Иерархический кластерный анализ
В статистике существует два основных типа кластерного анализа (оба представлены в SPSS): иерархический и осуществляемый методом k-средних. В первом случае автоматизированная статистическая процедура самостоятельно определяет оптимальное число кластеров и ряд других параметров, необходимых для кластерного
анализа. Второй тип анализа имеет существенные ограничения по практической применимости — для него необходимо самостоятельно определять и точное количество выделяемых кластеров, и начальные значения центров каждого кластера (центроиды), и некоторые другие статистики. При анализе методом k-средних данные проблемы решаются предварительным проведением иерархического кластерного анализа и затем на основании его результатов расчетом кластерной модели по методу k-средних, что в большинстве случаев не только не упрощает, а наоборот, усложняет работу исследователя (в особенности неподготовленного).
В целом можно сказать, что в связи с тем, что иерархический кластерный анализ весьма требователен к аппаратным ресурсам компьютера, кластерный анализ по методу k-средних введен в SPSS для обработки очень больших массивов данных, состоящих из многих тысяч наблюдений (респондентов), в условиях недостаточной мощности компьютерного оборудования1. Размеры выборок, используемых в маркетинговых исследованиях, в большинстве случаев не превышают четыре тысячи респондентов. Практика маркетинговых исследований показывает, что именно первый тип кластерного анализа — иерархический — рекомендуется для использования во всех случаях как наиболее релевантный, универсальный и точный. Вместе с тем необходимо подчеркнуть, что при проведении кластерного анализа важным является отбор релевантных переменных. Данное замечание очень существенно, так как включение в анализ нескольких или даже одной нерелевантной переменной способно привести к неудаче всей статистической процедуры.
Описание методики проведения кластерного анализа мы проведем на следующем примере из практики маркетинговых исследований.
Исходные данные:
В ходе исследования было опрошено 745 авиапассажиров, летавших одной из 22 российских и зарубежных авиакомпаний. Авиапассажиров просили оценить по пятибалльной шкале — от 1 (очень плохо) до 5 (отлично) — семь параметров работы наземного персонала авиакомпаний в процессе регистрации пассажиров на рейс: вежливость, профессионализм, оперативность, готовность помочь, регулирование очереди, внешний вид, работа персонала в целом.
Требуется:
Сегментировать исследуемые авиакомпании по уровню воспринимаемого авиапассажирами качества работы наземного персонала.
Итак, у нас есть файл данных, который состоит из семи интервальных переменных, обозначающих оценки качества работы наземного персонала различных авиакомпаний (ql3-ql9), представленные в единой пятибалльной шкале. Файл данных содержит одновариантную переменную q4, указывающую выбранные респондентами авиакомпании (всего 22 наименования). Проведем кластерный анализ и определим, на какие целевые группы можно разделить данные авиакомпании.
Иерархический кластерный анализ проводится в два этапа. Результат первого этапа — число кластеров (целевых сегментов), на которые следует разделить исследуемую выборку респондентов. Процедура кластерного анализа как таковая не
может самостоятельно определить оптимальное число кластеров. Она может только подсказать искомое число. Поскольку задача определения оптимального числа сегментов является ключевой, она обычно решается на отдельном этапе анализа. На втором этапе производится собственно кластеризация наблюдений по тому числу кластеров, которое было определено в ходе первого этапа анализа. Теперь рассмотрим эти шаги кластерного анализа по порядку.
 |
Процедура кластерного анализа запускается при помощи меню Analyze ► Classify ► Hierarchical Cluster. В открывшемся диалоговом окне из левого списка всех имеющихся в файле данных переменных выберите переменные, являющиеся критериями сегментирования. В нашем случае их семь, и обозначают они оценки параметров работы наземного персонала ql3-ql9 (рис. 5.44). В принципе указания совокупности критериев сегментирования будет вполне достаточно для выполнения первого этапа кластерного анализа.
