Етапи логічного проектування
Логічне проектування виконується для певної моделі даних. Для реляційної моделі даних логічне проектування полягає у створенні реляційної схеми, визначенні числа і структури таблиць, формуванні запитів до БД, визначенні типів звітних документів, розробці алгоритмів обробки інформації, створенні форм для вводу і редагування даних в БД і рішенні цілого ряду інших задач. Концептуальні моделі за певними правилами перетворюються в логічні моделі даних. Коректність логічних моделей перевіряється за допомогою правил нормалізації, які дозволяють переконатися в структурній узгодженості, логічній цілісності і мінімальній збитковості прийнятої моделі даних. Модель також перевіряється з метою виявлення можливостей виконання транзакцій, які будуть задаватися користувачами.
Проектування являє собою циклічний процес. Етапи логічного проектування наведені на рис. 6.1.
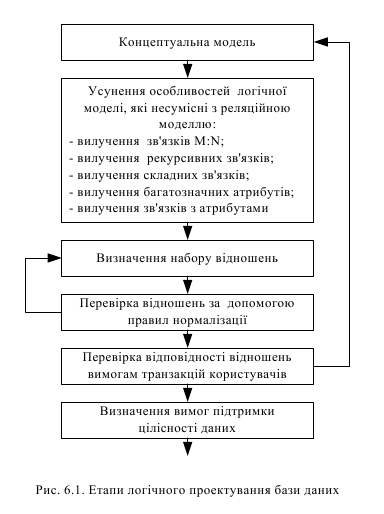
Першим кроком спрощення концептуальної моделі є попередні перетворення з метою усунення зв'язків, які є несумісними з реляційною моделлю.
На цьому етапі виконуються такі операції:
− вилучення двосторонніх зв'язків M:N;
− вилучення складних зв'язків;
− вилучення багатозначних атрибутів;
− вилучення рекурсивних зв'язків;
− вилучення зв'язків з атрибутами.
Перетворення зв’язку " багато до багатьох" виконується шляхом введення проміжної сутності із заміною одного зв'язку M:N двома зв'язками 1:N з новою сутністю.
Для вилучення складних зв'язків виконуються такі операції:
− у модель вводиться нова сутність;
− складний зв'язок замінюється бінарними зв'язками "один до багатьох" зі знов створеною сутністю;
− кількість бінарних зв'язків дорівнює ступеню складності зв'язку.
Якщо в концептуальній моделі даних присутній багатозначний атрибут, то може бути виконана декомпозиція цього атрибуту для визначення деякої сутності.
Вилучення зв'язків з атрибутами виконується шляхом додавання у модель нової сутності для відношення M:N з атрибутами зв'язку. Для відношення 1:M атрибути зв'язку передаються у сутність "багато" без створення нової сутності.
Створений на попередніх етапах набір відношень логічної моделі БД повинен бути перевірений на коректність об'єднання атрибутів у кожному відношенні. Перевірка виконується шляхом застосування до кожного відношення процедури послідовної нормалізації. Нормалізація гарантує, що отримана модель не буде мати протирічь і буде мати мінімальну збитковість.
Перевірка відповідності відношень вимогам транзакцій користувачів
Перевірка полягає в нанесенні безпосередньо на ER-діаграму всіх шляхів, які потрібні для виконання кожної з транзакцій. Якщо таким чином вдається виконати всі транзакції, то перевірка на цьому завершується. У протилежному випадку необхідно повернутися до попередніх етапів і перевірити, а у разі потреби і змінити ті фрагменти моделі, які не відповідають необхідній роботі транзакцій.
Якщо в результаті перевірки будуть виявлені області, які не беруть безпосередньої участі у роботі транзакцій, то можливо їх вилучення з моделі.
6.6. Перевірка підтримки цілісності
Обмеження цілісності запобігають появі в БД суперечливих даних. Вирішення цієї проблеми на стадії проектування полягає у такому:
− наявність обов'язкових і необов'язкових значень даних для атрибутів (NULL, NOT NULL);
− наявність обмежень для доменів атрибутів (визначення області значень або діапазону значень);
− цілісність сутностей (обов'язкова наявність Primary Key в кожному відношенні);
− посилкова цілісність (зв'язування таблиць за допомогою Foreign Key);
− обмеження предметної області ( бізнес правила), які реалізуються як засобами БД, так і на рівні застосувань.
