ВСТУПИТЕЛЬНАЯ ЛЕКЦИЯ. ИСТОРИЯ РАЗВИТИЯ. 7 страница
15.1. Структурирование системы
На первом этапе процесса проектирования архитектуры система разбивается на несколько взаимодействующих подсистем. На самом абстрактном уровне архитектуру системы можно изобразить графически с помощью блок-схемы, в которой отдельные подсистемы представлены отдельными блоками. Если подсистему также можно разбить на несколько частей, на диаграмме эти части изображаются прямоугольниками внутри больших блоков. Потоки данных и/или потоки управления между подсистемами обозначается стрелками. Такая блок-схема дает общее представление о структуре системы.
На рис. 15.1 представлена структурная модель архитектуры для системы управления автоматической упаковкой различных типов объектов. Она состоит из нескольких частей. Подсистема наблюдения изучает объекты на конвейере, определяет тип объекта и выбирает для него соответствующий тип упаковки. Затем объекты снимаются с конвейера, упаковываются и помещаются на другой конвейер.
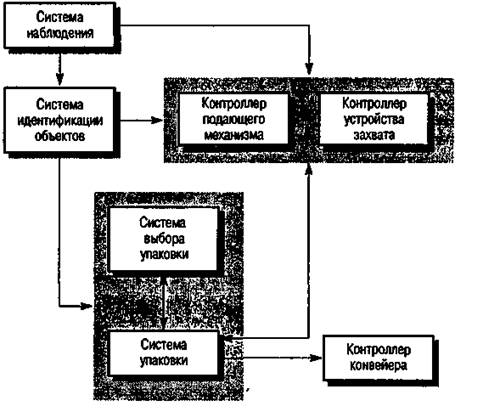
Рис. 15.1. Блок схема системы управления автоматической упаковкой
Бэсс (Bass) считает, что подобные блок-схемы являются бесполезными представлениями системной архитектуры, поскольку из них нельзя ничего узнать ни о природе взаимоотношений между компонентами системы, ни об их свойствах. С точки зрения разработчика программного обеспечения, это абсолютно верно. Однако такие модели оказываются эффективными на этапе предварительного проектирования системы. Эта модель не перегружена деталями, с ее помощью удобно представить структуру системы. В структурной модели определены все основные подсистемы, которые можно разрабатывать независимо от остальных подсистем, следовательно, руководитель проекта может распределить разработку этих подсистем между различными исполнителями. Конечно, для представления архитектуры используются не только блок-схемы, однако подобное представление системы не менее полезно, чем другие архитектурные модели.
Конечно, можно разрабатывать более детализированные модели структуры, в которых было бы показано, как именно подсистемы разделяют данные и как взаимодействуют друг с другом. В этом разделе рассматриваются три стандартные модели, а именно: модель репозитория, модель клиент/сервер и модель абстрактной машины.
15.1.1. Модель репозитория
Для того чтобы подсистемы, составляющие систему, работали эффективнее, между ними должен идти обмен информацией. Обмен можно организовать двумя способами.
1. Все совместно используемые данные хранятся в центральной базе данных, доступной всем подсистемам. Модель системы, основанная на совместном использовании базы данных, часто называют моделью репозитория.
2. Каждая подсистема имеет собственную базу данных. Взаимообмен данными между подсистемами происходит посредством передачи сообщений.
Большинство систем, обрабатывающих большие объемы данных, организованы вокруг совместно используемой базы данных, или репозитория. Поэтому такая модель подойдет к приложениям, в которых данные создаются в одной подсистеме, а используются в другой. Примерами могут служить системы управления информацией, системы автоматического проектирования и CASE средства.
На рис. 15.2 представлен пример архитектуры интегрированного набора CASE-инструментов, основанный на совместно используемом репозитории. Считается, что для CASE-средств первый совместно используемый репозитории был разработан в начале 1970-х годов английской компанией ICL в процессе создания своей операционной системы. Широкую известность эта модель получила после того, как была применена для поддержки разработки систем, написанных на языке Ada. С тех пор многие CASE-средства разрабатываются с использованием общего репозитория.