|
По умолчанию кроме таблицы с результатами формирования кластеров, на основании которой мы определим их оптимальное число, SPSS выводит также специальную перевернутую гистограмму icicle, помогающую, по замыслу создателей программы, определить оптимальное количество кластеров; вывод диаграмм осуществляется кнопкой Plots (рис. 5.45). Однако если оставить данный параметр установленным, мы потратим много времени на обработку даже сравнительно небольшого файла данных. Кроме icicle в окне Plots можно выбрать более быструю линейчатую диаграмму Dendogram. Она представляет собой горизонтальные столбики, отражающие процесс формирования кластеров. Теоретически при небольшом (до 50-100) количестве респондентов данная диаграмма действительно помогает выбрать оптимальное решение относительно требуемого числа кластеров. Однако практически во всех примерах из маркетинговых исследований размер выборки превышает это значение. Дендограмма становится совершенно бесполезной, так как даже при относительно небольшом числе наблюдений представляет собой очень длинную последовательность номеров строк исходного файла данных, соединенных между собой горизонтальными и вертикальными линиями. Большинство учебников по SPSS содержат примеры кластерного анализа именно на таких искусственных, малых выборках. В настоящем пособии мы показываем, как наиболее эффективно работать с SPSS в практических условиях и на примере реальных маркетинговых исследований.
 |
|
Как мы установили, для практических целей ни Icicle, ни Dendogram не пригодны. Поэтому в главном диалоговом окне Hierarchical Cluster Analysis рекомендуется не выводить диаграммы, отменив выбранный по умолчанию параметр Plots в области Display, как показано на рис. 5.44. Теперь все готово для выполнения первого этапа кластерного анализа. Запустите процедуру, щелкнув на кнопке ОК.
Через некоторое время в окне SPSS Viewer появятся результаты. Как было сказано выше, единственным значимым для нас итогом первого этапа анализа будет таблица Average Linkage (Between Groups), представленная на рис. 5.46. На основании этой таблицы мы должны определить оптимальное число кластеров. Необходимо заметить, что единого универсального метода определения оптимального числа кластеров не существует. В каждом конкретном случае исследователь должен сам определить это число.
Исходя из имеющегося опыта, автор предлагает следующую схему данного процесса. Прежде всего, попробуем применить наиболее распространенный стандартный метод для определения числа кластеров. По таблице Average Linkage (Between Groups) следует определить, на каком шаге процесса формирования кластеров (колонка Stage) происходит первый сравнительно большой скачок коэффициента агломерации (колонка Coefficients). Данный скачок означает, что до него в кластеры объединялись наблюдения, находящиеся на достаточно малых расстояниях друг от друга (в нашем случае респонденты со схожим уровнем оценок по анализируемым параметрам), а начиная с этого этапа происходит объединение более далеких наблюдений.
В нашем случае коэффициенты плавно возрастают от 0 до 7,452, то есть разница между коэффициентами на шагах с первого по 728 была мала (например, между 728 и 727 шагами — 0,534). Начиная с 729 шага происходит первый существенный скачок коэффициента: с 7,452 до 10,364 (на 2,912). Шаг, на котором происходит первый скачок коэффициента, — 729. Теперь, чтобы определить оптимальное ко-
личество кластеров, необходимо вычесть полученное значение из общего числа наблюдений (размера выборки). Общий размер выборки в нашем случае составляет 745 человек; следовательно, оптимальное количество кластеров составляет 745-729 = 16.
 |
|
Мы получили достаточно большое число кластеров, которое в дальнейшем будет сложно интерпретировать. Поэтому теперь следует исследовать полученные кластеры и определить, какие из них являются значимыми, а какие нужно попытаться сократить. Данная задача решается на втором этапе кластерного анализа.
Откройте главное диалоговое окно процедуры кластерного анализа (меню Analyze ► Classify ► Hierarchical Cluster). В поле для анализируемых переменных у нас уже есть семь параметров. Щелкните на кнопке Save. Открывшееся диалоговое окно (рис. 5.47) позволяет создать в исходном файле данных новую переменную, распределяющую респондентов на целевые группы. Выберите параметр Single Solution и укажите в соответствующем поле необходимое количество кластеров — 16 (определено на первом этапе кластерного анализа). Щелкнув на кнопке Continue, вернитесь в главное диалоговое окно, в котором щелкните на кнопке ОК, чтобы запустить процедуру кластерного анализа.
