Методы построения кодеров и декодеров таких кодов исследуются в лабораторной работе №7 «Кодеры и декодеры систематических кодов»[1. с. 70-77].
Рассмотренный алгоритм декодирования блоковых групповых линейных систематических (n,k)-кодов, называемый иногда синдромным, относится к классу алгебраических методов декодирования, в основе которых лежит решение системы уравнений, задающих расположение и значение ошибки.
Для декодирования этих кодов могут использоваться и неалгебраические методы, использующие простые структурные понятия теории кодирования, которые позволяют найти комбинации ошибок более прямым путем. Одним из таких алгоритмов является декодирование по максимуму правдоподобия.
Этот метод основывается на том предположении, что если все кодовые комбинации передаются по двоичному симметричному каналу с равной вероятностью, то наилучшим решением при приеме является такое, при котором переданной считается кодовая комбинация, отличающаяся от принятой в наименьшем числе разрядов. В связи с этим алгоритм максимального правдоподобия реализуется в виде следующей последовательности действий:
1) принятая кодовая комбинация Y суммируется по модулю два последовательно со всеми кодовыми комбинациями кода Xi , в результате каждого суммирования вычисляются векторы ошибок ei = Y+Xi ,
2) подсчитывается число di единиц в каждом из векторов ошибки ei,
3) та из Xi, для которой di минимально, считается переданной кодовой комбинацией.
Для некоторых систематических (n,k)-кодов неравенство (3.12)
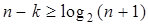
превращается в строгое равенство
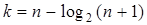
| (3.20) |
Для таких кодов можно записать 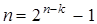 и, поскольку
и, поскольку 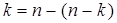 , то
, то 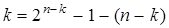 .
.
(n,k)-коды вида 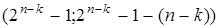 называются кодами Хэмминга (3.21).
называются кодами Хэмминга (3.21).
Образующая матрица кода Хэмминга (7,4) приведена ранее (3.15). Образующие матрицы кодов больших размерностей строятся аналогично.
Уравнение (3.20) имеет целочисленные решения при k=0,1,4,11,26,57,120, . . , что дает соответствующие коды Хэмминга (3,1), (7,4), (15,11), (31,26), (63,57), (127,120),. . . . Коды Хэмминга относятся к немногим известным т.н. совершенным кодам. С учетом данных ранее определений кодового пространства и кодового расстояния представим некоторый код в виде сфер с центрами во всех разрешенных кодовых комбинациях. Все сферы имеют одинаковый целочисленный радиус. Будем увеличивать его, оставляя целочисленным, до тех пор, пока сферы не пересекутся. Значение этого радиуса равно числу исправляемых кодом ошибок. Этот радиус называется радиусом сферической упаковки кода. Теперь позволим этому радиусу увеличиваться до тех пор, пока каждая точка кодового пространства не окажется внутри хотя бы одной сферы. Такой радиус называется радиусом покрытия кода. Радиус упаковки и радиус покрытия кода могут совпадать. Код, для которого сферы некоторого одинакового радиуса вокруг кодовых слов, не пересекаясь, покрывают все кодовое пространство, называются совершенными. Совершенный код удовлетворяет границе Хэмминга с равенством. Код Хэмминга, имеющий длину 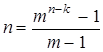 , является совершенным.
, является совершенным.
Код, у которого сферы радиуса t вокруг каждого кодового слова не пересекаются и все кодовые слова, не лежащие внутри какой-либо из этих сфер, находятся на расстоянии t+1 хотя бы от одного кодового слова, называется квазисовершенным. Квазисовершенные коды встречаются чаще, чем совершенные. Если для заданных n и k существует квазисовершенный и не существует совершенного кода, то для этих n и k не существует кода с большим, чем у квазисовершенного, кодовым расстоянием.
Систематические коды, в том числе и код Хэмминга, допускают различные преобразования, которые, порождая новые коды, тем не менее, не выводят их из класса линейных групповых кодов.
К числу наиболее часто используемых преобразований кодов относят укорочение и расширение кодов.
Укорочение кода состоит в уменьшении длины кодовых комбинаций путем удаления лишних информационных разрядов. Если код задан порождающей матрицей, то это приводит к уменьшению обоих размеров порождающей матрицы на одно и то же число. Так, например, как упоминалось ранее, коды Хэмминга с d=3 могут быть построены с вполне определенным сочетанием n и k. Как поступить в том случае, если требуется код Хэмминга с d=3, для передачи информации достаточно k=8, а на длину кодовой комбинации наложено ограничение n<15. Для выполнения этих требований можно выбрать код Хэмминга (15,11) и прибегнуть к его укорочению. Укорочение производится за счет удаления требуемого числа лишних информационных разрядов, обычно это первые слева разряды. В образующей матрице кода (15,11) полагаются равными нулю столько столбцов слева, сколько разрядов надо удалить, после чего вычеркиваются нулевые столбцы и строки с полностью нулевыми строками единичной матрицы. Относительно проверочной матрицы операция укорочения выражается в удалении соответствующего количества первых слева столбцов, так как число строк проверочной матрицы, равное числу контрольных разрядов, остается неизменным при укорочении. Для приведенных значений k=8 и n<15 из кода (15,11) нужно удалить три лишних информационных разряда, в результате чего получится укороченный код (12,8), который также называется кодом Хэмминга.