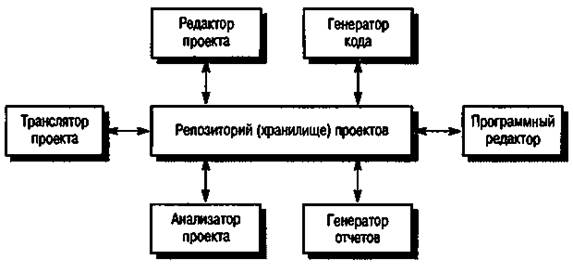
Рис 15.2. Архитектура интегрированного набора CASE средств
Совместно используемые репозитории имеют как преимущества, так и недостатки.
1. Очевидно, что совместное использование больших объемов данных эффективно, поскольку не требуется передавать данные из одной подсистемы в другие.
2. С другой стороны, подсистемы должны быть согласованы с моделью репозитория данных. Это всегда приводит к необходимости компромисса между требованиями, предъявляемыми к каждой подсистеме. Компромиссное решение может понизить их производительность. Если форматы данных новых подсистем не подходят под согласованную модель представления данных, интегрировать такие подсистемы сложно или невозможно.
3. Подсистемам, в которых создаются данные, не нужно знать, как эти данные используются в других подсистемах.
4. Поскольку в соответствии с согласованной моделью данных генерируются большие объемы информации, модернизация таких систем проблематична. Перевод системы на новую модель данных будет дорогостоящим и сложным, а порой даже невозможным.
5. В системах с репозиторием такие средства, как резервное копирование, обеспечение безопасности, управление доступом и восстановление данных, централизованы, поскольку входят в систему управления репозиторием. Эти средства выполняют только свои основные операции и не занимаются другими вопросами.
6. С другой стороны, к разным подсистемам предъявляются разные требования, касающиеся безопасности, восстановления и резервирования данных. В модели репозитория ко всем подсистемам применяется одинаковая политика.
7. Модель совместного использования репозитория прозрачна: если новые подсистемы совместимы с согласованной моделью данных, их можно непосредственно интегрировать в систему.
8. Однако сложно разместить репозитории на нескольких машинах, поскольку могут возникнуть проблемы, связанные с избыточностью и нарушением целостности данных.
В рассматриваемой модели репозитории является пассивным элементом, а управление им возложено на подсистемы, использующие данные из репозитория. Для систем искусственного интеллекта разработан альтернативный подход. Он основан на модели «рабочей области», которая инициирует подсистемы тогда, когда конкретные данные становятся доступными. Такой подход применим к системам, в которых форма данных хорошо структурирована.
15.1.2. Модель клиент/сервер
Модель архитектуры клиент/сервер — это модель распределенной системы, в которой показано распределение данных и процессов между несколькими процессорами. Модель включает три основных компонента.
1. Набор автономных серверов, предоставляющих сервисы другим подсистемам. Например, сервер печати, который предоставляет услуги печати, файловые серверы, предоставляющие сервисы управления файлами, и сервер-компилятор, который предлагает сервисы по компилированию исходных кодов программ.
2. Набор клиентов, которые вызывают сервисы, предоставляемые серверами. В контексте системы клиенты являются обычными подсистемами. Допускается параллельное выполнение нескольких экземпляров клиентской программы.
3. Сеть, посредством которой клиенты получают доступ к сервисам. В принципе нет никакого запрета на то, чтобы клиенты и серверы запускались на одной машине. На практике, однако, модель клиент/сервер в такой ситуации не используется.
Клиенты должны знать имена доступных серверов и сервисов, которые они предоставляют. В то же время серверам не нужно знать ни имена клиентов, ни их количество. Клиенты получают доступ к сервисам, предоставляемым сервером, посредством удаленного вызова процедур.