Прежде чем продолжить описание процесса кластерного анализа, необходимо привести краткое описание других параметров. Среди них есть как полезные возможности, так и фактически лишние (с точки зрения практических маркетинговых исследований). Так, например, главное диалоговое окно Hierarchial Cluster Analysis содержит поле Label Cases by, в которое при желании можно поместить текстовую переменную, идентифицирующую респондентов. В нашем случае для этих целей может служить переменная q4, кодирующая выбранные респондентами авиакомпании. На практике сложно придумать рациональное объяснение использованию поля Label Cases by, поэтому можно спокойно всегда оставлять его пустым.
 |
|
Нечасто при проведении кластерного анализа используется диалоговое окно Statistics, вызываемое одноименной кнопкой в главном диалоговом окне. Оно позволяет организовать вывод в окне SPSS Viewer таблицы Cluster Membership, в которой каждому респонденту в исходном файле данных сопоставляется номер кластера. Данная таблица при достаточно большом количестве респондентов (практически во всех примерах маркетинговых исследований) становится совершенно бесполезной, так как представляет собой длинную последовательность пар значений «номер респондента/номер кластера», в таком виде не поддающуюся интерпретации. Технически цель кластерного анализа всегда состоит в образовании в файле данных дополнительной переменной, отражающей разделение респондентов на целевые группы (при помощи щелчка на кнопке Save в главном диалоговом окне кластерного анализа). Эта переменная в совокупности с номерами респондентов и есть таблица Cluster Membership. Единственный практически полезный параметр в окне Statistics — вывод таблицы Average Linkage (Between Groups), однако он уже установлен по умолчанию. Таким образом, использование кнопки Statistics и вывод отдельной таблицы Cluster Membership в окне SPSS Viewer является нецелесообразным.
Про кнопку Plots уже было сказано выше: ее следует дезактивизировать, отменив параметр Plots в главном диалоговом окне кластерного анализа.
Кроме этих редко используемых возможностей процедуры кластерного анализа, SPSS предлагает и весьма полезные параметры. Среди них прежде всего кнопка Save, позволяющая создать в исходном файле данных новую переменную, распределяющую респондентов по кластерам. Также в главном диалоговом окне существует область для выбора объекта кластеризации: респондентов или переменных. Об этой возможности говорилось выше в разделе 5.4. В первом случае кластерный анализ используется в основном для сегментирования респондентов по некоторым критериям; во втором цель проведения кластерного анализа аналогична факторному анализу: классификация (сокращение числа) переменных.
Как видно из рис. 5.44, единственной не рассмотренной возможностью кластерного анализа является кнопка выбора метода проведения статистической процедуры Method. Эксперименты с данным Параметром позволяют добиться большей точности при определении оптимального числа кластеров. Общий вид этого диалогового окна с параметрами, установленными по умолчанию, представлен на рис. 5.48.
|
 |
Первое, что устанавливается в данном окне, — это метод формирования кластеров (то есть объединения наблюдений). Среди всех возможных вариантов статистических методик, предлагаемых SPSS, следует выбирать либо установленный по умолчанию метод Between-groups linkage, либо процедуру Ward (Ward's method). Первый метод используется чаще ввиду его универсальности и относительной простоты статистической процедуры, на которой он основан. При использовании этого метода расстояние между кластерами вычисляется как среднее значение расстояний между всеми возможными парами наблюдений, причем в каждой итерации принимает участие одно наблюдение из одного кластера, а второе — из другого. Информация, необходимая для расчетов расстояния между наблюдениями, находится на основании всех теоретически возможных пар наблюдений. Метод Ward более сложен для понимания и используется реже. Он состоит из множества этапов и основан на усреднении значений всех переменных для каждого наблюдения и последующем суммировании квадратов расстояний от вычисленных средних до каждого наблюдения. Для решения практических задач маркетинговых исследований мы рекомендуем всегда использовать метод Between-groups linkage, установленный по умолчанию.
После выбора статистической процедуры кластеризации следует выбрать метод для вычисления расстояний между наблюдениями (область Measure в диалоговом окне Method). Существуют различные методы определения расстояний для трех типов переменных, участвующих в кластерном анализе (критериев сегментирования). Эти переменные могут иметь интервальную (Interval), номинальную (Counts) или дихотомическую (Binary) шкалу. Дихотомическая шкала (Binary) подразумевает только переменные, отражающие наступление/ненаступление какого-либо события (купил/не купил, да/нет и т. д.). Другие типы дихотомических переменных (например, мужчина/женщина) следует рассматривать и анализировать как номинальные (Counts).