Нормалізація – це процедура визначення того, які атрибути зв'язані у відношенні. Одна з головних задач при розробці реляційної БД – об'єднання в одному відношенні тих атрибутів, які зв'язані між собою (між якими є функціональні залежності). Нормалізація являє собою поетапний процес заміни сукупності відношень іншою сукупністю ( схемою), в якій відношення мають просту і регулярну структуру.
Результатом нормалізаії є логічна модель БД. Надлишковість даних в БД є небажаним явищем, оскільки призводить до збільшення об'єму пам'яті, уповільнює роботу БД. Надлишковість даних є результатом в першу чергу дублювання даних. Розрізняють незбиткове та збиткове дублювання даних. Повністю усувати надлишковість не потрібно, оскільки при цьому неможливо буде підтримувати БД як єдине ціле. Слід тільки мінімізувати надлишковість, залишивши необхідне дублювання даних. Дублювання даних створює проблеми при виконанні операцій з БД. Ці проблеми виникають при спробі зробити операції: редагування, додавання або вилучення даних. Аномаліями називається така ситуація в БД, яка призводить до протирічь у БД, або суттєво ускладнює обробку даних. Розрізняють аномалії модифікації, додавання і вилучення.
Перша нормальна форма. Відношення знаходиться в 1НФ тоді і тільки тоді, коли всі його атрибути є атомарними. Значення атрибуту вважається атомарним, якщо воно є неподільним у всіх застосуваннях. Приклад. Представлення даних у таблицях може вважатися як атомарним, так і неатомарним залежно від використання. Засіб представлення визначається необхідним ступенем деталізації і повинен підтримуватися у всіх застосуваннях
Друга нормальна форма. Відношення знаходиться в 2НФ, якщо воно знаходиться в 1 НФ і кожен його непервинний атрибут функціонально повно залежить від первинного ключа. Неповною функціональною залежністю називається залежність неключового атрибуту від частини ключа, що складається з декількох атрибутів. Повна функціональна залежність передбачає залежність неключового атрибуту від всіх атрибутів одночасно, що входять до складу ключа.
Третя нормальна форма. Відношення знаходиться в 3НФ, якщо воно знаходиться в 2НФ і жоден з непервинних атрибутів у відношенні не є транзитивно залежним від первинного ключа. Атрибут C транзитивно залежить від атрибуту A, якщо для атрибутів A, B, C виконуються такі умови A → B і B → C, але зворотня залежність відсутня.
Нормальна форма Бойса-Кодда. Відношення знаходить-ся в НФБК, якщо воно знаходиться в 3НФ і у ньому відсутні залежності атрибутів первинного ключа від неключових атрибутів.
ФІЗИЧНА ОРГАНІЗАЦІЯ БАЗ ДАНИХ
Фізична організація даних відповідає за їх зберігання, управління, форми представлення і структури даних. Фізичне проектування являє собою процес визначення характеристик сховища даних і доступу до них в БД. Властивості сховища даних залежать від пристроїв зберігання, засобів доступу до даних, що підтримуються системою і від СУБД. На етапі фізичного проектування визначається місцезнаходження даних на пристроях зберігання, загальна продуктивність системи. В реляційних БД складні фізичні процеси організації даних приховані від користувача, але вони мають великий вплив на продуктивність роботи з БД.
Організація зберігання даних має таку ієрархію:
− атрибути відображаються у байтову послідовність постійної або змінної довжини, яка називається полями;
− поля об'єднуються в набори даних постійної або змінної довжини, які називаються записом;
− записи зберігаються у фізичних блоках (сторінках);
− набори записів, які відповідають відношенням, зберігаються у вигляді файлів.
Розрізняють такі засоби фізичної організації файлів даних: послідовний, індексно-послідовний, прямий.
Послідовний файл – файл, до записів якого можливий послідовний доступ у порядку їх фізичного розміщення в пам'яті. Послідовна організація ефективна, коли застосування при кожному зверненні до БД обробляє значну кількість записів.
Індексно-послідовний файл − файл, до записів якого можливий прямий доступ за допомогою створеного для нього індексу по заданому ключу, а також послідовний доступ згідно з їх впорядкуванням по цьому ключу індексування. Індексно-послідовна організація ефективна, коли достатньо багато застосувань потребують послідовної обробки і достатньо багато застосувань потребують прямого доступу.
