Оптимизация кода для поисковых систем и стандарты доступности (использование нужных тегов, неиспользование устаревших тегов)
Одним из важных критериев создания HTML/XHTML документов является их пригодность для индексирования поисковыми системами. В данной главе мы рассмотрим основные принципы создания веб-документов, оптимизированных для поисковых машин. Такая оптимизация известна как SEO, от сокращения Search Engine Optimization.
Создание HTML/XHTML документов, оптимизированных для поисковых машин, предполагает особый подход написания кода. Ранее мы уже упоминали о том, что при создании документов следует разделять содержание и отображение, сохраняя HTML код максимально простым и прозрачным, а все что касается отображения, включать в CSS. Здесь же мы акцентируем внимание на принципах ранее не рассмотренных. Давайте рассмотрим, каким же образом происходит индексирование документов.
Сперва, поисковая система получает URL документа, либо напрямую, при его регистрации, либо с другого документа, в котором есть ссылка на текущий. Далее, поисковая система посылает поискового робота (он же bot, он же spider), выяснить, что собой представляет данный ресурс и какого рода информацию он содержит.
Робот начинает чтение всего документа, включая теги, текст и ссылки на другие страницы, а также некоторые элементы заголовка документа, включая теги META и TITLE. Впрочем, все эти детали могут отличаться, в зависимости от поисковой системы. Далее, робот сохраняет полученную информацию в базе данных поискового сервера для ее дальнейшей обработки.
Затем, робот следует по ссылкам, встретившимся в документе, выполняя аналогичную работу и для текущего документа. Как правило, такой робот не наделен искусственным интеллектом и работает по предопределенному алгоритму, что существенно ограницивает поле его деятельности. А именно, без его внимания остаются куски JavaScript кода, ссылки в формах документа и пр. Другими словами, робот не в состоянии выявить ссылки внутри кода скрипта, также не может он заполнить поля формы и отправить ее, чтобы перейти на следующую страницу. Например, если первой страницей сайта является страница логина, поисковый сервер не в состоянии проиндексировать такой сайт по причине того, что роботу недоступны страницы, следующие после логина.
Если вам когда-либо приходилось видеть браузер Lynx в действии, то это наилучшая аналогия того, что видит поисковый робот – текст и простые ссылки. Никакой графики, никаких скриптов и CSS стилей. Если ваш HTML документ состоит преимущественно из графики – поисковый робот не увидит ничего! То же самое касается сайтов, полностью реализованных на Flash.
После того, как информация из страницы попала в базу данных поискового сервера, запускается механизм ее обработки, или, другими словами, индексирования. Как правило, это некий алгоритм, специфичный для конкретного поискового сервера. В соответствии с этим алгоритмом, осуществляется выбор наиболее важных ключевых слов и фраз, основываясь на том, как часто эти слова и фразы встречаются в документе. Их важность также определяют элементы, внутри которых они содержатся. Например, фраза внутри тега H1, будет рассматриваться как более значимая, чем фраза внутри H2 и т.д.
Помимо результатов обработки содержимого документа, поисковый сервер смотрит еще и на то, как часто встречаются ссылки на текущий документ из других документов того же сайта или вовсе из других сайтов. Чем больше таких ссылок, тем большая значимость присуждается текущему документу, и, соответственно, его ключевым фразам. Впрочем, эта тема оптимизации не касается создания HTML и, следовательно, дальше рассматриваться не будет.
Подводя итог вышесказанному, можно выделить несколько правил оптимизации HTML кода.
Для оптимизации в рамках SEO (search engines optimization) следует использовать семантическое разбиение контента, т.е. по смыслу.