Наиболее часто используемым методом определения расстояний для интервальных переменных является квадрат евклидова расстояния (Squared Euclidean Distance), устанавливаемый по умолчанию. Именно этот метод зарекомендовал себя в маркетинговых исследованиях как наиболее точный и универсальный. Однако для дихотомических переменных, где наблюдения представлены только двумя значениями (например, 0 и 1), данный метод не подходит. Дело в том, что он учитывает только взаимодействия между наблюдениями типа: X = 1,Y = 0 и X = 0, Y=l (где X и Y — переменные) и не учитывает другие типы взаимодействий. Наиболее комплексной мерой расстояния, учитывающей все важные типы взаимодействий между двумя дихотомическими переменными, является метод Лямбда (Lambda). Мы рекомендуем применять именно данный метод ввиду его универсальности. Однако существуют и другие методы, например Shape, Hamann или Anderbergs's D.
При указании метода определения расстояний для дихотомических переменных в соответствующем поле необходимо указать конкретные значения, которые могут принимать исследуемые дихотомические переменные: в поле Present — кодировку ответа Да, а в поле Absent — Нет. Названия полей присутствует и отсутствует ассоциированы с тем, что в группе методов Binary предполагается использовать только дихотомические переменные, отражающие наступление/ненаступление какого-либо события. Для двух типов переменных Interval и Binary существует несколько методов определения расстояния. Для переменных с номинальным типом шкалы SPSS предлагает всего два метода: 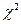 (Chi-square measure) и
(Chi-square measure) и 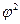 (Phi-square measure). Мы рекомендуем использовать первый метод как наиболее распространенный.
(Phi-square measure). Мы рекомендуем использовать первый метод как наиболее распространенный.
В диалоговом окне Method есть область Transform Values, в которой находится поле Standardize. Данное поле применяется в том случае, когда в кластерном анализе принимают участие переменные с различным типом шкалы (например, интервальные и номинальные). Для того чтобы использовать эти переменные в кластерном анализе, следует провести стандартизацию, приводящую их к единому типу шкалы — интервальному. Самым распространенным методом стандартизации переменных является 2-стандартизация (Zscores): все переменные приводятся к единому диапазону значений от -3 до +3 и после преобразования являются интервальными.
Так как все оптимальные методы (кластеризации и определения расстояний) установлены по умолчанию, целесообразно использовать диалоговое окно Method только для указания типа анализируемых переменных, а также для указания необходимости произвести 2-стандартизацию переменных.
Итак, мы описали все основные возможности, предоставляемые SPSS для проведения кластерного анализа. Вернемся к описанию кластерного анализа, проводимого с целью сегментирования авиакомпаний. Напомним, что мы остановились на шестнадцатикластерном решении и создали в исходном файле данных новую переменную clul6_l, распределяющую все анализируемые авиакомпании по кластерам.
Чтобы установить, насколько верно мы определили оптимальное число кластеров, построим линейное распределение переменной clul6_l (меню Analyze ► Descriptive Statistics ► Frequencies). Как видно на рис. 5.49, в кластерах с номерами 5-16 число респондентов составляет от 1 до 7. Наряду с вышеописанным универсальным методом определения оптимального количества кластеров (на основании разности между общим числом респондентов и первым скачком коэффициента агломерации) существует также дополнительная рекомендация: размер кластеров должен быть статистически значимым и практически приемлемым. При нашем размере выборки такое критическое значение можно установить хотя бы на уровне 10. Мы видим, что под данное условие попадают лишь кластеры с номерами 1-4. Поэтому
теперь необходимо пересчитать процедуру кластерного анализа с выводом четы-рехкластерного решения (будет создана новая переменная du4_l).
|
 |
Построив линейное распределение по вновь созданной переменной du4_l, мы увидим, что только в двух кластерах (1 и 2) число респондентов является практически значимым. Нам необходимо снова перестроить кластерную модель — теперь для двухкластерного решения. После этого построим распределение по переменной du2_l (рис. 5.50). Как вы видите из таблицы, двухкластерное решение имеет статистически и практически значимое число респондентов в каждом из двух сформированных кластеров: в кластере 1 — 695 респондентов; в кластере 2 — 40. Итак, мы определили оптимальное число кластеров для нашей задачи и провели собственно сегментирование респондентов по семи избранным критериям. Теперь можно считать основную цель нашей задачи достигнутой и приступать к завершающему этапу кластерного анализа — интерпретации полученных целевых групп (сегментов).
 |
|
Полученное решение несколько отличается от тех, которые вы, может быть, видели в учебных пособиях по SPSS. Даже в наиболее практически ориентированных учебниках приведены искусственные примеры, где в результате кластеризации получаются идеальные целевые группы респондентов. В некоторых случаях (5) авторы даже прямо указывают на искусственное происхождение примеров. В настоящем пособии мы применим в качестве иллюстрации действия кластерного анализа реальный пример из практического маркетингового исследования, не отличающийся идеальными пропорциями. Это позволит нам показать наиболее распространенные трудности проведения кластерного анализа, а также оптимальные методы их устранения.