Файл прямого доступу − файл, в якому забезпечується прямий доступ до його записів за їх безпосередньою або посередньою адресою у середовищі зберігання або за заданими ключем за допомогою будь-якого методу відображення ключа в адресу. Пряма організація необхідна, коли для більшості застосувань потрібен прямий доступ до записів.
Індекс − структура даних, яка допомагає СУБД швидше знайти окремі записи в файлі і скоротити час виконання запитів користувачів. Основне призначення індексів полягає в забезпеченні ефективного прямого доступу до записів таблиці по ключу. Файл, що містить індексні записи називається індексним файлом.
Залежно від організації індексної і основної області розрізняють два типи файлів: зі щільним індексом і з розрідженим індексом. Щільний індекс вміщує індексні записи для всіх значень ключа пошуку в даному файлі. Розріджений індекс вміщує індексні записи тільки для деяких значень ключа пошуку в даному файлі. У файлах зі щільним індексом основна область вміщує послідовність записів однакової довжини, які розташовані у довільному порядку, а структура індексного запису має такий вигляд: (значення ключа, номер запису).
В індексних файлах зі щільним індексом для кожного запису в основній області існує один запис з індексної області. Всі записи в індексній області впорядковані за значенням ключа. Файли зі щільним індексом називаються індексно-прямими файлами. У файлах з розрідженим індексом основна область вміщує послідовність записів однакової довжини, які розташовані у впорядкованому порядку, а структура індексного запису має такий вигляд: (значення ключа першого запису блока, номер блока з цим записом).
Розріджений індекс будується для впорядкованих файлів. Файли з розрідженим індексом називаються індексно-послідовними файлами.
Індекси доцільно створювати по стовпцю або групі стовпців у таких випадках:
− часто виконується пошук у БД за атрибутами, які перелічені в умові WHERE оператора SELECT;
− часто виконується об'єднання таблиць за певними атрибутами;
− часто виконується сортування таблиць ( використання ORDER BY в операторі SELECT).
1. Історія створення|створіння| і розвитку SQL|
SQL – це стандартна мова програмування, яка використовується для створення, модифікації, пошуку і вибірки інформації, що зберігається в довільній реляційній базі даних, яка управляється відповідною системою управління базами даних (СУБД).
Мова SQL дуже могутня, тому її підтримують найбільш популярні СУБД, зокрема Microsoft Access, Oracle і MySQL, хоча рівень цієї підтримки істотно залежить від того, про яку саме СУБД йдеться.
SQL – це стандартизована, непроцедурна мова програмування, яка використовується для маніпулювання даними і об'єктами баз даних, використовуючи при цьому вбудований і/або інтерактивний SQL.
Програмуючи на SQL, вам треба вказати тільки те, що саме необхідно зробити, а далі сама СУБД автоматично і непомітно для вас визначає і виконує ту послідовність покрокових операцій, яку вимагається виконати для досягнення бажаного результату.
Проте управляючі конструкції звичайно присутні в SQL і застосовуються при створенні так званих процедур збереження - певних наборів інструкцій, призначених для виконання складних дій з даними.
Якщо ви включаєте команди SQL як елементи в які-небудь програми, написані на процедурних мовах, вважається, що ви застосовуєте так званий вбудований SQL, а ті процедурні мови, на яких написані ці більш великі або, точніше, несучі програми, називають базовими. Такою мовою на практиці частіше всього виявляється будь-яка мова програмування загального призначення, зокрема С, Java або COBOL, або яка-небудь мова сценаріїв, наприклад Perl, PHP або Python.
Якщо в режимі реального часу адресувати команди на мові SQL безпосередньо вашій СУБД, а вона відобразить відповідні результати відразу ж, як тільки отримає, значить, ви застосовуєте інтерактивний або динамічний SQL. Зазначимо, що всі сучасні сервери СУБД поставляються в комплекті з такими графічними додатками або утилітами командного рядка, які сприймають інтерактивні команди SQL або/і текстові файли, що містять SQL-пpoграми, тобто сценарії. Майте на увазі, що між інтерактивними і вбудованими командами можуть існувати невеликі синтаксичні відмінності.
