Модель семантических сетей
Семантические сети представляют собой ориентированные графы с помеченными дугами. Аппарат семантических сетей является естественной формализацией ассоциативных связей, которыми пользуется человек при извлечении каких-то новых фактов из имеющихся. Построение сети способствует осмыслению информации и знаний, поскольку позволяет установить противоречивые ситуации, недостаточность имеющейся информации и т. п.
Обычно в семантической сети предусматриваются четыре категории вершин:
- понятия (объекты),
- события,
- свойства,
- значения.
Понятия представляют собой константы или параметры, которые определяют физические или абстрактные объекты.
События представляют действия, происходящие в реальном мире, и определяются указанием типа действия и ролей, которые играют объекты в этом действии.
Свойства используются для представления состояния или для модификации понятий и событий.
Сведения семантической сети образуют сценарий, который является набором понятий, событий и причинно-следственных связей.
Необходимо различать вершины, обозначающие экземпляры объектов, и вершины, представляющие классы объектов. Например, Новиков - экземпляр типа Студент. В семантической сети экземпляр может принадлежать более чем одному классу (Новиков – и Студент, и Спортсмен).
В других моделях в отличие от семантической сети типы объектов указаны в схеме, а экземпляры объектов представлены значениями в базе данных. В семантической сети один и тотже экземпляр объекта может быть соотнесен с несколькими типами.
В синтаксических моделях (реляционной, сетевой или иерархической) для обеспечения такой связи потребуется дублирование информации об объекте.
Все семантические отношения предметной области можно разделить на следующие:
- лингвистические,
- логические,
- теоретико-множественные,
- квантификационные.
Лингвистические отношения бывают глагольные (время, вид, род, число, залог, наклонение) и атрибутивные (модификация, размер, форма).
Логические отношения подразделяются на конъюнкцию (и), дизъюнкцию (или), отрицание (не) и импликацию (если – то).
Теоретико-множественные отношения - это отношение подмножества, отношение части и целого, отношение множества и элемента.
Квантификационные отношения делятся на логические кванторы общности и существования («каждый», «все»), нелогические кванторы («много», «несколько») и числовые характеристики.
При установлении структуры понятий существуют две обязательные связи
1- связь "есть-нек" (от слов "есть некоторый"). Направлена от частного понятия к более общему и показывает принадлежность элемента к классу;
2- связь "есть-часть". Показывает, что объект содержит в своем составе разнородные компоненты (объекты), не подобные данному объекту.
Пример семантической сети для описания структуры понятия "юридическое лицо" приведен на следующем рисунке.
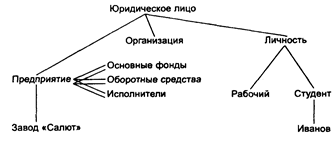
Рисунок 4.2 Элементы семантической сети
Связь "есть-нек" обозначается одной линией, связь "есть-часть" – двумя.
Рассмотрим представление событий и действий с помощью семантической сети. Выделяются простые отношения, которые характеризуют основные компоненты события. В первую очередь из события выделяется действие, которое обычно описывается глаголом. Далее необходимо определить объекты, которые действуют, объекты, над которыми эти действия производятся, и т. д. Все эти связи предметов, событий и качеств с глаголом называются падежами. Обычно рассматривают следующие падежи:
1. агент - предмет, являющийся инициатором действия;
2. объект - предмет, подвергающийся действию;
3. источник - размещение предмета перед действием;
4. приемник - размещение предмета после действия;
5. время - указание на то, когда происходит событие;
6. место - указание на то, где происходит событие;
7. цель - указание на цель действия.
Рассмотрим пример: Директор завода "САЛЮТ" остановил 25.03.90 цех № 4, чтобы заменить оборудование
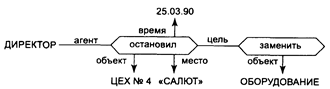
Рисунок 4.3 Пример семантической сети
Преимущества семантических сетей:
1) описание объектов и событий на уровне, очень близком к естественному языку;
2) обеспечивается возможность сцепления различных фрагментов сети;
3) возможные отношения между понятиями и событиями образуют достаточно небольшое и хорошо формализованное множество;
4) можно выделить из полной сети, представляющей все знания, некоторый участок семантической сети, который необходим в конкретном запросе.
