Текстовые критерии ранжирования результатов поиска в поисковых системах
| Критерий | Логика ранжирования |
| «Плотность» слова | Чем выше частота повторения слова в документе, тем больше ранг документа. Исключение составляет случай, когда ключевое слово повторяется слишком часто, в результате чего может сработать "спам-фильтр" поисковой системы и страница не попадет в выдачу. Оптимальной считается плотность ключевого текста 3-7%. Нужно также учитывать, что оптимальная плотность для различных поисковых фраз различна, т.е. "идеальной" плотности ключевых слов не существует. |
| Взаимное положение слов | Учёт полного совпадения фраз или их подобия (например, порядок и близость слов друг к другу). Идеальным считается вариант, когда поисковая фраза встречается в тексте как точное совпадение |
| Положение найденного текста по отношению к началу документа | Считается, что чем ближе расположена информация к началу документа, тем выше её значение |
| Наличие слов запроса в выделенных фрагментах и заголовках | Выделением отмечаются наиболее значимые фрагменты. Поэтому значимость обнаружения искомого текста в указанных фрагментах считается выше, чем в обычном тексте |
| Совпадение темы страницы с темой запроса | Использование в поиске слов, не содержащихся в тексте запроса, но соответствующих теме запроса |
| Совпадение названия домена или имени файла веб-страницы с ключевым словом | В некоторых случаях поисковые машины придают дополнительный «вес» страницам, у которых домен или имя файла совпадают с ключевым словом. Это гарантирует тематическую близость |
| Совпадение поискового запроса с описанием из каталога | Многие поисковые системы создают собственные каталоги. Сайт получает более высокий рейтинг, если слова поискового запроса совпадают с описанием из данного каталога. В некоторых поисковых системах дополнительный вес сайту придаёт сам факт присутствия в каталоге, так как в него попадают только ссылки на качественные страницы |
| Значимость редких слов | Значимость каждого из поисковых слов тем больше, чем реже оно встречается в документах. Соответственно, веб-страницы, содержащие редкие слова, получают приоритет по сравнению со страницами, содержащими частоупотребимые |
Оценку значимости фрагментов текста выработал Г.Лун. Он предложил оценивать фрагменты текста в соответствии с параметром: Vпр = 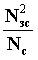 , где Vпр – значимость фрагмента; Nзс – число ключевых слов в данном фрагменте; а Nc – полное число слов в фрагменте.
, где Vпр – значимость фрагмента; Nзс – число ключевых слов в данном фрагменте; а Nc – полное число слов в фрагменте.
Автоматическая система выявления ключевых слов обычно использует статистический частотный анализ (методика В. Пурто). Пусть f – частота, с которой встречаются различные слова в тексте, а u – относительное значение полезности (важности), с – константа, которая определяет соотношение частоты слов и их полезности.
Тогда зависимость f(u) апроксимируется формулой 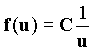 , то есть произведение частоты встречи слов и их полезности является константой. Данная гипотеза используется для вывода следствия о существовании двух пороговых значений частот. Слова с частотой менее нижнего порога считаются слишком редкими (не способными отразить смысл документа), а с частотой, превосходящей верхний порог, – общими, не несущими смысловой нагрузки. Слова с частотой, находящейся посередине между данными порогами, в наибольшей степени характеризуют содержимое данного конкретного документа (Г. Лун cм. также http://www.medialingvo.ru).
, то есть произведение частоты встречи слов и их полезности является константой. Данная гипотеза используется для вывода следствия о существовании двух пороговых значений частот. Слова с частотой менее нижнего порога считаются слишком редкими (не способными отразить смысл документа), а с частотой, превосходящей верхний порог, – общими, не несущими смысловой нагрузки. Слова с частотой, находящейся посередине между данными порогами, в наибольшей степени характеризуют содержимое данного конкретного документа (Г. Лун cм. также http://www.medialingvo.ru).
Согласно ссылочнымкритериям ранжирование документа осуществляется с учётом индекса цитирования. Индекс цитирования – это показатель известности сайта в Интернете, определяемый числом и значимостью ссылок на других сайтах на искомый ресурс.
Общее число внешних ссылок на сайт не подходит в качестве критерия для расчёта цитируемости – значимость ссылок на непопулярных ресурсах ничтожна по сравнению со значимостью ссылок с известных сайтов.
