Виды информационных технологий по степени охвата задач управления
Информационные технологии можно разделить на несколько видов:
· ИТ обработки данных;
· ИТ управления;
· ИТ автоматизации офиса;
· ИТ поддержки принятия решения;
· ИТ экспертных систем
Рассмотрим их более подробно.
Информационная технология обработки данных (ИТОД) используется при решении структурированных задач, для которых можно разработать точные алгоритмы и процедуры обработки данных. Данная технология используется персоналом низкого уровня с невысокой квалификацией для автоматизации однообразных часто повторяющихся операций.
ИТ обработки данных включает в себя следующие операции (рис. 2.):
· сбор данных;
· обработка данных;
· хранение данных;
· создание отчетов.

Рис. 2. Операции в ИТ обработки данных
Информационная технология управления (ИТУ) ориентирования для удовлетворения информационных потребностей сотрудников организации, принимающих решения (менеджеров, руководителей отделов и т.д.). Данная технология связана с решением слабо структурированных задач.
ИТ управления включает в себя следующие операции (рис. 3.):

Рис. 3. Операции в ИТ управления
Как видно из рисунка в ИТУ отсутствует операция сбора данных, т.к. эта операция выполняется на первом этапе ИТОД.
Информационная технология автоматизации офиса (ИТАО) служит для автоматизации управленческого труда работников организации. Данная технология обеспечивает коммуникационные процессы как внутри организации, так и с внешней средой на базе компьютерных сетей и других средств связи. Среди программного обеспечения ИТАО можно выделить следующие: текстовый процессор, табличный процессор, электронная почта; электронный календарь, телеконференции и т.д.
Упрощенно работа ИТ автоматизации офиса приведена на рис. 4.