Всі команди SQL прийнято ділити на дві основні групи - мова маніпулювання даними (DML) і мова визначення даних (DDL).
Для будь-якої бази даних команди групи DML відбирають, обчислюють, вставляють, видаляють і редагують ті дані, які зберігаються в цій базі.
Команди групи DDL створюють, модифікують і знищують такі об'єкти бази даних, як таблиці, індекси і погляди.
SQL – це інструмент, призначений для вибірки та опрацювання інформації, яка міститься в комп’ютерній базі даних. SQL – це мова програмування, яка застосовується для організації взаємодії користувача із базою даних. Це не алгоритмічна мова.
Якщо користувачу необхідно отримати якусь інформацію із бази даних, то він запитує її за допомогою SQL. СУБД опрацьовує запит, знаходить потрібні дані і надсилає їх користувачу.
Функції SQL:
1) організація даних – SQL дає користувачу можливість визначити структуру представлення даних, а також встановлювати відношення між елементами бази даних;
2) вибірка даних – SQL дає можливість користувачу чи прикладній програмі отримати із бази даних інформацію, яка в ній міститься;
3) опрацювання даних – SQL дає можливість користувачу чи прикладній програмі змінювати базу даних, тобто додавати нові дані, оновлювати чи вилучати існуючі;
4) управління доступом – за допомогою SQL можна обмежувати можливості користувача щодо вибірки і зміни даних та захистити дані від несанкціонованого доступу;
5) спільне використання даних – SQL координує спільне використання даних користувачами, які працюють паралельно так, щоб вони не заважали один одному;
6) цілісність даних – SQL дозволяє забезпечити цілісність бази даних, захищаючи її від руйнації через неузгоджені зміни чи відмови системи.
Переваги SQL:
1) незалежність від конкретних СУБД;
2) міжплатформна переносимість;
3) наявність стандартів;
4) підтримка компаніями IBM та Microsoft;
5) реляційна основа;
6) високорівнева структура;
7) можливість виконання інтерактивних запитів;
8) забезпечення програмного доступу до бази даних;
9) можливість різноманітного представлення даних;
10) повноцінність, як мови опрацьовування баз даних;
11) можливість динамічного визначення даних;
12) підтримка архітектури клієнт-сервер;
13) підтримка корпоративних прикладних програм;
14) розширюваність та підтримка об’єктно-орієнтованого програмування;
15) можливість доступу до даних в Internet;
16) інтеграція з мовою Java (протокол JDBC);
17) промислова інфраструктура.
ЗАХИСТ ІНФОРМАЦІЇ В БАЗАХ ДАНИХ
Захист даних − попередження несанкціонованого або випадкового доступу до даних, їх зміни або руйнування даних з боку користувачів; попередження змін або руйнування даних при збоях апаратних і програмних засобів і при помилках в роботі співробітників групи експлуатації.
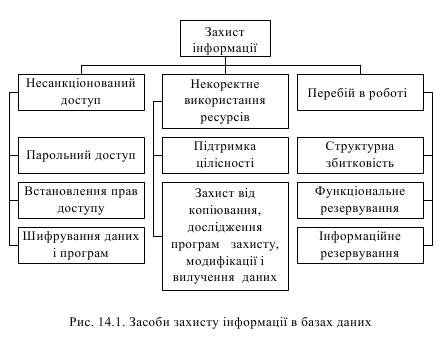
Наслідками порушення захисту є матеріальні збитки, зниження продуктивності системи, отримання таємних відомостей, руйнування БД. Головними причинами порушення захисту є несанкціонований доступ, некоректне використання ресурсів, перебої в роботі системи. В БД застосовуються засоби захисту наведені на рис. 14.1.
Парольний захист передбачає встановлення пароля, який являє собою ряд літер, визначених користувачем при вході в систему з метою ідентифікації системними механізмами управління доступом. Після ідентифікації виконується аутентифікація. Аутентифікація − процедура, яка встановлює автентичність ідентифікатора, який висувається користувачем, програмою, процесом, системою при вході в систему, при запиті деякої послуги або при доступі до ресурсу.
Процес аутентифікації це обмін між користувачем і системою інформацією, яка відома тільки системі і користувачу.
Управління доступом − захист інформаційних ресурсів в системі БД від несанкціонованого доступу. Мета полягає в забезпеченні представлення доступу до ресурсів тільки користувачам, програмам, процесам, системам, які мають відповідні права доступу.