При определении индекса цитирования учитывается не только число внешних ссылок на сайт, но и индекс цитирования самих сайтов, ссылающихся на данный. При расчете веса страницы учитывается также соответствие текста ссылки (якорного текста) запросу и общая тематическая направленность ссылающейся страницы. Например, если поисковый запрос пользователя: «Рено Меган», то больший «вес» имеет ссылка на сайт с текстом «Продажа а/м Рено Меган», чем просто ссылка типа: «Большой выбор а/м». Наиболее «ценные» ссылки – ссылки, размещённые на головной странице высокоцитируемых сайтов, тематически связанных с поисковым запросом.
В общем случае, каждая прямая ссылка на веб-страницу увеличивает её цитируемость на величину, пропорциональную цитируемости ссылающейся страницы и обратно пропорциональную общему числу ссылок на ссылающейся странице. В поисковой системе «Google» эта величина называется PageRank, в поисковой системе «Яндекс» – ВИЦ (Взвешенный Индекс Цитируемости). Чем выше эта величина, тем выше в результатах поисковой выдачи находится сайт.
Поисковая система Google была создана в 1998 году выпускниками Стэндфордского университета Сергеем Брином (Sergey Brin) и Ларри Пейджем (Larry Page), в свое время работавшими над учебным проектом по идентификации смысловых элементов в структуре веб-ссылок. Они были впечатлены большим значением так называемых «обратных ссылок» (то есть страниц, ссылающихся на искомую страницу) и поняли, что их можно использовать для создания более эффективной поисковой системы.
Технология поиска PageRank компании Google Inc. работает по принципу установления структуры ссылок во всём Интернете, а затем ранжирует каждую отдельную страницу, основываясь на числе и значимости ссылок на неё на других страницах.
В статье, изданной Сергеем Брином и Ларри Пейджем, приведена рекурсивная формула для определения PageRank веб-страницы:
n PR(Ti)
PR(A) = (1-d) + d ∑ -----------
I=1 C(Ti)
где: PR(A) – вес PageRank страницы A;
d – коэффициент затухания, который обычно устанавливают равным 0,85. Позволяет ограничить объём вычислений до практически целесообразного;
Ti – страница, содержащая ссылки на страницу A (i изменяется от 1 до n);
PR(Ti) – вес PageRank страницы Ti;
C(Ti) – отношение общего числа ссылок страницыTi к числу ссылок данной страницы на страницу A.
Для расчёта индекса цитирования Google регулярно сканирует очень большие матрицы связей между сайтами Интернета, пересчитывая вес ссылок и авторитетность ресурсов. Для этого Google использует собственную систему, включающую около 10 000 серверов.
В 2000 г. Кришна Бхарат (Krishna Bharat) предложил усовершенствовать алгоритм PageRank. Бхарат установил, что для определения «веса» ссылок необходимо учитывать тематическую релевантность ссылающихся веб-страниц. Эти «тематически релевантные» веб-страницы он назвал «экспертными документами», а сумму «весов» ссылок с данных веб-страниц – «оценкой (уровнем) авторитетности».
При подсчёте индекса цитирования сайта, как правило, не учитываются ссылки с досок объявлений, форумов, сетевых конференций, каталогов и прочих ресурсов, в которые интернет-маркетолог может добавить ссылку на свой сайт самостоятельно. Ведущие поисковые системы предлагают специальные программные инструменты – тулбары (от англ. toolbars) для самостоятельного расчёта пользователем индекса цитирования интересующей его страницы (см. рис. 2).
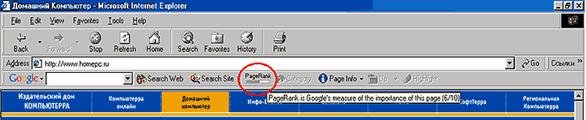
Рис. 2. Заголовок окна браузера с включённым в него тулбаром поисковой системы Google, отражающим PageRank просматриваемой страницы
Согласно критерию пользовательской оценки для ранжирования страниц в поисковой выдаче используется система оценки качества страниц пользователями. В самом простом случае она основана на принципе голосования пользователей конкретной поисковой системы, отражающем пользовательскую оценку посещаемых страниц.
Более объективные данные о пользовательских предпочтениях собирают системы, основанные на предположении: если пользователь переходит по ссылке – значит, он счёл её интересной, и если долго не возвращается на страницу поисковой системы – значит, его ожидания подтвердились. Именно эти критерии – число переходов по ссылке, время нахождения на странице и возвраты к поисковому серверу – легли в основу корректора релевантности, разработанного компанией DirectHit.
