Структура подсистемы подготовки команд для выполнения
На рис. 31.2 представлена структура подсистемы подготовки команд для выполнения (фронт конвейера в англоязычной терминологии).
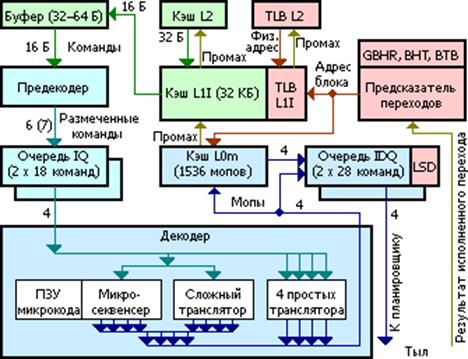
Рис. 31.2. Структура подсистемы подготовки команд для выполнения. Цвета показывают разные виды информации и обрабатывающих или хранящих её блоков.
Кеш команд L1К ядра со структурой Sandy Bridge размером 32К байт обладал восьмиканальной (8-way) ассоциативностью. После упреждающей выборки и предварительного декодирования команды подавались на декодеры, которые, в свою очередь, выдавали на выходе микрооперации фиксированной длины для дальнейшей обработки с изменением последовательности. Три из четырёх декодеров ядра обрабатывали простые команды, в результате чего каждый выдавал по одной микрооперации (МОП) на выходе, в то время как четвёртый декодер обрабатывал сложные команды и выдавал до четырёх микроопераций. Кроме того, микропрограммные команды размером более четырех микроопераций разбиваются на блоки по четыре микрооперации.
В любом случае, декодеры структуры Sandy Bridge вне зависимости от типа поступающих команд выдавали на выходе не более четырех микроопераций за такт.
Одним из наиболее важных нововведений в структуре Sandy Bridge была кеш-память декодированных микроопераций,иликеш-память команд L0m. Кеш-память декодированных микроопераций вмещала чуть более полутора тысяч микроопераций. Без особых затей она кэшировала на выходе декодеров всепредварительно декодированные микрооперации. Как только поступала на обработку новая команда, блок упреждающей выборки первым делом производил сверку с кеш-памятью L0m, и в случае обнаружения совпадений, загрузка конвейера по четыре микрооперации за такт в обход основных декодеров осуществлялась уже из кеш-памяти L0m. Незадействованные и простаивающие цепи декодеров, кстати, весьма сложные, и потому достаточно «прожорливые», в этот момент попросту отключались от питания. В противном случае, когда кеш-память декодированных операций оказывается невостребованной, продолжалась обычная работа по выборке и декодированию команд, а кеш-память декодированных операций переводилась в режим экономии энергии.
Кеш-память L0m в какой-то мере можно считать частью кеш-памяти первого уровня L1К, в которую она, кстати, интегрирована, но отдельной и очень быстрой ее частью. По некоторым данным, при работе с большинством приложений, вероятность удачного «попадания» в кеш-память декодированных микроопераций очень велика и может достигать 80%.
В блоке предсказания ветвленийбуфер предсказания результата ветвления (branch target buffer, BTB) ядра вмещал в два раза больше адресов результатов ветвления и вдвое большую историю комбинаций команд, нежели аналогичный буфер в предыдущем ядре со структурой Nehalem. Кроме того, были увеличены размеры области хранения истории ветвлений, в том числе предсказанных и выполненных. Так, удалось снизить количество неудачных предсказаний ветвлений, что положительно отразилось как на увеличении производительности за счёт уменьшения времени вынужденного простоя для сброса конвейера с десятками обработанных впустую команд, так и на потреблении энергии, затрачиваемой зря на обработку неудачных ветвлений.
Дата добавления: 2015-09-29; просмотров: 894;