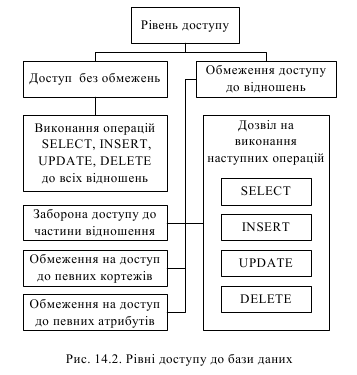
Як тільки користувач отримає право доступу до СУБД, йому автоматично представляються різні привілеї, пов'язані з його ідентифікатором. Ці привілеї можуть включати дозвіл на доступ до певних таблиць, представлень, індексів, а також на певні операції над цими об'єктами: перегляд (SELECT), додавання (INSERT), оновлення (UPDATE), вилучення (DELETE) (рис. 14.2).
У сучасних СУБД підтримуються два найбільш загальних підходи до забезпечення безпеки даних: вибірковий підхід і обов'язковий підхід.
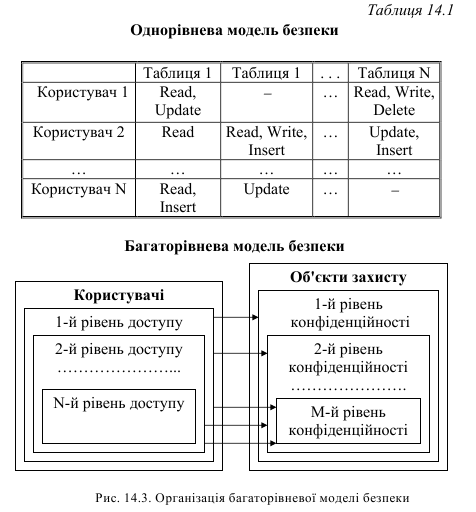
Вибірковий підхід передбачає, що кожен користувач має різні права при роботі з даними об'єктами. Різні користувачі можуть мати різні права доступу до одного й того ж об'єкта.
Такий підхід це однорівнева модель безпеки (табл. 14.1).
Обов'язковий підхід передбачає, що кожному об'єкту даних надається деякий кваліфікаційний рівень, а кожен користувач має деякий рівень допуску. При такому підході правом доступу до певного об'єкта даних мають тільки користувачі з відповідним рівнем доступу. Такий підхід являє собою багаторівневу модель безпеки
Шифрування даних − метод забезпечення таємності даних шляхом генерації нового їх представлення, яке допускає однозначне відновлення вихідного представлення.
Система шифрування включає в себе ключ шифрування, алгоритм шифрування, ключ дешифрування і алгоритм дешифрування.
Захист від перебоїв і відказів роботи апаратно-програмного забезпечення є однією з необхідних умов нормальної роботи системи. Головне навантаження по забезпеченню захисту системи від перебоїв і відказів припадає на апаратно-програмні компоненти. Структурна збитковість передбачає резервування апаратних компонентів на різних рівнях: дублювання серверів, процесорів, накопичувачів на магнітних дисках (RAID − масив недорогих дискових накопичувачів зі збитковістю), використання джерел безперебійного живлення. Функціональне резервування означає організацію обчислювального процесу, при якій функції обробки даних виконуються декількома елементами системи.
Інформаційне резервування реалізується шляхом періодичного копіювання і архівування даних.
Під некоректним використанням ресурсів розуміють некоректні зміни в БД ( порушення посилкової цілісності, введення невірних даних і т.ін.), випадковий доступ прикладних програм до чужих розділів основної пам'яті і т.ін.
Вирішуються ці проблеми шляхом підтримки цілісності БД, використанням захисту від копіювання, дослідження програм, модифікації і вилучення даних. Тут застосовуються як прикладні програми, так і засоби операційної системи.
РОЗПОДІЛЕНА ОБРОБКА ДАНИХ
1. Основні поняття і визначення
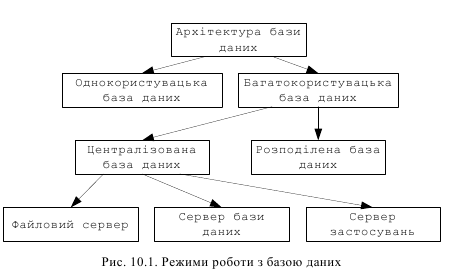
Режими використання БД у загальному вигляді показані на рис. 10.1.