Также следует учитывать, что в первую очередь робот должен увидеть смысловое наполнение страницы, а не оформительскую или навигационную составляющие, т.е. часто имеет смысл поставить контент как можно ближе к началу файла, а шапку перенести в конец. Для этого можно воспользоваться абсолютным позиционированием блоков:
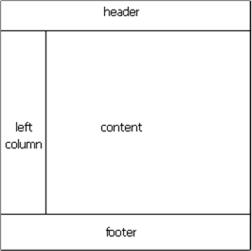
HTML:
<div id="main">
<div id="content">
content
</div>
<div id="navigation">
left column
</div>
<div id="header">
header
</div>
<div id="footer">
footer
</div>
</div>
CSS:
#main {
margin: 0 auto;
width: 710px;
padding-top:50px; /* оставляем место для шапки*/
position:relative;
}
#header {
width: 710px;
height: 50px;
position:absolute; /* позиционируем шапку на место */
left:0;
top:0;
}
#footer {
width: 710px;
height: 50px;
clear: both;
}
#leftcolumn {
width: 100px;
float: left;
}
#content {
width: 610px;
float: right;
}
Заголовки оформляются как h1, h2, h3… Абзацы – p. Цитаты – cite. И т.п. Блоки элементов форм – fieldset. Списки – ul/li, ol/li, dl/dt/dd. Использовать table только для представления табличных данных.
Следует избегать использования устаревших тэгов, таких как: b, i, q, s, nobr, font и т.п. (список основных тэгов представлен в главе 6.1)
Страница не должна состоять целиком из изображений. Наиболее важные ее части должны быть в текстовом виде, даже в том случае, если в дизайне это – графика. Рассмотрим пример: в дизайне нарисован логотип с названием компании «CoolSlicers», в самом начале страницы. Разумеется, речь не идет о замене графического логотипа на обычный текст. Прием состоит в том, что в HTML документе мы должны таки написать этот текст логотипа, а именно «CoolSlicers», и поместить его внутрь соответствующего элемента, подчеркнув, таким образом, его значимость, например в H1. Но так как в действительности этот текст отображаться не должен, а вместо него должно быть изображение с графическим логотипом, то мы используем решение, описанное в 6.5.1
При оптимизации HTML кода для поисковых систем, может оказаться полезным симулятор поискового робота, доступный по адресу http://www.webconfs.com/search-engine-spider-simulator.php. Он покажет вам, что можно извлечь из вашего документа, а именно, какой текст и какие ссылки.
Возвращаясь к структуре документа, следует помнить, что поисковые роботы читают содержимое схожим образом, что и люди, т.е. сверху вниз, слева направо (если не считать некоторые культуры, где принято читать справа налево). Они также предполагают, что наиболее значимая информация находится в начале страницы, а не в ее конце.
Наиболее значимым элементом HTML документа с точки зрения SEO считается TITLE. Поэтому, информация, находящаяся внутри этого тега должна отражать главную мысль содержимого конкретной страницы. Многие разработчики вставляют туда просто название компании, причем это повторяется для всех страниц сайта. Это неправильно. Если важно, чтобы название компании фигурировало в TITLE, его можно поместить в конце, после соответствующего заголовка конкретной страницы. Следовательно, очередным правилом SEO является правильно сформированный TITLE документа.
Следующими элементами, которые стоит рассмотреть в рамках SEO это теги META, расположенные в заголовке документа. Элемент <meta name="keywords">, в котором испокон веков перечисляли ключевые слова и фразы веб-страницы, постепенно утрачивает свою значимость. Создатели некоторых поисковых систем настаивают на том, что они вовсе не читают его содержимое. Тем не менее, не стоит им пренебрегать.
Более важным является <meta name="description">, который читается всеми современнными поисковыми системами. Как и TITLE, этот элемент должен содержать основную мысль текущего документа в кратком виде. Содержание этого элемента также не должно повторяться от страницы к странице. Оно должно быть уникальным. Это и есть следующее правило SEO.
Как мы уже говорили ранее, фрагменты JavaScript являются чем то непонятным для поискового робота. Многие поисковые системы имеют ограничение по максимально допустимой длине «бесполезного» кода. Иными словами, наличие большого фрагмента JavaScript кода в заголовке может быть причиной того, что оставшаяся часть документа не будет обработана. То же самое касается и CSS. Отсюда можно сделать вывод, что следует избегать наличия скриптов и CSS фрагментов внутри HTML документа. Таким образом, формируем следующее правило SEO: скрипты и CSS стили должны быть во внешних файлах, а не внутри документа.
