OLAP: оперативная аналитическая обработка данных.
В течение многих лет информационные технологии концентрировались на построении систем поддержки обработки корпоративных транзакций. Такие системы должны быть визуально отказоустойчивыми и обеспечивать быстрый отклик. Эффективное решение было обеспечено OLTP, которые сосредотачивались на распределенном реляционном окружении БД.
Более поздним достижением в этой области явилось добавление архитектуры клиент – сервер. Было издано много инструментов для развития OLTP приложений.
Доступ к данным часто требуется как OLTP приложениям, так и информационным системам поддержки решений. К сожалению, попытка обслужить оба типа запросов может быть проблематична. Поэтому некоторые компании избрали путь разделения БД на OLTP тип и OLAP тип.
OLAP (Online Analytical Processing – оперативная аналитическая обработка) – это информационный процесс, который дает возможность пользователю запрашивать систему, проводить анализ и т.д. в оперативном режиме (онлайн). Результаты генерируются в течении секунд.
С другой стороны, в OLTP системе огромные объемы данных обрабатываются так скоро, как они поступают на вход.
OLAP системы выполнены для конечных пользователей, в то время как OLTP системы делаются для профессиональных пользователей ИС. В OLAP предусмотрены такие действия, как генерация запросов, запросы нерегламентированных отчетов, проведение статистического анализа и построение мультимедийных приложений.
Для обеспечения OLAP необходимо работать с хранилищем данных (или многомерным хранилищем), а также с набором инструментальных средств, обычно с многомерными способностями. Этими средствами могут быть инструментарий запросов, электронные таблицы, средства добычи данных (Data Mining), средства визуализации данных и др.
В основе концепции OLAP лежит принцип многомерного представления данных. Э. Кодд рассмотрел недостатки реляционной модели, в первую очередь указав на невозможность объединять, просматривать и анализировать данные с точки зрения множественности измерений, то есть самым понятным для корпоративных аналитиков способом, и определил общие требования к системам OLAP, расширяющим функциональность реляционных СУБД и включающим многомерный анализ как одну из своих характеристик.
В большом числе публикаций аббревиатурой OLAP обозначается не только многомерный взгляд на данные, но и хранение самих данных в многомерной БД. Вообще говоря, это неверно, поскольку сам Кодд отмечает, что реляционные БД были, есть и будут наиболее подходящей технологией для хранения корпоративных данных. Необходимость существует не в новой технологии БД, а скорее, в средствах анализа, дополняющих функции существующих СУБД и достаточно гибких, чтобы предусмотреть и автоматизировать разные виды интеллектуального анализа, присущие OLAP.
По Кодду, многомерное концептуальное представление представляет собой множественную перспективу, состоящую из нескольких независимых измерений, вдоль которых могут быть проанализированы определенные совокупности данных. Одновременный анализ по нескольким измерениям определяется как многомерный анализ. Каждое измерение включает направления консолидации данных, состоящие из серии последовательных уровней обобщения, где каждый вышестоящий уровень соответствует большей степени агрегации данных по соответствующему измерению. Так измерение Исполнитель может определяться направлением консолидации, состоящим из уровней обобщения «предприятие – подразделение – отдел - служащий». Измерение Время может даже включать два направления консолидации – «год – квартал – месяц - день» и «неделя - день», поскольку счет времени по месяцам и по неделям несовместим. В этом случае становится возможным произвольный выбор желаемого уровня детализации информации по каждому из измерений. Операция спуска соответствует движению от высших ступеней консолидации к низшим; напротив, операция подъема означает движение от низших уровней к высшим.
Кодд определил 12 правил, которым должен удовлетворять программный продукт класса OLAP. Эти правила:
1. Многомерное концептуальное представление данных.
2. Прозрачность.
3. Доступность.
4. Устойчивая производительность.
5. Клиент – серверная архитектура.
6. Равноправие измерений.
7. Динамическая обработка разреженных матриц.
8. Поддержка многопользовательского режима.
9. Неограниченная поддержка кроссмерных операций.
10. Интуитивное манипулирование данными.
11. Гибкий механизм генерации отчетов.
12. Неограниченное количество измерений и уровней агрегации.
Набор этих требований, послуживший фактическим определением OLAP, следует рассматривать как рекомендательный, а конкретные продукт оценивать по степени приближения к идеально полному соответствию всем требованиям.
Интеллектуальный анализ данных.
Интеллектуальный анализ данных (ИАД), или Data Mining, - термин, используемый для описания открытия знаний в базах данных, выделения знаний, изыскания данных, исследования данных, обработки образцов данных, очистки и сбора данных; здесь же подразумевается сопутствующее ПО. Все эти действия осуществляются автоматически и позволяют получать быстрые результаты даже непрограммистам.
