Последовательная организация данных.
При последовательной организации данных записи располагаются в памяти строго одна за другой, без промежутков, в той последовательности, в которой они обрабатываются. Записи массива могут быть упорядоченными или неупорядоченными по значениям ключевого атрибута.
а)Формирование данных.
Процедура упорядочения состоит из серии сравнений ключевых атрибутов и тех или иных перераспределений записей по результатам сравнения. Массив из М записей, обладающий неопределённостью состояния называется случайным массивом. Для него возможны М! состояний.
Таким образом, минимальное число сравнений, необходимое для упорядочения массива из М записей, определяется как С = log М!.
Справедлива запись выражения для времени сортировки Т ~ М • log М.
б) Поиск в последовательном массиве.
Поиском называется процедура выделения из некоторого множества записей определенного подмножества, записи которого удовлетворяют некоторому заранее поставленному условию. Условие поиска часто называют запросом на поиск.
Простейшим условием поиска является поиск по совпадению, т. е. равенство значения ключевого атрибута i-й записи p(i) и некоторого заранее заданного значения q..
Базовым методом доступа к массиву является ступенчатый поиск, он предполагает упорядоченность обрабатываемых записей. Простейшим вариантом одноступенчатого поиска является последовательный поиск. Искомое значение q сравнивается с ключом первой записи и последовательно с каждой последующей записью до совпадения. Количество сравнений С пропорционально М (С ~ М).
Для ускорения поиска используется двухступенчатый поиск в массиве. Для заданного М выбирается константа dl, называемая шагом поиска. Если необходимо отыскать запись со значением ключевого атрибута, равным q, производятся следующие действия. Значение q последовательно сравнивается с рядом величин р(1), p(l+dl), p(l+2*dl), ..., p(l+k*dl) до тех пор, пока будет впервые достигнуто неравенство p(l+m*dl)=>q. На второй ступени q последовательно сравнивается со всеми ключами найденного интервала
Эффективность поиска измеряется количеством произведенных сравнений. Для двухступенчатого поиска среднее число сравнений примерно составит:
C=M/(2*dl)+dl/2.
Ступенчатый поиск имеет важный частный вариант -бинарный поиск. Для бинарного поиска вводятся граница интервала поиска. Вычисляется середина интервала по формуле i=(A+B)/2, сравнивается с искомым значением, выбирается та половина, где находится искомое значение. Алгоритм повторяется. Количество вариантов поиска уменьшается в арифметической прогрессии. Среднее число сравнений при бинарном поиске составляет C=log(M) -1.
Определение лучшего метода поиска (из рассмотренных выше последовательного, двухступенчатого и бинарного) опирается на следующие рассуждения. Во всех трех случаях время поиска является функцией от числа записей М. Конкретные выражения составляют:
- для последовательного поиска Т1=k1*М;
- для двухступенчатого поиска T2~ k2*lnM;
- для бинарного поиска T3=k3*logM.