4.4 Базы знаний
В современных системах управления вопрос о принятии решений информационной системой требует фиксации знаний об управляемом объекте и реализации моделей принятия решений, характерных для человека-специалиста (инженера, технолога, экономиста, бухгалтера). Способность человека накапливать и использовать знания, принимать решения можно назвать естественным интеллектом, соответствующие возможности информационной системы получили название искусственный интеллект.
Система понятий для представления знаний существенно отличается от понятий для представления данных, поэтому отображение знаний производится в базу знаний. Вместе с тем база знаний способна хранить данные как простую разновидность знаний.
Запросы, которые формулируются пользователями информационной системы, реализуются одним из двух возможных способов:
- сообщения, являющиеся ответом на запрос, хранятся в явном виде в БД, и процесс получения ответа представляет собой выделение подмножества значений из файлов БД, удовлетворяющих запросу;
- ответ не существует в явном виде в БД и формируется в процессе логического вывода на основании имеющихся данных.
Последний случай принципиально отличается от рассмотренной ранее технологии использования баз данных и рассматривается в рамках представления знаний, т. е. информации, необходимой в процессе вывода новых фактов. База знаний содержит:
- сведения, которые отражают существующие в предметной области закономерности и позволяют выводить новые факты, справедливые в данном состоянии предметной области, но отсутствующие в БД, а также прогнозировать потенциально возможные состояния предметной области;
- сведения о структуре ЭИС и БД (метаинформация);
- сведения, обеспечивающие понимание входного языка, т. е. перевод входных запросов во внутренний язык.
Принято говорить не о "знаниях вообще", а о знаниях, зафиксированных с помощью той или иной модели знаний.
Принципиальными различиями обладают три модели представления знаний - продукционная модель, модель фреймов и модель семантических сетей.
4.5 Продукционная модель знаний
Продукционная модель состоит из трех основных компонентов:
- набора правил, представляющего собой в продукционной системе базу знаний;
- рабочей памяти, в которой хранятся исходные факты и результаты выводов, полученных из этих фактов;
- механизма логического вывода, использующего правила ц соответствии с содержимым рабочей памяти и формирующего новые факты.
Каждое правило содержит условную и заключительную части. В условной части правила находится одиночный факт либо несколько фактов (условий), соединенных логической операцией "И".
В заключительной части правила находятся факты, которые необходимо дополнительно сформировать в рабочей памяти, если условная часть правила является истинной.
Пример
Предположим, что в рабочей памяти хранятся следующие факты:
-доля выборки записей равна 0,09;
- ЭВМ - PC XT.
Правила логического вывода имеют вид:
1) Если метод доступа индексный, то СУБД - dBASE 3.
2) Если метод доступа последовательный, то СУБД - dBASE 3.
3) Если доля выборки записей <0,1, то метод доступа - индексный.
4) Если СУБД - dBASE 3 и ЭВМ - PC XT, то программист -Иванов.
Механизм вывода сопоставляет факты из условной части каждого правила с фактами, хранящимися в рабочей памяти. В данном примере сопоставление условия правила 3 с фактами из рабочей памяти приводит к добавлению нового факта "Метод доступа - индексный" и исключению правила 3 из списка применяемых правил.
С учетом нового факта становится справедливой условная часть правила 1, и в рабочей памяти появляется факт "СУБД -dBASE З". Далее становится применимым правило 4, что приводит к фиксации в рабочей памяти факта "Программист - Иванов". В этот момент дальнейшее применение правил невозможно, и процесс вывода останавливается. Наш пример показывает, что применимость каждого правила из базы знаний в процессе вывода вовсе не обязательна.
Новые факты, полученные механизмом вывода:
- метод доступа - индексный,
-СУБД-dBASE 3,
- программист - Иванов.
В приведенном примере для получения вывода правила применялись к фактам, записанным в рабочей памяти, и в результате применения правил добавлялись новые факты. Такой способ действий называется прямым выводом. Возможен также обратный вывод целей. В качестве цели выступает подтверждение истинности факта, отсутствующего в рабочей памяти. При обратном выводе исследуется возможность применения правил, подтверждающих цель, необходимые для этого дополнительные факты становятся новыми целями и процесс повторяется.
Предположим, что в нашем примере запрос цели имеет вид:
? "программист - Иванов".
