, если вытесняемый блок «грязный», то он должен быть «очищен», т.е. записан на диск. При вытеснении «чистого» блока никаких операций с диском выполнять не надо.
Какой из блоков, хранящихся в кэше, следует выбрать для вытеснения, чтобы сократить общее количество обращений к диску? Это крайне важный вопрос, и если он будет решаться неправильно, то вся работа системы может затормозиться из-за постоянных обращений к диску.
Имеется теоретически оптимальное решение данной задачи, которое заключается в следующем. Число обращений к диску будет минимально, если каждый раз выбирать для вытеснения тот блок данных, к которому в будущем дольше всего не будет обращений. К сожалению, воспользоваться этим правилом на практике невозможно, так как последовательность обращений к блокам диска непредсказуема. Данный теоретический результат полезен только как недостижимый идеал, с которым можно сравнивать результаты применения более реалистичных алгоритмов выбора.
Среди алгоритмов, используемых на практике, лучшим считается алгоритм LRU (Least Recently Used, в вольном переводе «давно не использовавшийся»). Он заключается в следующем: выбирать для вытеснения следует тот блок, к которому дольше всего не было обращений. Здесь как раз используется принцип локальности ссылок: раз обращений давно не было, то, вероятно, их и не будет в ближайшее время.
Как на практике реализуется выбор блока по правилу LRU? Очевидное решение – при каждом обращении к буферу записывать в его заголовке текущее время, а при выборе для вытеснения искать самую раннюю запись – слишком громоздко и медленно. Есть гораздо лучшая возможность.
Все буферы кэша связываются в линейный список. В заголовке каждого буфера хранится ссылка на следующий по порядку списка буфер (фактически хранится индекс этого буфера в массиве буферов). При каждом обращении к блоку данных для чтения или записи выполняется также перемещение соответствующего буфера в конец списка. Это не означает перемещения данных, хранящихся в буфере, изменяются только несколько ссылок в заголовках.
В результате постоянного перемещения использованных блоков в конец списка буферов этот список оказывается отсортированным по возрастанию времени последнего обращения. В начале списка оказывается тот буфер, к данным которого дольше всего не было обращений. Он-то нам и нужен как кандидат на вытеснение.
На рис. 2‑3 показан массив буферов, связанный в список.
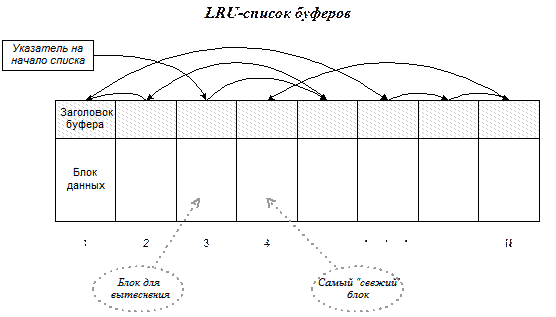
Рис. 2‑3
Теперь о «грязных» буферах. В каких случаях должна выполняться их «очистка», т.е. запись блока данных из кэш-буфера на диск? Можно назвать три таких случая.
· Выбор блока для вытеснения из кэша.
· Закрытие файла, к которому относятся «грязные» блоки. Общепринято, что при закрытии файла должно выполняться его сохранение на диске.
· Операция принудительной очистки всех буферов либо только буферов, относящихся к определенному файлу. Подобная операция может выполняться для повышения надежности хранения данных, как страховка от возможных сбоев. В ОС UNIX, например, очистка всех буферов традиционно выполняется каждые 30 с.
Следует признать, что кэширование операций записи на диск, в отличие от кэширования чтения, всегда создает определенную опасность потери данных. В случае случайного сбоя системы, отключения питания и т.п. может оказаться, что важная информация, которую следовало записать на диск, застряла в грязных буферах кэша и была поэтому потеряна.[3] Это неизбежная плата за значительное повышение производительности системы. Программы, требующие высокой надежности работы с данными (например, банковские программы), обычно записывают данные прямо на диск. При этом кэш либо не используется вообще, либо в кэш-буфер заносится копия данных, которая может пригодиться при последующих операциях чтения.
«Узким местом» кэширования дисков является поиск требуемого блока данных в кэше. Как было описано выше, для этого система просматривает заголовки буферов. Если кэш состоит из нескольких сотен буферов, время поиска будет ощутимо. Один из возможных приемов ускорения поиска, используемый в UNIX, показан на рис. 2‑4.
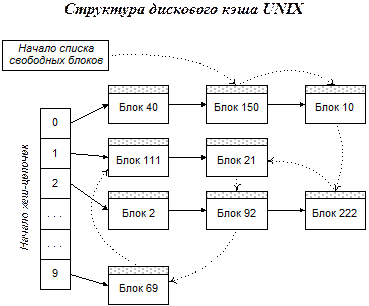
Рис. 2‑4
В UNIX каждый кэш-буфер может входить одновременно в два линейных списка. Один из них, называемый «списком свободных блоков», это знакомый нам LRU-список, используемый для определения блока, подлежащего вытеснению. Слово «свободный» не значит «пустой»; в данном случае это слово означает блок, не занятый в текущий момент в операции чтения/записи, выполняемой каким-нибудь процессом. Другой список называется «хеш-цепочкой» и используется для ускорения поиска нужного блока.
При записи в буфер данных, соответствующих некоторому блоку диска, номер хеш-цепочки, в которую будет помещен этот буфер, определяется как остаток от деления номера блока на N – количество хеш-цепочек. Для наглядности на рисунке принято значение N = 10. Таким образом, блоки с номерами 120, 40, 90 попадают в цепочку 0, блоки 91, 1, 71 – в цепочку 1 и т.д. Когда система ищет в кэше блок с определенным номером, она прежде всего по номеру блока определяет, в какой из хеш-цепочек этот блок должен находиться. Если блока нет в этой цепочке, то его вообще нет в кэше. Таким способом удается сократить поиск в лучшем случае в N раз (это если все цепочки окажутся одинаковой длины).
Перемещение буфера из одной хеш-цепочки в другую, как и его перемещение в конец списка свободных блоков, не требует перезаписи всего блока данных в памяти и выполняется путем изменения ссылок в заголовках блоков.
Еще одна особенность кэширования дисков в UNIX состоит в том, что при обнаружении в начале списка свободных блоков «грязных» буферов система запускает процессы их очистки, но не дожидается завершения этих процессов, а выбирает для вытеснения первый по списку чистый блок. После завершения очистки блоки возвращаются в начало списка свободных блоков, оставаясь первыми кандидатами на вытеснение.
Дата добавления: 2015-09-07; просмотров: 2171;