Мы уже говорили о том, что все значимые фразы страницы должны быть в виде текста, даже в том случае, если в дизайне они представлены графически. Тем не менее, существует средство, позволяющее кое-как компенсировать этот недостаток. Это атрибут ALT элемента IMG. Внутри этого атрибута можно поместить текст, который бы выражал смысл информации, предоставленной графически. Однако, современные поисковые машины невысоко оценивают текст, содержащийся в атрибутах ALT. Этот подход, в принципе, может быть использован, например в таких частях дизайна, как навигация, но это далеко не наилучший вариант. В связи с этим, рассмотрим вариант идеальной навигации для поисковых машин. Вот он:
SEO: навигация
<ul>
<li><a href=”page1.html”>Link 1</a></li>
<li><a href=”page2.html”>Link 2</a></li>
<li><a href=”page3.html”>Link 3</a></li>
</ul>
Как видно из примера, оптимизированная для поисковых машин навигация представляет собой список ссылок на другие документы в буквальном смысле этого слова. Причем такой вид она должны иметь всегда, независимо от дизайна! То, как эта навигация будет отображаться, должно быть указано во внешнем CSS файле. В случае чисто графической навигации, допускается поместить текст ссылок в элемент SPAN, с последующим указанием стиля «display: none».
Следующим правилом SEO является интенсивное использование тегов заголовков: H1, H2, H3 и т.д. Применять их нужно, разумеется по назначению, помещая внутри первостепенные, второстепенные и т.д. текстовые заголовки. Как правило, хорошо оптимизированный документ содержит только один элемент H1. Что касается элементов H2, H3 и пр., то их может быть сколько угодно, но, опять таки, в пределах разумного.
Классический подход создания HTML документов подразумевает широкое использование таблиц неограниченной вложенности для позиционирования элементов дизайна. Этот метод в SEO неприменим по нескольким причинам. Во-первых, из-за вложенности. Обычно получается так, что информационное наполнение страницы находится внутри ячеек таблиц большой вложенности, что само по себе понижает их значимость с точки зрения поисковой системы, даже в случае, если оно будет обработано. Во-вторых, в смысловом плане таблица являет собой некий список данных, а не средство разделения документа на его части вроде заголовка, навигации или нижнего колонтитула. Поис система не имеет ни малейшего представления о том, почему веб-разработчик разбил содержимое страницы при помощи таблиц именно таким образом, а не иначе. Отсюда вытекает следующее правило: использование таблиц необходимо свести к минимуму (максимум три уровня вложенности), а лучше не использовать их вовсе.
Чтобы подчеркнуть значимость отдельных слов и фраз внутри текста, имеет смысл их заключить внутрь элемента STRONG или B. В то время, как наиболее популярным является элемент B, консорциум W3C рекомендует использовать именно STRONG. Это является последним правилом оптимизации HTML документов для поисковых машин, которое мы рассмотрим.
В заключение, хочу напомнить, что хорошо оптимизированный документ, в добавок, должен полностью соответствовать своей спецификации, причем, лучше, чтобы это был XHTML.
Заключение
Если вы внимательно ознакомились с данной работой, то наверняка уже обладаете многими качествами HTML-верстальщика. Все остальные свойства приходят с опытом. Поэтому последним советом будет взять готовый дизайн и попытаться сделать из него HTML или XHTML документ с учетом полученных знаний. Попытайтесь сделать один и тот же дизайн в соответствии с несколькими спецификациями. Не забудьте проверить правильность полученных документов и CSS. Попробуйте свои силы в составлении веб-документов оптимизированных для поисковых систем. Не жалейте времени, чтобы разобраться в непонятных для вас вопросах.
Надеюсь, эта работа оказалась полезной для вас.
Все замечания, предложения и поправки просьба высылать по адресу: andrey@advanware.com.
Желаю удачи!
Дата добавления: 2015-07-07; просмотров: 935;