Расширение кода состоит в увеличении длины кодовых комбинаций за счет введения новых контрольных разрядов, что приводит к увеличению большего размера порождающей матрицы, и, естественно, к увеличению d, т.е. повышению корректирующих способностей. В качестве примера можно привести расширенный код Хэмминга (8,4) с d=4. Этот код образуется путем добавления к каждой кодовой комбинации кода Хэмминга (7,4) еще одного контрольного разряда, значение которого определяется как сумма по модулю два всех остальных разрядов кодовой комбинации, т.е. общая проверка на четность всей кодовой комбинации. При декодировании комбинаций этого кода возможны следующие варианты: 1) ошибок нет. Это показывает как общая проверка на четность, так и равенство нулю синдрома; 2) одиночная ошибка. Общая проверка на четность указывает на наличие ошибки, а по синдрому находится номер искаженного разряда и ошибка в нем исправляется. Нулевой синдром в этом случае указывает на наличие ошибки в дополнительном разряде. Таким образом, имеет место режим исправления ошибок; 3) две ошибки. Общая проверка на четность указывает на отсутствие ошибок, ненулевой синдром – на их наличие, причем значение синдрома указывает на разряд в котором якобы произошла ошибка, однако в этом случае ее не следует исправлять, а лишь констатировать наличие двух ошибок. Таким образом, реализуется режим обнаружения ошибок.
Рассмотренные преобразования (укорочение и расширение) можно использовать для модификации известных кодов, чтобы сделать их подходящими для каких-либо конкретных приложений, а также для получения новых классов хороших кодов.
Контрольные вопросы к лекции 10
10-1. На что указывает граница Хемминга?
10-2. На что указывает граница Плоткина?
10-3. На что указывает граница Варшамова – Гилберта?
10-4. Почему систематические линейные коды называются групповыми?
10-5. В чем состоит свойство замкнутости группы?
10-6. Как определяются значения контрольных разрядов в каждой кодовой комбинации группового линейного систематического кода?
10-7. Что является особенностью группового линейного систематического кода?
10-8. Чем определяется число проверочных уравнений для группового систематического кода?
10-9. Что задает система проверочных уравнений группового систематического кода?
10-10. Какие кодовые комбинации называются образующими или базисными векторами для того или иного группового линейного кода?
10-11. Почему в качестве образующих удобно выбрать комбинации, которые содержать лишь по одной единице в информационных разрядах?
10-12. Как формируется образующая матрица (n,k)-кода, если задана система проверочных уравнений?
10-13. Как при наличии образующей матрицы можно найти все остальные кодовые комбинации (n,k)-кода?
10-14. Из каких подматриц состоит образующая матрица (n,k)-кода?
10-15. Как может быть сформирована дополняющая матрица (n,k)-кода, если не заданы проверочные уравнения?
10-16. Как, пользуясь образующей матрицей (n,k)-кода, построить систему проверочных уравнений?
10-17. Как, пользуясь образующей матрицей (n,k)-кода, построить проверочную матрицу?
10-18. Как, пользуясь проверочной матрицей (n,k)-кода, построить систему проверочных уравнений?
10-19. Что называется синдромом?
10-20. Какое значение синдрома указывает на наличие ошибки в принятой кодовой комбинации?
10-21. Что называется исправляющим вектором?
10-22. Как можно истолковать содержимое дополняющей подматрицы, пользуясь понятием синдрома?
10-23. Как можно истолковать содержимое единичной подматрицы, пользуясь понятием синдрома?
10-24. Как осуществляется декодирование по максимуму правдоподобия?
10-25. Какие (n,k)-коды называются кодами Хэмминга?
10-26. Что называется радиусом сферической упаковки кода?
10-27. Что называется радиусом покрытия кода?
10-28. Какой код называется совершенным?
10-29. Какой код называется квазисовершенным?
10-30. Как осуществляется укорочение кода?
10-31. Как сказывается укорочение кода на размерах образующей матрицы?
10-32. Как сказывается укорочение кода на размерах проверочной матрицы?
10-33. С какой целью выполняется укорочение кода?
10-34. Как осуществляется расширение кода?
10-35. Как сказывается расширение кода на размерах образующей матрицы?
10-36. Как сказывается расширение кода на размерах проверочной матрицы?
10-37. С какой целью выполняется расширение кода?
10-38. Как образуется расширенный код Хэмминга (8,4) с d=4?
10-39. Как определяется отсутствие ошибок в принятой кодовой комбинации расширенного кода Хэмминга (8,4) с d=4?
10-40. Как определяется наличие двух ошибок в принятой кодовой комбинации расширенного кода Хэмминга (8,4) с d=4?
Лекция 11. Полиномиальные коды
В предыдущей лекции кодовые комбинации (n,k)-кода представлялись в виде набора символов (а0, а1, . . .аn-1) длиной n. Другой способ представления того же кодового слова состоит в том, чтобы элементы а0, а1, . . .аn-1 считать коэффициентами полинома n-1 степени от некоторой фиктивной или формальной переменной x, т.е.