Перед тем как приступить к интерпретации полученных кластеров, давайте подведем итоги. У нас получилась следующая схема определения оптимального числа кластеров.
■ На этапе 1 мы определяем количество кластеров на основании математического метода, основанного на коэффициенте агломерации.
■ На этапе 2 мы проводим кластеризацию респондентов по полученному числу кластеров и затем строим линейное распределение по образованной новой переменной (clul6_l). Здесь также следует определить, сколько кластеров состоят из статистически значимого количества респондентов. В общем случае рекомендуется устанавливать минимально значимую численность кластеров на уровне не менее 10 респондентов.
■ Если все кластеры удовлетворяют данному критерию, переходим к завершающему этапу кластерного анализа: интерпретации кластеров. Если есть кластеры с незначимым числом составляющих их наблюдений, устанавливаем, сколько кластеров состоят из значимого количества респондентов.
■ Пересчитываем процедуру кластерного анализа, указав в диалоговом окне Save число кластеров, состоящих из значимого количества наблюдений.
■ Строим линейное распределение по новой переменной.
Такая последовательность действий повторяется до тех пор, пока не будет найдено решение, в котором все кластеры будут состоять из статистически значимого числа респондентов. После этого можно переходить к завершающему этапу кластерного анализа — интерпретации кластеров.
Необходимо особо отметить, что критерий практической и статистической значимости численности кластеров не является единственным критерием, по которому можно определить оптимальное число кластеров. Исследователь может самостоятельно, на основании имеющегося у него опыта предложить число кластеров (условие значимости должно удовлетворяться). Другим вариантом является довольно распространенная ситуация, когда в целях исследования заранее ставится условие сегментировать респондентов по заданному числу целевых групп. В этом случае необходимо просто один раз провести иерархический кластерный анализ с сохранением требуемого числа кластеров и затем пытаться интерпретировать то, что получится.
Для того чтобы описать полученные целевые сегменты, следует воспользоваться процедурой сравнения средних значений исследуемых переменных (кластерных центроидов). Мы сравним средние значения семи рассматриваемых критериев сегментирования в каждом из двух полученных кластеров.
Процедура сравнения средних значений вызывается при помощи меню Analyze ► Compare Means ► Means. В открывшемся диалоговом окне (рис. 5.51) из левого списка выберите семь переменных, избранных в качестве критериев сегментирования (ql3-ql9), и перенесите их в поле для зависимых переменных Dependent List. Затем переменную сШ2_1, отражающую разделение респондентов на кластеры при окончательном (двухкластерном) решении задачи, переместите из левого списка в поле для независимых переменных Independent List. После этого щелкните на кнопке Options.
|
 |
 |
Откроется диалоговое окно Options, выберите в нем необходимые статистики для сравнения кластеров (рис. 5.52). Для этого в поле Cell Statistics оставьте только вывод средних значений Mean, удалив из него другие установленные по умолчанию статистики. Закройте диалоговое окно Options щелчком на кнопке Continue. Наконец, из главного диалогового окна Means запустите процедуру сравнения средних значений (кнопка ОК).
|
В открывшемся окне SPSS Viewer появятся результаты работы статистической процедуры сравнения средних значений. Нас интересует таблица Report (рис. 5.53). Из нее можно увидеть, на каком основании SPSS разделила респондентов на два кластера. Таким критерием в нашем случае служит уровень оценок по анализируемым параметрам. Кластер 1 состоит из респондентов, для которых средние оценки по всем критериям сегментирования находятся на сравнительно высоком уровне (4,40 балла и выше). Кластер 2 включает респондентов, оценивших рассматриваемые критерии сегментирования достаточно низко (3,35 балла и ниже). Таким образом, можно сделать вывод о том, что 93,3 % респондентов, сформировавшие кластер 1, оценили анализируемые авиакомпании по всем параметрам в целом хорошо; 5,4 % — достаточно низко; 1,3 % — затруднились ответить (см. рис. 5.50). Из рис. 5.53 можно также сделать вывод о том, какой уровень оценок для каждого из рассматриваемых параметров в отдельности является высоким, а какой — низким (причем данный вывод будет сделан со стороны респондентов, что позволяет добиться высокой точности классификации). Из таблицы Report можно видеть, что для переменной Регулирование очереди высоким считается уровень средней оценки 4,40, а для параметра Внешний вид — 4.72.