Якщо з БД працюють одночасно декілька користувачів, то в цьому випадку СУБД повинна забезпечувати коректну паралельну роботу всіх користувачів над одними і тими ж даними. Розрізняють розподілену обробку і розподілені БД.
Розподілена обробка − це обробка з використанням централізованої бази даних, доступ до якої може виконуватись з різних комп'ютерів мережі (рис. 10.2, a). Ця топологія часто називається " клієнт-сервер". В цій системі одні вузли − клієнти, а інші − сервери.
Сервер − комп'ютер, який надає деякі послуги іншим комп'ютерам, обмін повідомленнями з якими здійснюється за допомогою мережі, що їх з'єднує. Послуги полягають у наданні комп'ютеру, який звертається, ресурсів сервера ( файлів, обчислювальних ресурсів і т.ін.) шляхом виконання вказаної програми і видачі результатів її роботи.
Клієнт − це процес, який посилає запит на обслуговування.
Розподілена база даних − це набір логічно зв'язаних між собою роздільних даних і їх описів, які фізично розподілені в деякій комп'ютерній мережі (рис. 10.2, б). Розподілена СУБД, в якій управління кожним із вузлів виконується зовсім автономно називається мультибазовою системою.
Розподілена СУБД – це програмна система, яка призначена для управління розподіленими базами даних і яка забезпечує прозорий доступ користувачів до розподіленої інформації.
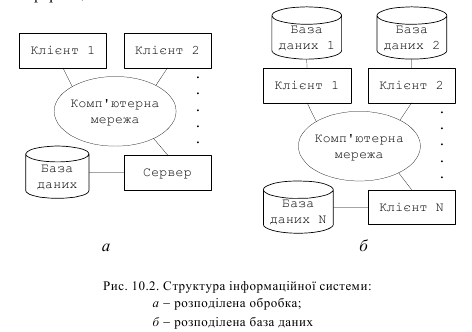
Якщо всі вузли розподіленої системи використовують той самий тип СУБД, то така система називається гомогенною. Якщо вузли розподіленої системи використовують різні типи СУБД, які обробляють різні моделі даних, то така система називається гетерогенною.
Існують такі схеми розміщення даних в системі:
− централізоване;
− фрагментоване;
− з повною реплікацією;
− з вибірковою реплікацією.
Централізоване розміщення передбачає, що на одному з вузлів створюється і зберігається єдина БД. Доступ до цієї БД мають всі користувачі мережі.
Фрагментоване розміщення передбачає, що БД ділиться на неперетинні фрагменти, кожен з яких розміщується в одному з вузлів системи. Розміщення з повною реплікацією передбачає, що повна копія БД розміщується на кожному вузлі системи. Розміщення з вибірковою реплікацією являє собою комбінацію методів фрагментування, реплікації й централізації. Одні масиви даних поділяються на фрагменти, інші реплікуються, останні зберігаються централізовано.
Реплікація це процес генерації і відтворювання декількох копій даних, які розміщуються на одному або декількох вузлах. Використання реплікацій дозволяє досягнути багатьох переваг (продуктивність, надійність зберігання даних, відновлення даних і т.ін.).
Згідно з правилами Дейта розподілена СУБД повинна відповідати таким вимогам:
− розподілена система повинна виглядати з точки зору користувача, як звичайна нерозподілена система;
− вузли в розподіленій системі повинні бути незалежні або автономні;
− в системі не повинно бути жодного вузла, без якого система не може функціонувати;
− повинна виконуватись умова незалежності від розташування і користувач може отримувати доступ до БД з будь-якого вузла;
− незалежність від фрагментації – це означає, що користувач може отримати доступ до даних незалежно від засобу їх фрагментації;
− незалежність від реплікації – це означає, що користувач не має засобів доступу до конкретної копії даних і не займається питаннями оновлення всіх копій в БД;
− підтримка обробки розподілених запитів;
− підтримка управління розподіленими транзакціями;
− апаратна, програмна, мережна незалежність, а також незалежність від типу СУБД;
− забезпечення безперервного функціонування.
Дата добавления: 2015-01-13; просмотров: 5296;