Организация кэш-памяти на основе множественно-ассоциативной памяти
Это модификация поиска с прямым отображением адресов. В этой схеме отображение адресов оперативной памяти в адреса кэш-памяти производится не для одной строки (кэш-памяти), а для множества строк, имеющих совпадения в младших разрядах их адресов в оперативной памяти.
Правомерна и другая интерпретация этой схемы как множеств отдельных блоков памяти с ассоциативным поиском информации, но с адресной выборкой "целевого" блока.
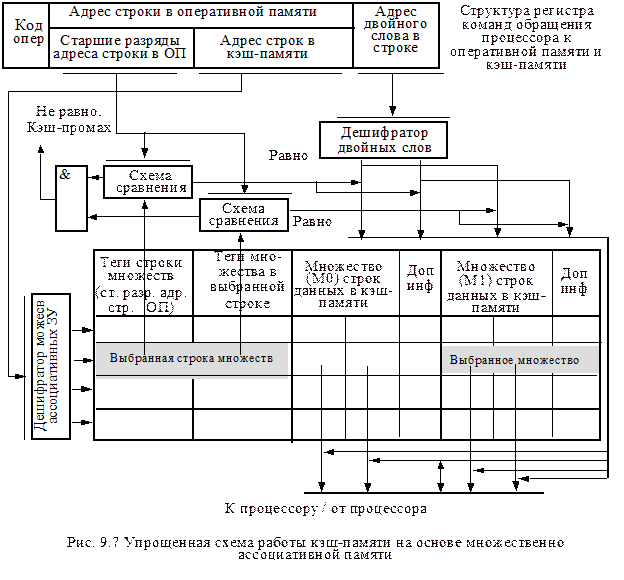
В этой схеме для строк оперативной памяти с совпадающими значениями младших разрядов оперативной памяти определена для сохранения не единственная строка кэш-памяти, а множество строк, кратное степени двух: два, четыре или восемь, наиболее часто – четыре. На рис. 9.7 представлена схема множественно-ассоциативной памяти с двумя множествами строк (М0 и М1 в одной выбранной строке кэш-памяти). Каждая из этих строк идентифицируется адресами, составленными из старших цифр адреса строки в оперативной памяти.
При обращении к кэш-памяти старшие разряды адреса строки оперативной памяти сравниваются с тегами на внешних схемах сравнения. При несовпадении этих строк фиксируется кэш-промах, при совпадении – фиксируется попадание для одного из множеств (М0 или М1 на рис. 9.7). При кэш-попадании данные (двойное слово) выбираются из кэш-памяти с учетом выбранного множества (М0 или М1) по адресу двойного слова в строке с использованием дешифратора двойных слов.
В множественно-ассоциативной кэш-памяти при кэш-промахе для обновления информации имеется альтернатива выбора множества с устаревшими данными. Для случая использования в строках кэш-памяти только двух множеств, определение устаревшего множества определяется элементарно. Устаревшее множество то, в которое не было обращения в последнем кэш-попадании.
Для 4-х и более множеств при решении этого вопроса используются более сложные алгоритмы выбора по "вероятности неиспользования" (LRU). Сложность этих алгоритмов значительно возрастает по мере роста числа множеств. Для 4 множеств (наиболее часто используемый вариант кэш-памяти) алгоритм (LRU) использует три бита дополнительной информации B0, B1 и B2, кроме битов присутствия и модификации информации операцией записи.
Алгоритм выбора устаревшей строки предусматривает при последних доступах:
· к массиву М0 или М1 установление бита В0 = 1,
· к массиву М0 установление бита В1,
· к массиву М1 очищение бита В1.
· к массиву М2, установление бита В2,
· к массиву М3 очищение бита В2.
Биты LRU обновляются после каждого доступа к кэш-памяти и очищаются при каждой перезаписи или очистке кэш-памяти.
При кэш-промахе кэш-контроллер определяет множество-кандидата на удаление по его адресу, составленному из значений В0, В1 и В3. Это адрес удаляемого множества в двоичной системе счисления:
· старшая двоичная цифра адреса соответствует значению бита В0,
· младшая двоичная цифра адреса соответствует значению функции (В0 & В2) V (В0 & В1).
Кэш-память на основе прямого отображения и множественно-ассоциативной памяти является наиболее распространенной. Но, по сравнению с реализацией на основе чисто ассоциативной памяти, она требует не два, а три такта работы:
1. определение строки кэш-памяти (по младшим разрядам адреса физической оперативной памяти),
2. определение строки или множества строк (по части старших разрядов адреса физической оперативной памяти),
3. чтение или обновление (запись) строки.
Этот недостаток можно компенсировать совместной оптимизацией алгоритмов работы механизмов кэш-памяти и виртуальной памяти на основе использования таблицы математических страниц (наиболее распространенный вариант реализации виртуальной памяти).
Программист пишет свои программы в диапазоне адресов своей математической памяти, операционная система с использованием механизма виртуальной памяти производит динамическую переадресацию команд и данных в пространство адресов физической памяти, выделенных данной программе.
В установившихся режимах работы процессора переадресация программ производится с использованием TLB (буфера быстрой переадресации на основе ассоциативной памяти) за один такт процессора.
Этот такт работы механизма виртуальной памяти можно совместить с первым тактом работы кэш-памяти. В этом случае, в первом такте работы кэш-памяти, при формировании адресов кэш-памяти с прямым отображением можно использовать не физические адреса команды или данных, которые еще не сформированы, а математические. Но в следующем такте сравнения тегов, для идентификации массивов строк данных необходимо использовать в качестве тегов старшие разряды уже физической памяти. Следующий (третий) такт кэш-памяти используется для обращения к массиву команд или данных при кэш-попаданиях.
Вопросы для самопроверки:
1. Проблема адресации данных в кэш-памяти.
2. Кэш-память на основе ассоциативного поиска.
3. Кэш память с прямым отображением.
4. Кэш-память на основе множественно-ассоциативной схемы поиска.
5. Алгоритм определения множества-кандидата на удаление.
6. Совместная оптимизация работы системы виртуальной и кэш-памяти.
Дата добавления: 2015-08-14; просмотров: 1799;