Особенности ядра со структурой Haswell
Процессоры со структурой Haswell производились по22-нанометровому техпроцессу.
Серьезных изменений в структуре ядра Haswell не произошло. Главный упор был сделан на управление энергопотреблением и масштабируемость.
Введен новый набор состояний ядра в зависимости от его текущей загрузки -S0ix. Основная идея – минимизировать энергопотребление в момент низкой активности или полного бездействия системы, например, когда пользователь просто что-то разглядывает на экране, а в фоновом режиме не выполняется никаких ресурсоемких задач. В этот момент отключаются (обесточиваются) все незадействованные модули внутри ядер. Модули включаются только по необходимости, что дает аж двадцатикратную экономию в режиме простоя, при этом сама система находится в полностью активном состоянии C0. В итоге идея с полным отключением блоков оказалась в разы эффективнее снижения напряжения и понижения частот. Аналогичным образом оптимизированы и другие состояния C0-C7.
Кроме этого, ядра еще больше "развязаны" друг от друга по частоте, что позволяет эффективнее использовать режимы Turbo, при этом оставаясь в рамках заданного теплового пакета.
Появился расширенный набор команд AVX2, возросло количество исполнительных портов. Их стало восемь, поэтому в теории пропускная способность конвейера ядра со структурой Haswell стала на треть больше. Был предпринят ряд шагов к тому, чтобы обеспечить все эти порты работой, то есть улучшить возможности ядра по параллельному выполнению команд. С этой целью были оптимизированы алгоритмы предсказания ветвлений и увеличен объём внутренних буферов: в первую очередь — окна внеочередного выполнения команд.
Расширена система команд подмножеством команд AVX2, а также существенно увеличилась скорость их выполнения. Главное достояние этого набора — FMA-команды, объединяющие сразу пару операций над числами с плавающей точкой. Благодаря этим командам теоретическая производительность ядра со структурой Haswell при операциях над числами с плавающей точкой с одинарной и двойной точностью выросла вдвое.
Также в структуре Haswell появился набор команд-расширений TSX (Transactional Synchronization Extensions), которые помогают программистам лучше управлять потоками команд и данных для более плотной загрузки многоядерных процессоров.
Оптимизирована межъядерная шина. Кроме того, вдвое увеличена пропускная способность кэш-памятей L1 и L2.В каждом такте они оперируют с вдвое большим количеством данных, хотя сами объемы кэш-памятей, а также задержки в выборке или в случае кэш-промахов остались аналогичными с предыдущим поколением.
Показатели задержек и пропускных способностей трех структур ядер приведены в таблице 31.2.
Таблица 31.2.
| Структура Sandy Bridge | Структура Ivy Bridge | Структура Haswell | |
| Задержка, такты | |||
| L1D кеш-память | |||
| L2 кеш-память | |||
| L3 кеш-память | |||
| Пропускная способность, Гбайт/с | |||
| L1D кеш-память | 510,68 | 507,64 | 980,79 |
| L2 кеш-память | 377,37 | 381,63 | 596,7 |
| L3 кеш-память | 188,5 | 193,38 | 206,12 |
Кеш-память третьего уровня L3 в структуре Haswell работает с большими задержками, чем в процессорах предыдущих поколений, так как общая часть этого процессора получила асинхронное тактирование относительно ядер. Однако увеличение задержек с лихвой компенсируется двукратным ростом полосы пропускания, произошедшим не только в теории, но и на практике.
Организация, размеры, задержки, пропускные способности кэш-памятей первого и второго уровней приведены в таблице 31.3.
Таблица 31.3.