|
Может оказаться, что в аналогичном случае по параметру X высокой оценкой считается 4,5, а по параметру Y — только 3,9. Это не будет ошибкой кластеризации, а напротив, позволит сделать важный вывод относительно значимости для респондентов рассматриваемых параметров. Так, для параметра Y уже 3,9 балла является хорошей оценкой, тогда как к параметру X респонденты предъявляют более строгие требования.
Мы идентифицировали два значимых кластера, различающиеся по уровню средних оценок по критериям сегментирования. Теперь можно присвоить метки полученным кластерам: для 1 — Авиакомпании, удовлетворяющие требованиям респондентов (по семи анализируемым критериям); для 2 — Авиакомпании, не удовлетворяющие требованиям респондентов. Теперь можно посмотреть, какие конкретно авиакомпании (закодированные в переменной q4) удовлетворяют требованиям респондентов, а какие — нет по критериям сегментирования. Для этого следует построить перекрестное распределение переменной q4 (анализируемые авиакомпании) в зависимости от кластеризующей переменной clu2_l. Результаты такого перекрестного анализа представлены на рис. 5.54.
|
 |
По этой таблице можно сделать следующие выводы относительно членства исследуемых авиакомпаний в выделенных целевых сегментах.
1. Авиакомпании, полностью удовлетворяющие требованиям всех клиентов по параметру работы наземного персонала (входят только в один первый кластер):
■ Внуковские авиалинии;
■ American Airlines;
■ Continental;
■ Delta Airlines;
■ Air France;
■ Alitalia;
■ Austrian Airlines;
■ British Airways;
■ Swiss Air;
■ KLM;
■ Lufthansa;
■ SAS;
■ Korean Airlines;
■ Japan Airlines.
2. Авиакомпании, удовлетворяющие требованиям большинства своих клиентов по параметру работы наземного персонала (большая часть респондентов, летающих данными авиакомпаниями, удовлетворены работой наземного персонала):
■ Трансаэро.
3. Авиакомпании, не удовлетворяющие требованиям большинства своих клиентов по параметру работы наземного персонала (большая часть респондентов, летающих данными авиакомпаниями, не удовлетворены работой наземного персонала):
■ Домодедовские авиалинии;
■ Пулково;
■ Сибирь;
■ Уральские авиалинии;
■ Самарские авиалинии;
■ KrasAir;
■ Finnair.
Таким образом, получено три целевых сегмента авиакомпаний по уровню средних оценок, характеризующиеся различной степенью удовлетворенности респондентов работой наземного персонала:
1. наиболее привлекательные для пассажиров авиакомпании по уровню работы наземного персонала (14);
2. скорее привлекательные авиакомпании (1);
3. скорее непривлекательные авиакомпании (7).
Мы успешно завершили все этапы кластерного анализа и сегментировали авиакомпании по семи выделенным критериям.
Теперь приведем описание методики кластерного анализа в паре с факторным. Используем условие задачи из раздела 5.2.1 (факторный анализ). Как уже было сказано, в задачах сегментирования при большом числе переменных целесообразно предварять кластерный анализ факторным. Это делается для сокращения количества критериев сегментирования до наиболее значимых. В нашем случае в исходном файле данных у нас есть 24 переменные. В результате факторного анализа нам удалось сократить их число до 5. Теперь это число факторов может эффективно применяться для кластерного анализа, а сами факторы — использоваться в качестве критериев сегментирования.