Пример.Поисковая система Rambler при ранжировании результатов поиска в ответах на поисковый запрос использует не только традиционные методы определения релевантности, но и так называемый коэффициент популярности, определяемый по числу пользователей, которые просматривали данную страницу за последние несколько недель.
Для специалистов по интернет-маркетингу поисковые сервера предлагают механизм самостоятельного включения информации об анонсируемом сайте в БД поисковой системы – самостоятельную регистрацию, последовательное заполнение специальных форм. Основной критерий при поиске в базе поисковых систем - ключевые слова, то есть те слова, которые наиболее характерны для описываемого сайта. Поэтому, перед подачей запроса на включение сайта в БД поискового сервера (самостоятельной регистрацией) необходимо сформулировать список ключевых слов и краткое, в две-три фразы, описание сайта. Лаконичное описание должно выделять сайт из всех сайтов родственной тематики.
Большое значение для повышения релевантности имеет заголовок сайта и его описание, а также каждое слово в названиях отдельных страниц сайта и в первых абзацах текста на них. Заголовок должен состоять не менее чем из пяти слов, вместе с началом страницы он должен служить ее четкой аннотацией и привлекать потенциальных посетителей.
При выдаче результатов поиска пользователю поисковая система отображает не только ссылки на выбранные ресурсы, но также и краткое описание ресурса. Выдаваемая информация состоит из трех основных частей:
- заголовок сайта;
- адрес ресурса;
- краткое описание ресурса.
Все это вместе носит название сниппета – описания сайта, выдаваемого поисковой системой в результатах поиска.
Важность описания, выдаваемого поисковой системой, трудно переоценить. Если оно будет неудачным, то пользователи предпочтут конкурирующие ресурсы, даже если ваш сайт будет иметь лучшие позиции в результатах поиска.
Специалисту по интернет-маркетингу необходимо добиться того, чтобы выводимая информация выглядела эффектно, адекватно отражала содержание веб-страницы или веб-сайта и привлекала внимание пользователя.
Автор ресурса не может непосредственно влиять на выдаваемое описание, однако аккуратное редактирование текста страницы и ведение истории сниппетов позволяет добиться более привлекательного описания.
Пример. На рис. 3 представлен модуль "Работа со сниппетами" из пакета Semonitor, предназначенный для ведения истории сниппетов. Как видно из рисунка, более позднее описание является более коротким, но в то же время более информативным и привлекательным.
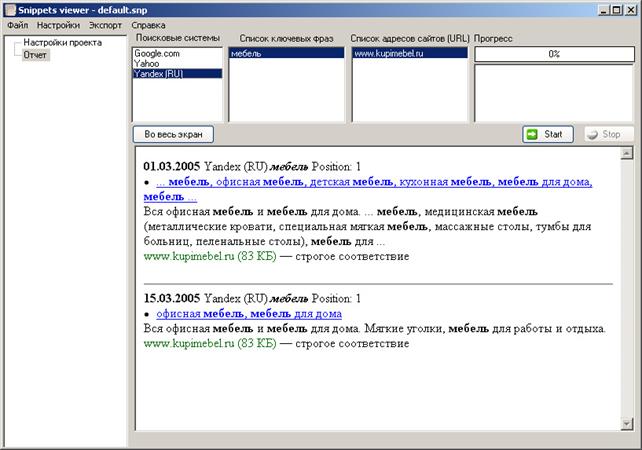
Рис. 3. Анализ сниппетов в программе Semonitor
Многие поисковые системы объединены вместе со службами каталогов, например, Yahoo (www.yahoo.com) или рейтингами, например, Rambler (www.rambler.ru), поэтому, регистрируясь в поисковой системе, можно зарегистрироваться и в каталоге (см. п. 2.2)
Существует специальное ПО (роботы регистраторы) для автоматической регистрации веб-сайта на большом числе поисковых систем. Как правило, эти программы платные, а их демонстрационные версии работают только с несколькими десятками поисковых серверов.
Большинству поисковых систем требуется некоторое время для реакции на присланные заявки на регистрацию.
Нужно отметить, что предпринимателю, важно отслеживать поисковые запросы, осуществляемые целевыми потребителями, не только на сайте предпринимателя, но и в поисковых системах. Формулировки запросов могут показать неизвестные стороны интересов аудитории, оперативно сообщить об их изменениях.
Дата добавления: 2015-08-14; просмотров: 1676;