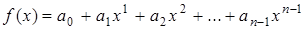 .
.
Используя это обозначение, можно определить полиномиальный код, как множество всех полиномов степени, не большей n-1, содержащих в качестве сомножителя некоторый фиксированный полином g(x). Полином g(x) называется порождающим полиномом кода.
Для того чтобы иметь возможность умножать кодовые полиномы, разлагать их на множители и производить другие операции, необходимо потребовать, чтобы все коэффициенты полинома были элементами некоторого конечного алгебраического поля. Конечное поле, называемое также полем Галуа и обозначаемое GF(q) – это конечное множество, состоящее из q элементов, в котором определены правила для выполнения арифметических операций. Основное отличие их от обычных арифметических операций состоит в том, что в конечном поле все операции производятся над конечным числом элементов, в связи с чем все конечные поля обладают следующими свойствами:
1. Существуют две операции, используемые для комбинирования элементов – умножение и сложение.
2. Результатом сложения или умножения двух элементов является третий элемент, лежащий в том же поле.
3. Поле всегда содержит мультипликативную единицу 1 и аддитивную единицу 0 , так, что а*1=а и а+0=а для любого элемента а поля.
4. Для любого элемента а поля существует обратный элемент по сложению (-а), такой, что а + (-а)=0 и обратный элемент по умножению а-1 (при а¹0), такой, что а* а-1=1. Существование этих элементов позволяет использовать обычные обозначения для вычитания и деления.
5. Выполняются обычные правила ассоциативности, коммутативности и дистрибутивности.
Конечные поля существуют не при любом числе элементов q, а только в том случае, если число элементов q является простым числом или степенью простого числа. В первом случае поле называется простым, во втором – расширенным. Для каждого допустимого q существует ровно одно поле. Другими словами, правила сложения и умножения, удовлетворяющие всем указанным требованиям можно задать только одним способом. Если q – простое число, то элементами поля являются числа 0, 1, . . . , q-1, а сложение и умножение являются сложением и умножением по модулю q.
С учетом сказанного о полиномиальном представлении кодовых комбинаций и операций над ними для двоичного случая, т.е. над полем GF(2) эти операции выполняются следующим образом.
1. Кодовая комбинация 100101 может быть представлена в виде полинома F(x)=1*x5+0*x4+0*x3+1*x2+0*x1+1*x0b = x5+x2+1.
2. Сложение таких полиномов осуществляется следующим образом. Пусть, например, f1 = x7+x4+x3+x+1, а f2 = x5+x4+x2+x, тогда f3=f1+f2 = x7+x5+x3+x2+1. В двоичном виде 10011011 Å 00110110 = 10101101.
3. Умножение полиномов. Пусть, например, f1 = x3+x2+1 и f2 = x+1, тогда f3=f1*f2 = x4+x3+x+x3+x2+1 = x4+x2+x+1. В двоичном виде (1101)*(11)=(01101) Å (11010) = 10111. Циклический сдвиг некоторого полинома, а он, напомним, форма представления кодовой комбинации, соответствует простому умножению этого полинома на x.
4. Деление полиномов. Пусть, например, f3 = x4+x2+x+1, а f2 = x+1, тогда f1= f3/f2 = x3+x2+1, что можно продемонстрировать, выполняя деление полиномов столбиком или делая то же самое в двоичном виде.
При некоторых значениях n полиномиальные коды обладают свойством цикличности и называются циклическими. Свойство цикличности состоит в том, что если кодовая комбинация аn, аn-1, . . . , а1 является разрешенной кодовой комбинацией данного кода, то и кодовая комбинация, аn-1, . . . , а1, аn, получаемая из нее путем циклического сдвига, тоже будет разрешенной кодовой комбинацией данного кода. Сдвиг обычно осуществляется справа налево, причем крайний левый символ переносится в конец комбинации. Число возможных циклических (n,k)- кодов значительно меньше числа различных групповых (n,k)- кодов.
При использовании циклических кодов процесс кодирования, так же, как и в рассмотренных (n,k)- кодах, сводится к определению значений n-k контрольных разрядов на основании известных значений k информационных разрядов для каждой кодовой комбинации.
При полиномиальном представлении этот процесс осуществляется следующим образом. Полином f(x), отображающий комбинацию безызбыточного двоичного кода умножается на xn-k. Это приводит к увеличению длины кодовой комбинации на n-k разрядов, которые и используются в качестве контрольных. Далее произведение f(x)* xn-k делится на некоторый полином g(x), названный ранее образующим, и остаток от этого деления r(x) суммируется с произведением f(x)* xn-k. Полученная кодовая комбинация описывается полиномом,
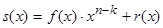 , ,
| (3.21) |
который без остатка делится на образующий полином g(x).
Сказанное является важным свойством циклических кодов, используемым при декодировании для обнаружения или исправления ошибок.
Дата добавления: 2015-07-30; просмотров: 1352;