Если перед нами стоит задача сегментировать респондентов по их оценке различных аспектов текущей конкурентной позиции авиакомпании X, можно провести иерархический кластерный анализ по выделенным пяти критериям (переменные nfacl_l-nfac5_l). В нашем случае переменные оценивались по разным шкалам. Например, оценка 1 для утверждения Я бы не хотел, чтобы авиакомпания менялась и такая же оценка утверждению Изменения в авиакомпании будут позитивным моментом диаметрально противоположны по смыслу. В первом случае 1 балл (совершенно не согласен) означает, что респондент приветствует изменения в авиакомпании; во втором случае оценка в 1 балл свидетельствует о том, что респондент отвергает изменения в авиакомпании. При интерпретации кластеров у нас неизбежно возникнут трудности, так как такие противоположные по смыслу переменные могут
попасть в один и тот же фактор. Таким образом, для целей сегментирования рекомендуется сначала привести в соответствие шкалы исследуемых переменных, а затем пересчитать факторную модель. И уже далее проводить кластерный анализ над полученными в результате факторного анализа переменными-факторами. Мы не будем снова подробно описывать процедуры факторного и кластерного анализа (это было сделано выше в соответствующих разделах). Отметим лишь, что при такой методике в результате у нас получилось три целевые группы авиапассажиров, различающихся по уровню оценок выделенным факторам (то есть группам переменных): низшая, средняя и высшая.
Весьма полезным применением кластерного анализа является разделение на группы частотных таблиц. Предположим, у нас есть линейное распределение ответов на вопрос Какие марки антивирусов установлены в Вашей организации?. Для формирования выводов по данному распределению необходимо разделить марки антивирусов на несколько групп (обычно 2-3). Чтобы разделить все марки на три группы (наиболее популярные марки, средняя популярность и непопулярные марки), лучше всего воспользоваться кластерным анализом, хотя, как правило, исследователи разделяют элементы частотных таблиц на глаз, основываясь на субъективных соображениях. В противоположность такому подходу кластерный анализ позволяет научно обосновать выполненную группировку. Для этого следует ввести значения каждого параметра в SPSS (эти значения целесообразно выражать в процентах) и затем выполнить кластерный анализ для этих данных. Сохранив кластерное решение для необходимого количества групп (в нашем случае 3) в виде новой переменной, мы получим статистически обоснованную группировку.
Заключительную часть этого раздела мы посвятим описанию применения кластерного анализа для классификации переменных и сравнения его результатов с результатами факторного анализа, проведенного в разделе 5.2.1. Для этого мы вновь воспользуемся условием задачи про оценку текущей позиции авиакомпании X на рынке авиаперевозок. Методика проведения кластерного анализа практически полностью повторяет описанную выше (когда сегментировались респонденты).
Итак, в исходном файле данных у нас есть 24 переменные, описывающие отношение респондентов к различным аспектам текущей конкурентной позиции авиакомпании X. Откройте главное диалоговое окно Hierarchical Cluster Analysis и поместите 24 переменные (ql-q24) в поле Variable(s), рис. 5.55. В области Cluster укажите, что вы классифицируете переменные (отметьте параметр Variables). Вы увидите, что кнопка Save стала недоступна — в отличие от факторного, в кластерном анализе нельзя сохранить факторные рейтинги для всех респондентов. Откажитесь от вывода диаграмм, дезактивизировав параметр Plots. На первом этапе вам не нужны другие параметры, поэтому просто щелкните на кнопке О К, чтобы запустить процедуру кластерного анализа.
В окне SPSS Viewer появилась таблица Agglomeration Schedule, по которой мы определили оптимальное число кластеров описанным выше методом (рис. 5.56). Первый скачок коэффициента агломерации наблюдается на 20 шаге (с 18834,000 до 21980,967). Исходя из общего числа анализируемых переменных, равного 24, можно вычислить оптимальное число кластеров: 24 - 20 = 4.
|
 |
|
При классификации переменных практически и статистически значимым является кластер, состоящий всего из одной переменной. Поэтому, поскольку мы получили приемлемое число кластеров математическим методом, проведение дальнейших проверок не требуется. Вместо этого снова откройте главное диалоговое окно кластерного анализа (все данные, использованные на предыдущем этапе, сохранились) и щелкните на кнопке Statistics, чтобы организовать вывод классификационной таблицы. Вы увидите одноименное диалоговое окно, где необходимо указать число кластеров, на которое необходимо разделить 24 переменные (рис. 5.57). Для этого выберите параметр Single solution и в соответствующем поле укажите требуемое число кластеров: 4. Теперь закройте диалоговое окно Statistics щелчком на кнопке Continue и из главного окна кластерного анализа запустите
 |
процедуру на выполнение.
|
В результате в окне SPSS Viewer появится таблица Cluster Membership, распределяющая анализируемые переменные на четыре кластера (рис. 5.58).
|
 |
По данной таблице можно отнести каждую рассматриваемую переменную в определенный кластер следующим образом.
Дата добавления: 2015-04-25; просмотров: 1331;