Эта цель подтверждается правилом 4. Необходимые для правила 4 факты - "ЭВМ - PC XT" и "СУБД - dBASE 3". Первыйизних присутствует в рабочей памяти, а второй становится новой целью. Для этой цели требуется подтверждение правила 1 или правила 2. Факт-условие правила 2 не содержится в рабочей памяти и не является заключением существующих правил. Поэтому данная ветвь обратного вывода обрывается. Для применения правила 1 необходим факт "Метод доступа - индексный", он является заключением правила 3, а условие правила 3 соблюдается (в рабочей памяти хранится факт "Доля выборки записей равна 0.09").
В итоге первоначальная цель "программист-Иванов" признается истинной.
В случае обратного вывода условием останова системы является окончание списка правил, которые относятся к доказываемым целям. При прямом выводе останов происходит по окончании списка применимых правил. Следует отметить, что на каждом шаге вывода количество одновременно применимых правил может быть любым (в отличие от примеров, приведенных выше). Последовательность выбора подходящих правил не влияет на однозначность получаемого ответа; однако может существенно увеличить требуемое число шагов вывода. В реальных базах знаний с большим числом правил это может существенно снизить быстродействие системы. В системах с обратным выводом есть возможность исключить из рассмотрения правила, не имеющие отношения к выводу требуемых целей, и тем самым несколько ослабить указанный отрицательный эффект. По этой причине системы с обратным выводом целей получили большее распространение.
Представление знаний в виде набора правил имеет следующие преимущества:
- простота создания и понимания отдельных правил;
- простота механизма логического вывода.
К недостаткам этого способа организации базы знаний относятся:
- неясность взаимных отношений правил;
- отличие от человеческой структуры знаний.
4.6 Фреймы
В основе теории фреймов лежит фиксация знаний путем сопоставления новых фактов с рамками, определенными для каждого объекта в сознании человека. Структура в памяти ЭВМ, представляющая эти рамки, называется фреймом. С помощью фреймовмы пытаемся представить процесс систематизации знаний в форме, максимально близкой к принципам систематизации знаний человеком.
Фрейм представляет собой таблицу, структура и принципы организации которой являются развитием понятия отношения в реляционной модели данных. Новизна фреймов определяется двумя условиями:
1) имя атрибута может в ряде случаев занимать в фрейме позицию значения,
2) значением атрибута может служить имя другого фрейма или имя программно реализованной процедуры. Структура фрейма показана ниже.
Слотом фрейма называется элемент данных, предназначенный для фиксации знаний об объекте, которому отведен данный фрейм. Перечислим параметры слотов.
Имя слота. Каждый слот должен иметь уникальное имя во фрейме, к которому он принадлежит. Имя слота в некоторых случаях может быть служебным. Среди служебных имен отметим имя пользователя, определяющего фрейм; дату определения или модификации фрейма; комментарий.
Указатель наследования. Он показывает, какую информацию об атрибутах слотов во фрейме верхнего уровня наследуют слоты с теми же именами во фрейме нижнего уровня. Приведем типичные указатели наследования:
S (тот же). Слот наследуется с теми же значениями данных;
U (уникальный). Слот наследуется, но данные могут принимать любые значения;
I (независимый). Слот не наследуется.
Указатель типа данных. К типам данных относятся:
FRAME (указатель) - указывает имя фрейма верхнего уровня;
ATOM (переменная),
TEXT (текстовая информация),
LIST (список),
LISP (присоединенная процедура).
С помощью механизма управления наследованием по отношениям "есть-нек" осуществляются автоматический поиск и определение значений слотов фрейма верхнего уровня и присоединенных процедур.
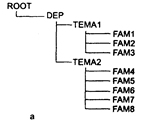
Рассмотримпример использования системы фреймов. Иерархия фреймов, показанная на рис. 4.4.а, отображает организационную структуру и работы, выполняемые в некотором отделе конструкторского бюро. Она предназначена для фиксации факта окончания отдельных работ исполнителями, группами и отделом в целом. Фрейм ROOT является стандартным фреймом, все другие фреймы должны быть подчинены ему. Слот АКО используется для установления иерархии фреймов.
Работа начинается посредством передачи сообщения в слот фрейма верхнего уровня DEP. При этом запускается присоединенная процедура, которая передает в фреймы нижнего уровня значение текущей даты. Когда происходит заполнение какого-то слота в фрейме, делается попытка дать значения всем слотам этого фрейма, в том числе попытка выполнения присоединенной процедуры.