Рис. 3.1. Сравнение методов поиска данных в массиве
При больших массивах данных преимущество бинарного поиска, безусловно.
в) Корректировка последовательного массива
Включение и исключение записей по одиночке является длительной процедурой. Поэтому корректирование записи накапливаются в специальном массиве изменений, который составляет какой-то процент от основного массива. При необходимости обработки основного массива он объединяется с массивом изменений.
При объединении основного массива с массивом изменений выполняются следующие операции (алгоритм слияния):
-ключ очередной записи основного массива сравнивается с ключом очередной записи массива изменений, и запись с меньшим значением ключа добавляется в новый массив (результат слияния);
-когда все записи одного из массивов будут перезаписаны полностью, оставшиеся записи другого массива добавляются в результирующий массив, и алгоритм заканчивается.
Время корректировки Т ~М.
3.3 Цепная (списковая) организация данных
Списком называется множество записей, занимающих произвольные участки памяти, последовательность обработки которых задается с помощью адресов связи. Адресом связи некоторой записи называется атрибут, в котором хранится начальный адрес или номер записи, обрабатываемой после этой записи. Обычная последовательность обработки записей в списке определяется возрастанием значений ключа в записях.
В списке выделяется собственная информация и адреса связи.
Возможны два способа организации списка - совместное размещение информации, когда запись и ее адрес связи образуют одно целое (рис. 3.2 а), и раздельное, когда имеется списковая организация адресов связи и последовательное хранение собственной информации (рис. 3.2 ).
При списковой организации данных необходим специальный атрибут, называемый указателем списка, который содержит начальный адрес или номер первой в порядке обработки записи списка. Кроме того, адрес связи последней записи списка должен содержать специальное значение, называемое концом списка и отмечающее, что последующих записей у данной записи нет. Обычно конец списка отмечается нулем.
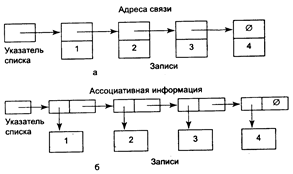
Рис. 3.2. Варианты списковой организации данных:
а - совместное хранение записей и адресов связи;
б - раздельное хранение записей и адресов связи (0 - конец списка)
а) При формировании упорядоченного списка записей возможны два варианта:
- вновь поступающие записи вставлять так, чтобы не нарушать упорядоченность по ключу;
- создать сначала неупорядоченный список, а затем отсортировать его.
Учитывая, что для сортировки можно использовать метод слияния, второй вариант следует признать более целесообразным.
В итоге время формирования упорядоченного списка пропорционально T=M*logM.
б)Для поискав упорядоченном списке можно использовать те же методы, что и в последовательном массиве, однако эффективность этих методов иная, поскольку адреса связи создают возможность быстрого доступа только к следующей записи списка.
Для поиска данных в однонаправленном списке используется единственный метод - последовательный поиск. Ключевой атрибут первой записи (ее адрес извлекается из указателя списка) сравнивается с искомым значением q, затем такое же сравнение выполняется для ключа второй записи, которая извлекается по адресу связи первой записи, и т. д. Время поиска, естественно, пропорционально Т~М.
Неэффективность бинарного поиска для списковой организации данных объясняется тем обстоятельством, что для достижения середины интервала требуется последовательное движение в соответствии с адресами связи и суммарное количество переходов от записи к записи достаточно велико. Для ускорения доступа к списку могут быть рекомендованы такие варианты использования адресов связи, как двунаправленный и кольцевой список (рис3.3):
двунаправленный список образован двумя цепочками адресов связи - от первой записи к последней и от последней записи к первой;
в кольцевом списке последний адрес связи указывает на первую запись.

Рисунок 3.3. Организация списков: а - двунаправленного; б - кольцевого
в) Корректировка данных. Цепной каталог
Цепным каталогом называется сплошной участок памяти (или несколько таких участков), в котором одновременно размещаются список обрабатываемых записей и список свободных позиций памяти. Адрес связи, отмечающий первую обрабатываемую запись, называется указателем списка. Адрес связи, отмечающий первую свободную позицию памяти, называется указателем свободной памяти. Адрес связи последней записи (или последней позиции свободной памяти) в списке называется концом списка, и здесь отмечается нулевым значением.
Включение и исключение записей в цепном каталоге предполагает поиск местоположения включаемой (исключаемой) записи и замену значений адресов связи для установления новой последовательности записей основного списка и списка свободной памяти.
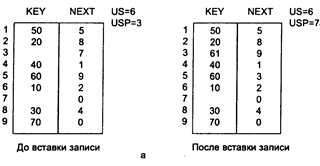

а - ставка записи с ключом 61; б - удаление записи с ключом 30
Рисунок 3.4. Операции корректировки в цепном каталоге
Оценка времени корректировки складывается из времени реализации поиска и времени на замену значений адресов связи. В последнем случае число пересылок адресов связи всегда одинаково и не зависит от числа записей в цепном каталоге, поэтому затраты времени на поиск при корректировке являются доминирующими и время корректировки пропорционально Т~М.
г) Объем дополнительной памяти пропорционален М для адресов связи.
Дата добавления: 2015-03-09; просмотров: 1132;