Пример системы, организованной по типу модели клиент/сервер, показан на рис. 15.3. Это многопользовательская гипертекстовая система, предназначенная для поддержки библиотек фильмов и фотографий. В ней содержится несколько серверов, которые размещают различные типы медиафайлов и управляют ими. Видеофайлы требуется передавать быстро и синхронно, но с относительно малым разрешением. Они могут храниться в сжатом состоянии. Фотографии должны передаваться с высоким разрешением. Каталоги должны обеспечивать работу с множеством запросов и поддерживать связи с использованием гипертекстовой системы. Здесь клиентская программа является просто интегрированным интерфейсом пользователя.
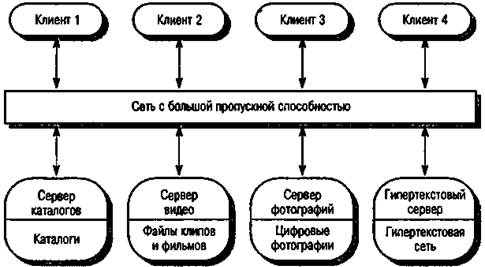
Рис. 15.3. Архитектура библиотечной системы фильмов и фотографий
Подход клиент/сервер можно использовать при реализации систем, основанных на репозитории, который поддерживается как сервер системы. Подсистемы, имеющие доступ к репозиторию, являются клиентами. Но обычно каждая подсистема управляет собственными данными. Во время работы серверы и клиенты обмениваются данными, однако при обмене большими объемами данных могут возникнуть проблемы, связанные с пропускной способностью сети. Правда, с развитием все более быстрых сетей эта проблема теряет свое значение.
Наиболее важное преимущество модели клиент/сервер состоит в том, что она является распределенной архитектурой. Ее эффективно использовать в сетевых системах с множеством распределенных процессоров. В систему легко добавить новый сервер и интегрировать его с остальной частью системы или же обновить серверы, не воздействуя на другие части системы.
15.1.3. Модель абстрактной машины
Модель архитектуры абстрактной машины (иногда называемая многоуровневой моделью) моделирует взаимодействие подсистем. Она организует систему в виде набора уровней, каждый из которых предоставляет свои сервисы. Каждый уровень определяет абстрактную машину, машинный язык которой (сервисы, предоставляемые уровнем) используется для реализации следующего уровня абстрактной машины. Например, наиболее распространенный способ реализации языка программирования состоит в определении идеальной «языковой машины» и компилировании программ, написанных на данном языке, в код этой машины. На следующем шаге трансляции код абстрактной машины конвертируется в реальный машинный код.
Хорошо известным примером такого похода может служить модель OSI сетевых протоколов. Другим примером является трехуровневая модель среды программирования на языке Ada. На рис. 15.4 изображена подобная модель и показано, как с помощью модели абстрактной машины можно представить систему администрирования версий.
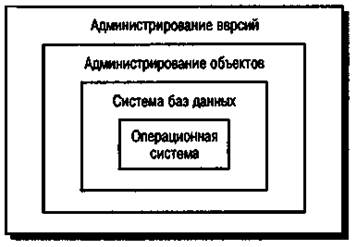
Рис. 15.4. Модель абстрактной машины для системы администрирования версий
Система администрирования версий основана на управлении версиями объектов и предоставляет средства для полного управления конфигурацией системы. Для поддержки средств управления конфигурацией используется система администрирования объектов, поддерживающая систему базы данных и сервисы управления объектами. В свою очередь, в системе баз данных поддерживаются различные сервисы, например управления транзакциями, отката назад, восстановления и управления доступом. Для управления базами данных используются средства основной операционной системы и ее файловая система.
Многоуровневый подход обеспечивает пошаговое развитие систем — при разработке какого-либо уровня предоставляемые им сервисы становятся доступны пользователям. Кроме того, такая архитектура легко изменяема и переносима на разные платформы. Изменение интерфейса любого уровня повлияет только на смежный уровень. Так как в многоуровневых системах зависимости от машинной платформы локализованы на внутренних уровнях, такие системы можно реализовать на других платформах, поскольку потребуется изменить только самые внутренние уровни.