Фреймовые системы обеспечивают ряд преимуществ по сравнению с продукционной моделью представления знаний:
1)знания организованы на основе концептуальных объектов;
2)допускается комбинация представления декларативных (как устроен объект) и процедурных (как взаимодействует объект) знаний;
3)иерархия фреймов вполне соответствует классификации понятий, привычной для восприятия человеком;
4)система фреймов легко расширяется и модифицируется.
Трудности применения фреймовой модели знаний в основном связаны с программированием присоединенных процедур.
| Имя слота | Указатель наследования | Указатель Типа | Значение слота |
| FRAME-NAME: DEP | |||
| АКО | (U) ROOT | FRAME ROOT | |
| DESINF | (U) ROOT | TEXT | (ОТДЕЛ 23) |
| DATE | (U) ROOT | LIST | |
| ТЕМА | (I) .TOP. | LIST | (TEMA1 ТЕМА2) |
| ТЕМА1 | (I) «TOP» | LIST | NIL |
| ТЕМА2 | (I) .TOP. | LIST | NIL |
| FLAG1 | (I) «TOP. | ATOM | |
| FLAG2 | (I) •TOP. | ATOM | |
| LOGIC | (U) «TOP. | LISP | MAIN |
| FRAME-NAME: TEMA1 | |||
| АКО | (U) ROOT | FRAME DEP | |
| DESINF | (U) ROOT | TEXT | (КОНСТРУИРОВАНИЕ ПЛЕЕРА) |
| DAE | (U) ROOT | LIST | |
| FAM | (I) «TOP. | LIST | (FAM1 FAM2 FAM3) |
| FAM1 | (I) •TOP» | LIST | NIL |
| FAM2 | (I) «TOP. | LIST | NIL |
| FAM3 | (I) •TOP. | LIST | NIL |
| FLAG1 | (1) .TOP* | ATOM | |
| FLAG2 | (1) «TOP» | ATOM | |
| FLAG3 | (1) •TOP» | ATOM | |
| LOGIC | (U) •TOP. | LISP | COMP1 |
| FRAME-NAME: FAM1 | |||
| AKO | (U) ROOT | FRAME TEMA1 | |
| DESINF | (U) ROOT | TEXT | (ЛЕНТОПРОТЯЖНЫЙ |
| МЕХАНИЗМ) | |||
| DATE | (U) ROOT | LIST | |
| TODAY | (1) «TOP» | ATOM | |
| ENDDATE | (1) .TOP. | ATOM | 02.04.91 |
| LOGIC | (U) .TOP» | LISP | COMPDATE |
Рисунок 4.4 Пример базы знаний фреймового типа:
а - иерархия фреймов; б - значения слотов
4.7 Семантические сети для представления знаний
Особенность семантической сети как модели знаний состоит в единстве базы знаний и механизма вывода новых фактов. На основании вопроса к базе знаний строится семантическая сеть, отображающая структуру вопроса, и ответ получается в результате сопоставления общей сети для базы знаний в целом и сети для вопроса.
Рассмотримпример семантической сети, отображающий подчиненность сотрудников в отделе учреждения, приведенный на рис. 35,а. Приводятся связи, показывающие подчиненность первого сотрудника. Остальные сотрудники отдела связываются через вершины сети связями типа "руководит 2", "руководит 3" и т. д.
Вопрос "Кто руководит Серовым?" представляется в виде подсети, показанной на рис. 4.5,б. Сопоставление общей сети с сетью запроса начинается с фиксации вершины "руководит", имеющей ветвь "объект", направленную к вершине "Серов". Затем производится переход по ветви "руководит", что и приводит к ответу "Петров"
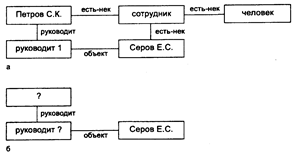
Рисунок 4.5 Примеры: а - семантической сети;
б - сети логического вывода для запроса
Преимущества семантических сетей состоят в том, что это достаточно понятный способ представления знаний на основе отношений между вершинами и дугами сети. Однако с увеличением размеров сети ухудшается се обозримость и увеличивается время вывода новых фактов с помощью механизма сопоставления.
Дата добавления: 2015-03-09; просмотров: 4889;