| Характеристики | Структура Nehalem | Структура Sandy Bridge | Структура Haswell |
| Организация кэш-памяти команд первого уровня L1K | 32К байт, 4-канала | 32К байт, 8-каналов | 32К байт, 8-каналов |
| Организация кэш-памяти данных первого уровня L1D | 32К байт, 8-каналов | 32К байт, 8-каналов | 32К байт, 8-каналов |
| Задержка при обращении в кэш-память L1 | 4 такта | 4 такта | 4 такта |
| Размер блока данных, читаемых из кэш-памяти L1 | 16 байт | 32 байта | 64 байта |
| Размер блока данных, записываемых в кэш-память L1 | 16 байт | 16 байт | 32 байта |
| Организация кэш-памяти второго уровня L2 | 256К байт, 8-каналов | 256К байт, 8-каналов | 256К байт, 8-каналов |
| Задержка при чтении из кэш-памяти L2 | 10 тактов | 12 тактов | 12 тактов |
| Размер блока данных, читаемых из кэш-памяти L2 в кэш-память L1 | 32 байта | 32 байта | 64 байта |
| TLB L1K | 4К байт, 128, 4 канала, 2М/4М: 7 потоков | 4К байт, 128, 4 канала, 2М байт/4М байт: 8 потоков | 4Кбайт, 128, 4 канала, 2М байт/4М байт: 8 потоков |
| TLB L1D | 4К байт, 64, 4 канала, 2М байт/4М байт: 32, 4 канала, 1G: расщепленный | 4К байт, 64, 4 канала, 2М байт/4М байт: 32, 4 канала, 1G, 4, 4 канала | 4К, 64, 4 канала, 2М/4М: 32, 4 канала, 1G, 4, 4 канала |
| TLB L2 | 4КМ, 512, 4 канала, | 4КМ, 512, 4 канала | 4К байт+2М байт, общий, 1024, 8 каналов |
| Размер блока при обращении в оперативную память | 64 байта | 64 байта | 64 байта |
В целом структура Haswell на фоне структуры Sandy Bridge не выглядит заметным продвижением вперёд. Принципиальное преимущество наблюдается лишь при использовании набора команд AVX2. Если же эти новые команды в рассмотрение не брать, то средний уровень превосходства структуры Haswell над структурой Sandy Bridge составляет порядка 10 процентов.
Общая блок-схема ядра со структурой Haswell приведена на рис. 31.3.
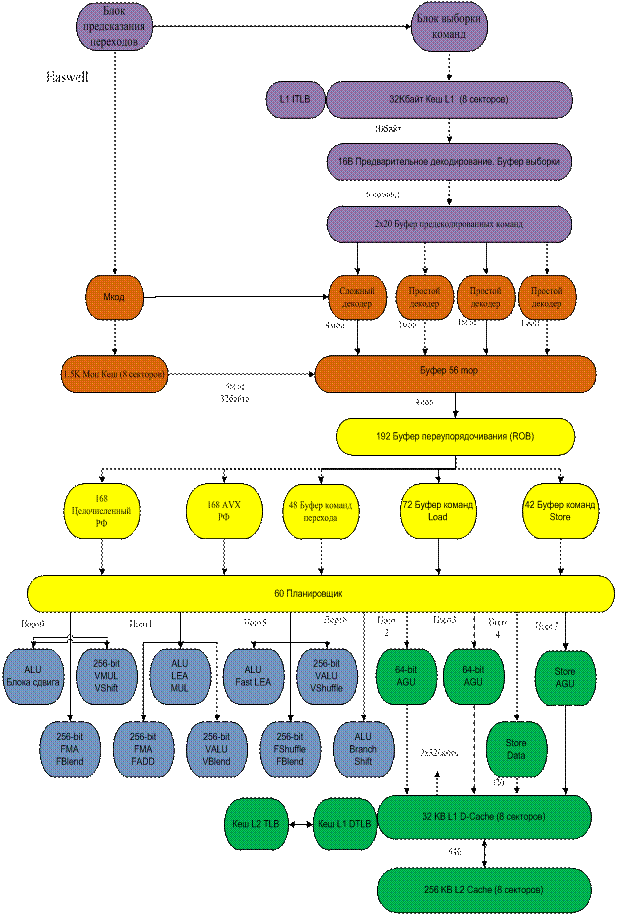
Рис. 31.3. Блок схема ядра со структурой Haswell
Контрольные вопросы
1. Назовите основные стадии конвейера команд современных универсальных процессоров.
2. Сколько уровней кэш-памяти в современных процессорах?
3. Функции кэш-памяти первого уровня?
4. Функции кэш-памяти второго уровня?
5. Функции кэш-памяти третьего уровня?
6. Почему кэш-память первого уровня разделяют на кэш-память команд и кэш-память данных?
7. Что такое предвыборка?
8. Какие различия между организацией кэш-памяти в процессорах фирм Intel и AMD?
9. Какие функции дешифратора?
10. Зачем нужно переименование регистров?
11. Почему необходим буфер для хранения выполненых команд?
12. Функции предсказателя переходов?
13. Функции планировщика выдачи команд на выполнение?
Дата добавления: 2015-09-29; просмотров: 923;