Недостатком многоуровневого подхода является довольно сложная структура системы. Основные средства, такие как управление файлами, необходимые всем абстрактным машинам, предоставляются внутренними уровнями. Поэтому сервисам, запрашиваемым пользователем, возможно, потребуется доступ к внутренним уровням абстрактной машины. Такая ситуация приводит к разрушению модели, так как внешний уровень зависит не только от предшествующего ему уровня, но и от более низких уровней.
Лекция 16. Модели управления
В модели структуры системы показаны все подсистемы, из которых она состоит. Для того чтобы подсистемы функционировали как единое целое, необходимо управлять ими. В структурных моделях нет (и не должно быть) никакой информации по управлению. Однако разработчик архитектуры должен организовать подсистемы согласно некоторой модели управления, которая дополняла бы имеющуюся модель структуры. В моделях управления на уровне архитектуры проектируется поток управления между подсистемами.
Можно выделить два основных типа управления в программных системах.
1. Централизованное управление. Одна из подсистем полностью отвечает за управление, запускает и завершает работу остальных подсистем. Управление от первой подсистемы может перейти к другой подсистеме, однако потом обязательно возвращается к первой.
2. Управление, основанное на событиях. Здесь вместо одной подсистемы, ответственной за управление, на внешние события может отвечать любая подсистема. События, на которые реагирует система, могут происходить либо в других подсистемах, либо во внешнем окружении системы.
Модель управления дополняет структурные модели. Все описанные ранее структурные модели можно реализовать с помощью централизованного управления или управления, основанного на событиях.
16.1. Централизованное управление
В модели централизованного управления одна из систем назначается главной и управляет работой других подсистем. Такие модели можно разбить на два класса, в зависимости от того, последовательно или параллельно реализовано выполнение управляемых подсистем.
1. Модель вызова-возврата. Это известная модель организации вызова программных процедур «сверху вниз», в которой управление начинается на вершине иерархии процедур и через вызовы передастся на более нижние уровни иерархии. Данная модель применима только в последовательных системах.
2. Модель диспетчера. Применяется в параллельных системах. Один системный компонент назначается диспетчером и управляет запуском, завершением и координированием других процессов системы. Процесс (выполняемая подсистема или модуль) может протекать параллельно с другими процессами. Модель такого типа применима также в последовательных системах, где управляющая программа вызывает отдельные подсистемы в зависимости от значений некоторых переменных состояния. Обычно такое управление реализуется через оператор case.
Модель вызова-возврата представлена на рис. 16.1. Из главной программы можно вызвать подпрограммы 1, 2 и 3, из подпрограммы 1 — подпрограммы 1.1 и 1.2, из подпрограммы 3 — подпрограммы 3.1 и 3.2 и т.д. Такая модель выполнения подпрограмм не является структурной — подпрограмма 1.1 не обязательно является частью подпрограммы 1.
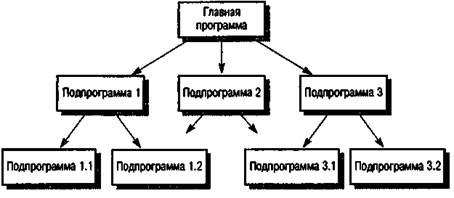
Рис. 16.1. Модель вызова возврата
Подобная модель встроена в языки программирования Ada, Pascal и С. Управление переходит от программы, расположенной на самом верхнем уровне иерархии, к подпрограмме более нижнего уровня. Затем происходит возврат управления в точку вызова подпрограммы. За управление отвечает та подпрограмма, которая выполняется в текущий момент; она может либо вызывать другие подпрограммы, либо вернуть управление вызвавшей се подпрограмме. Несовершенство данного стиля программирования при возврате к определенной точке в программе очевидно.
Модель вызова-возврата можно использовать па уровне модулей для управления функциями и объектами. Подпрограммы в языке программирования, которые вызываются из других подпрограмм, являются естественно функциональными. Однако во многих объектно-ориентированных системах операции в объектах (методы) реализованы в виде процедур или функций. Например, объект Java запрашивает сервис из другого объекта посредством вызова соответствующего метода.