Рис. 4. ИТ автоматизации офиса
Информационная технология поддержки принятия решений (ИТППР) служит для выработки решения возникшей задачи или проблемы. Особенностями данной технологии является решение плохо структурированных задач, использование математического моделирования, направленность на непрофессионального пользователя ПК, возможность приспосабливания к новым условиям работы. ИТППР используется руководителями, как различных подразделений, так и директорами организаций.
ИТ поддержки принятия решений включает в себя (рис. 5.):
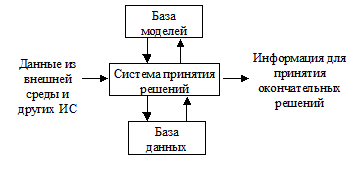
Рис. 5. Информационная технология поддержки принятия решений
Как видно из рисунка характерной особенностью ИТППР является наличие базы моделей. В этой базе хранятся модели, которые описывают на основе математических уравнений и выражений поведение реальных объектов или процессов. Благодаря моделям можно предсказать поведение объектов в будущем и на основе прогноза принять нужное решение.
Информационная технология экспертных систем (ИТЭС) позволяют получать менеджерам или специалистам консультации экспертов по проблемам, о которых накоплены большие знания. Работа экспертных систем базируется на основе интеллектуальных систем. Под искусственным интеллектом понимается способность компьютерных систем моделировать человеческое мышление и на его основе решать возникающие задачи.
Технология экспертных систем предусматривает возможность получать в качестве выходной информации не только решение, но и необходимые пояснения к этому решению.
Экспертная система (ЭС) оперирует с базой знаний. База знаний содержит факты, характеризующую проблемную область, а также логическую взаимосвязь этих фактов. На основе этих знаний ЭС по специально заданным правилам происходит поиск правильного решения.
Базы данных
В состав современных информационных систем, как правило, входят различные базы данных.
База данных (БД) – это совокупность организованных и взаимосвязанных данных о конкретных объектах реального мира в какой-либо предметной области. Под предметной областью принято понимать часть реального мира, подлежащего изучению для организации управления и автоматизации.
По технологии обработки данных БД подразделяются на:
· централизованные;
· распределенные.
Централизованная база данных хранится в памяти одного компьютера. Если этот компьютер подключен к локальной вычислительной сети, возможен распределенный доступ к такой базе.
Распределенная база данных состоит из нескольких, возможно пересекающихся или даже дублирующих друг друга частей, хранимых в различных ЭВМ вычислительной сети. Работа с такой базой осуществляется с помощью системы управления распределенной базой данных (СУРБД).
По способу доступа к данным базы данных разделяются на:
· базы данных с локальным доступом (обрабатываются только на одном компьютере);
· базы данных с удаленным (сетевым) доступом, т.е. базы данных, которые могут обрабатываться по сети.
Системы централизованных баз данных с сетевым доступом предполагают следующие архитектуры систем:
· файл-сервер;
· клиент-сервер.
Архитектура файл-сервер. Данная архитектура предполагает выделение в сети одного компьютера в качестве центрального, который носит название файл-сервер. На таком компьютере хранится централизованная база данных, которая находится в совместном использовании. Все остальные компьютеры в сети выполняют функции рабочих станций. Данная архитектура условно отображена на рис. 6.
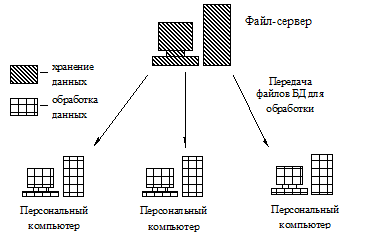
Рис. 6. Архитектура типа файл-сервер
В данной архитектуре все данные хранятся на сервере, а обрабатывается информация на рабочих станциях. Это удобно, если мощность сервера не велика и не позволяет вести обработку данных на самом сервере.
Архитектура клиент-сервер. Данная архитектура предполагает, что помимо хранения централизованной базы данных центральный компьютер, называемый сервер базы данных, должен выполнять основной объем работы по обработке данных. Рабочие станции посылают запросы на сервер. На каждый запрос сервер генерирует ответ и передает его рабочим станциям, при этом сами файлы не передаются по сети, а передаются только требуемые данные. Архитектура клиент-сервер условно отображена на рис. 7.
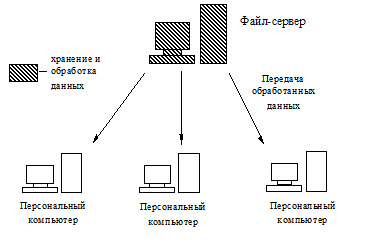
Рис. 7. Архитектура типа клиент-сервер
Данная архитектура удобна в том случае, если мощность рабочих станций не велика и не позволяет вести обработку информации на них. Также данная архитектура позволяет снизить нагрузку на вычислительную сеть организации, так как по сети передаются только запросы к серверу и результаты обработки информации. А файлы, которые, как правило, имеют большой размер, по сети не передаются.
Модели данных
Модель данных – это совокупность структур данных и операций их обработки. Различают три основные модели данных:
· иерархическая;
· сетевая;
· реляционная.
Иерархическую модель данных еще называют древовидной, так как она имеет структуру в виде перевернутого дерева (рис. 8). В этой модели каждый узел на более низком уровне (подчиненный узел) связан только с одним узлом, находящемся на более высоком уровне.
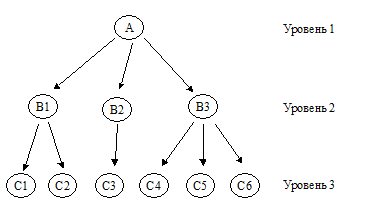
Рис. 8. Иерархическая модель данных
Данная модель используется для хранения данных, имеющих взаимное подчинение. Например, для описания структуры любой организации можно использовать иерархическую модель (Рис. 9).
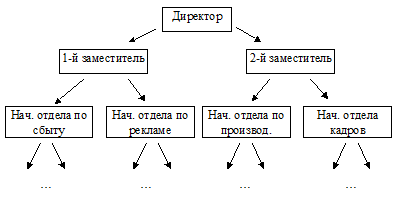
Рис. 9. Пример структуры организации
В сетевой модели в отличие от иерархической любой узел может быть связан с любым другим узлом (Рис. 10).
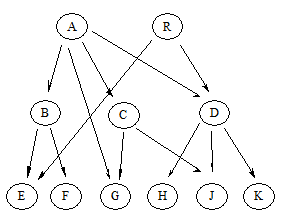
Рис. 10. Сетевая модель данных
Реляционная модель данных отображает все данные в виде обычной двухмерной таблицы. При этом сама таблица обладает следующими свойствами:
· каждый элемент таблицы является элементом данных;
· данные в каждом столбце имеют одинаковый тип (числовой, текстовый, дата и т.д.);
· каждый столбец имеет уникальное имя;
· одинаковые строки в таблице недопустимы;
· порядок следования строк и столбцов может быть произвольным.
Пример реляционной модели данных представлен в таблице:
| Поле 1 | Поле 2 | Поле 3 | Поле 4 |


При создании базы данных каждому полю таблицы задаются следующие параметры:
· имя;
· тип (текстовый, числовой, календарный);
· длина (может измеряться в байтах или символах);
· точность (указывается число десятичных знаков после запятой в числах);
· описание (это произвольный текст, подробно описывающий назначение поля).
Поле, каждое значение которого однозначно определяет соответствующую запись, называется простым ключом или ключевым полем. Если для однозначного определения записей используется несколько полей, то совокупность этих полей образуют составной ключ. Например, в приведенной ниже таблице для однозначного определения автомобиля должны использоваться поля Серия и Номер и регион. Таким образом, составной ключ будет состоять из этих двух полей.
| Марка автомобиля | Серия | Номер и регион | VIN | Адрес регистрации |
| ВАЗ 21043 | вдс | 654_34 | 500TT0505332 | Ленина, 2-25 |
| ВАЗ 21053 | хта | 213_34 | 3434YY354678 | Озерная, 32-12 |
| ВАЗ 2110 | вдс | 356_34 | 6865KK445442 | Ленина, 2-25 |
| ВАЗ 2110 | ннс | 579_34 | 12334LL84357 | Лесная, 4-44 |
| ВАЗ 2121 | вво | 894_34 | 876764GD5432 | Зеленая, 10-15 |
Ключи используются при обработке данных, а также применяются для контроля за достоверностью информации в таблицах. Изменение свойств ключа говорит о серьезном искажении информации.
Дата добавления: 2015-11-18; просмотров: 3981;