Запрос производится конечным пользователем, возможно на естественном языке. Запрос преобразуется в SQL – формат. SQL запрос по сети поступает в СУБД, которая управляет БД или хранилищем данных. СУБД находит ответ на запрос и доставляет его назад. Пользователь может затем разрабатывать презентацию или отчет в соответствии со своими требованиями.
Многие важные решения в почти любой области бизнеса и социально сферы основываются на анализе больших и сложных БД. ИАД может быть очень полезным в этих случаях.
Методы интеллектуального анализа данных тесно связаны с технологиями OLAP и технологиями построения хранилищ данных. Поэтому наилучшим вариантом является комплексный подход к их внедрению.
Для того чтобы существующие хранилища данных способствовали принятию управленческих решений, информация должна быть представлена аналитику в нужной форме, то есть он должен иметь развитые инструменты доступа к данным хранилища и их обработки.
Очень часто информационно – аналитические системы, создаваемые в расчете на непосредственное использование лицами, принимающими решения, оказываются чрезвычайно просты в применении, но жестко ограничены в функциональности. Такие статические системы называются Информационными системами руководителя. Они содержат в себе предопределенные множества запросов и, будучи достаточными для повседневного обзора, неспособны ответить на все вопросы к имеющимся данным, которые могут возникнуть при принятии решений. Результатов работы такой системы, как правило, являются многостраничные отчеты, после тщательного изучения которых у аналитика появляется новая серия вопросов. Однако каждый новый запрос, непредусмотренный при проектировании такой системы, должен быть сначала формально описан, закодирован программистом и только затем выполнен. Время ожидания в таком случае может составлять часы и дни, что не всегда приемлемо. Таким образом, внешняя простота статистических ИС поддержки решений, за которую активно борется большинство заказчиков информационно – аналитических систем, оборачивается потерей гибкости.
Динамические ИС поддержки решений, напротив, ориентированы на обработку нерегламентированных (ad hoc) запросов аналитиков к данным. Работа аналитиков с этими системами заключается в интерактивной последовательности формирования запросов и изучения их результатов.
Но динамические ИС поддержки решений могут действовать не только в области оперативной аналитической обработки (OLAP). Поддержка принятия управленческих решений на основе накопленных данных может выполняться в трех базовых сферах.
1. Сфера детализированных данных. Это область действия большинства систем, нацеленных на поиск информации. В большинстве случаев реляционные СУБД отлично справляются с возникающими здесь задачами. Общепризнанным стандартом языка манипулирования реляционными данными является SQL. Информационно – поисковые системы, обеспечивающие интерфейс конечного пользователя в задачах поиска детализированной информации, могут использоваться в качестве надстроек как над отдельными базами данных транзакционных систем, так и над общим хранилищем данных.
2. Сфера агрегированных показателей. Комплексный взгляд на собранную в хранилище данных информацию, ее обобщение и агрегация и многомерный анализ являются задачами систем OLAP. Здесь можно или ориентироваться на специальные многомерные СУБД, или оставаться в рамках реляционных технологий. Во втором случае заранее агрегированные данные могут собираться в БД звездообразного вида, либо агрегация информации может производится в процессе сканирования детализированных таблиц реляционной БД.
3. Сфера закономерностей. Интеллектуальная обработка производится методами интеллектуального анализа данных, главными задачами которых являются поиск функциональных и логических закономерностей в накопленной информации, построение моделей и правил, которые объясняют найденные аномалии и/или прогнозируют развитие некоторых процессов.
Полная структура информационно – аналитической системы построенной на основе хранилища данных, показана на рис.9.2. В конкретных реализациях отдельные компоненты этой схемы часто отсутствуют.
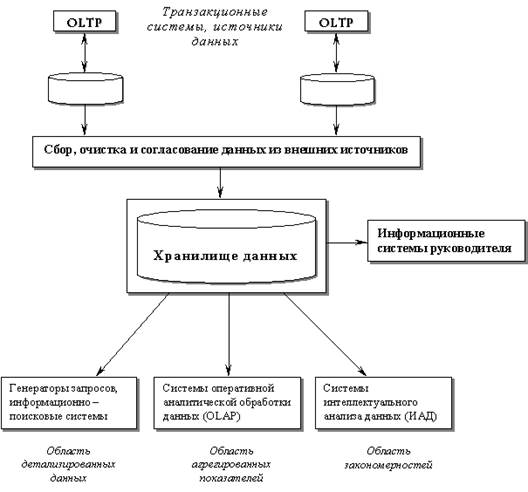
Рис.9.2. Структура корпоративной информационно – аналитической системы.
Дата добавления: 2015-02-16; просмотров: 3885;