Коррекция нерепрезентативности выборки
В практике маркетинговых исследований случается, что собранные в ходе опроса данные не соответствуют параметрам генеральной совокупности (то есть являются нерепрезентативными). Такие ситуации возникают, если заложенные перед началом исследования социально-демографические квоты были искажены в результате нарушения методологии проведения исследования, ошибок в работе интервьюеров или недостаточного контроля проведения полевых работ.
Например, в результате проведения контрольных мероприятий после завершения основных полевых работ были выявлены многочисленные факты некорректного заполнения анкет интервьюерами или даже фальсификация анкет, вследствие чего из итоговой базы данных пришлось удалить некоторую часть анкет. Очевидно, что в этом случае социально-демографические квоты, заложенные в начале исследования и обеспечивающие соответствие параметров выборки параметрам общей генеральной совокупности (репрезентативность), скорее всего, изменятся. Это в свою очередь приведет к тому, что выводы, основанные на результатах проведенного опроса, не могут быть отнесены к генеральной совокупности. То есть мы не можем утверждать, что наши выводы действительно отражают мнение реальных потребителей. Исследование фактически теряет свой смысл.
Если полученная выборка является нерепрезентативной, применяется метод коррекции параметров выборки путем взвешивания. Приведем пример. Известно, что доля мужчин всего населения России составляет 45,5 %. В результате проведения всероссийского исследования оказалось, что доля мужчин в выборке составляет 72,1 %. Следовательно, полученная выборка является нерепрезентативной. Для устранения ошибки следует провести взвешивание, то есть скорректировать полученные значения переменной Пол (dl) на весовой коэффициент. Данный коэффициент рассчитывается для каждой социально-демографической группы по следующей формуле:
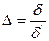
где 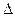 — весовой коэффициент;
— весовой коэффициент; 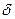 — значение исследуемого параметра в генеральной совокупности;
— значение исследуемого параметра в генеральной совокупности; 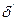 — значение исследуемого параметра в выборке.
— значение исследуемого параметра в выборке.
В нашем случае весовой коэффициент должен рассчитываться для двух социально-демографических групп: мужчин и женщин. (Если у вас большое количество групп, весовой коэффициент следует рассчитывать для каждой группы.) Для мужчин А будет равна: 45,5 % / 72,1 % ≈0,63. Так как у нас всего две группы, подлежащие взвешиванию (мужчины и женщины), то весовой коэффициент для женщин будет рассчитан так: (100 % - 45,5 %) / (100 % - 72,1 %) = 54,5 % / 27,9 « 1,95. (Если у вас большое количество групп, подлежащих взвешиванию, вам нужно знать значения параметров генеральной совокупности для каждой из групп.)
Итак, на первом этапе мы получили весовые коэффициенты, которые помогут нам скорректировать полученную нерепрезентативную выборку. Теперь необходимо создать новую переменную в файле данных SPSS, которая будет содержать для каждого респондента его вес (то есть для мужчин — 0,63, а для женщин — 1,95). Проще всего перекодировать с образованием новой переменной (как было описано в разделе 1.5.3.2).
В настоящем пособии мы не описываем важный элемент SPSS — программный синтаксис. Данный элемент является альтернативой использованию диалоговых окон в SPSS. Другими словами, все то, что можно сделать при помощи мыши в диалоговых окнах (и многое другое), можно выполнить посредством программного синтаксиса. В некоторых случаях его использование является предпочтительным. В частности, в нашем примере для создания новой весовой переменной удобнее воспользоваться синтаксисом. Откройте редактор синтаксиса File ► New ► Syntax. На экране появится окно, показанное на рис. 1.30. Введем в нем следующие команды:
if dl=l weight=45.5/72.1 .
if dl=2 weight=54.5/27.9 .
exe .
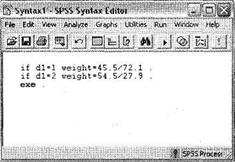 |
Обратите внимание, что в синтаксисе SPSS символ, отделяющий целую и дробную части числа, — всегда точка, а не запятая. Также следует внимательно относиться к точкам в конце каждой строки. Эти точки дают понять интерпретатору SPSS, что следует выполнить данную команду. Последовательность символов ехе. на третьей строке запускает процедуру синтаксиса. Рекомендуется использовать не приблизительные значения весовых коэффициентов (0,63 и 1,95), а вычисляемые выражения (45.5/72.1 и 54.5/27.9); что обеспечивает точность расчетов. После того как вы введете указанные строки в редакторе синтаксиса (см. рис. 1.30), выделите их все (это очень важно) и затем нажмите Ctrl+R или на кнопке ► на панели инструментов окна синтаксиса.
В результате работы процедуры синтаксиса будет создана новая переменная weight, содержащая весовые коэффициенты для каждого респондента. Теперь осталось только провести собственно процедуру взвешивания каждого респондента на его весовой коэффициент. В этом вам поможет диалоговое окно Weight Cases (Data ► Weight Cases). В данном диалоговом окне (рис. 1.31) следует выбрать параметр Weight cases by, затем в левом списке всех доступных переменных выбрать весовую переменную (в нашем случае weight) и перенести ее в поле Frequency variable, при щелчке на кнопке ОК база данных будет скорректирована на весовые коэффициенты, и репрезентативность данных будет восстановлена. Для отмены взвешивания следует в данном диалоговом окне установить переключатель в положение Do not weight cases.
 |
|
Если искажение квот в выборке произошло не только по одной социально-демографической переменной, а сразу по нескольким (например, не только по полу, но и по возрасту и уровню образования), следует сначала создать отдельные весовые переменные для каждой из искаженных социально-демографических переменных, а затем создать новую общую весовую переменную, которая будет произведением всех отдельных весовых коэффициентов (то есть для каждого респондента: вес по полу, вес по возрасту, вес по образованию).
При всей кажущейся простоте корректировки репрезентативности при помощи взвешивания следует иметь в виду, что для использования данного метода существуют серьезные ограничения. Например, часто число респондентов во взвешенной базе данных оказывается иным, чем в невзвешенной. Это происходит из-за того, что сумма весовых коэффициентов по всем респондентам не равна общему количеству респондентов. Также нужно весьма осторожно подходить к интерпретации статистических тестов по взвешенной базе. Поскольку число респондентов с определенными социально-демографическими характеристиками во взвешенной базе искусственно увеличивается (в нашем случае это доля женщин), рассчитанная статистическая значимость является некорректной. Таким образом, взвешивание рекомендуется проводить для построения общих (линейных) распределений.
Итак, в главе 1 мы подробно рассмотрели часто используемые в маркетинговых исследованиях методы манипуляции с данными. SPSS содержит массу других дополнительных возможностей, но в данном пособии мы не стали их приводить, поскольку на практике эти методы не находят широкого применения.
Дата добавления: 2015-04-25; просмотров: 1020;