Жесткая и ограниченная природа модели вызова-возврата является одновременно и преимуществом и недостатком. Преимущества модели проявляются в относительно простом анализе потоков управления, а также при выборе системы, отвечающей за конкретный ввод данных. Недостаток модели в сложной обработке исключительных ситуаций.
Па рис. 16.2 представлена модель централизованного управления для параллельной системы.
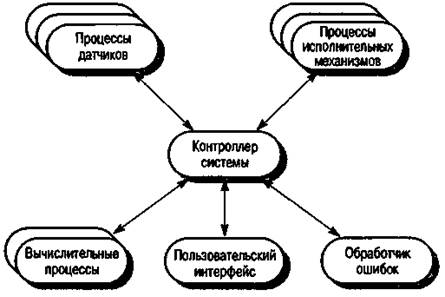
Рис. 16.2. Модель централизованного управления для системы реального времени
Подобная модель часто используется в «мягких» системах реального времени, в которых нет чересчур строгих временных ограничений. Центральный контроллер управляет выполнением множества процессов, связанных с датчиками и исполнительными механизмами.
Контроллер системы, в зависимости от переменных состояния системы, определяет моменты запуска или завершения процессов. Он проверяет, генерируется ли в остальных процессах информация, для того чтобы затем обработать ее или передать другим процессам на обработку. Обычно контроллер работает постоянно, проверяя датчики и другие процессы или отслеживая изменения состояния, поэтому данную модель иногда называют моделью с обратной связью.
16.2. Системы, управляемые событиями
В моделях централизованного управления, как правило, управление системой определяется значениями некоторых переменных ее состояния. В противоположность таким моделям существуют системы, управление которыми основано на внешних событиях. В данном контексте под событием подразумевается не только бинарный сигнал типа «да-нет». Здесь сигнал может принимать некоторый диапазон значений. Различие между событием и обычными входными данными заключается в том, что планирование события выходит за рамки управления процессом, обрабатывающим это событие. Для обработки события подсистеме необходим доступ к информации состояния, однако такая информация обычно не определяется потоком управления.
Разработано множество различных типов событийно-управляемых систем. К ним относятся электронные таблицы, в которых изменение значения в какой-либо ячейке изменяет содержимое других ячеек, системы искусственного интеллекта, в которых при выполнении некоторого условия происходит инициирование действия либо используются активные объекты, тогда при изменении значения свойства объекта инициируется некоторое действие.
Опишем две модели систем, управляемых событиями.
1. Модели передачи сообщений. В этих моделях событие представляет собой передачу сообщения всем подсистемам. Любая подсистема, которая обрабатывает данное событие, отвечает на него.
2. Модели, управляемые прерываниями. Такие модели обычно используются в системах реального времени, где внешние прерывания регистрируются обработчиком прерываний, а обрабатываются другим системным компонентом.
Модели передачи сообщений эффективны при интеграции подсистем, распределенных на разных компьютерах, которые объединены в сеть. Модели, управляемые прерываниями, используются в системах реального времени со строгими временными требованиями.
В модели передачи сообщений (рис. 16.3) подсистемы реагируют на определенные события. Если произошло некоторое событие, управление переходит к подсистеме, обрабатывающей данное событие. Между моделью передачи сообщений и моделью централизованного управления, показанной на рис. 16.2, существует отличие: алгоритм управления не встроен в обработчик сообщений и событий. Подсистемы определяют, какие события им требуются, а обработчик сообщений и событий следит, чтобы данные события были отправлены именно им.
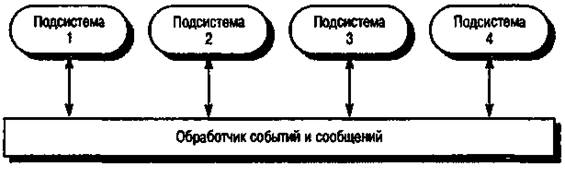
Рис. 16.3. Модель управления, основанная на передаче сообщений
Все события могут генерировать сообщения всем подсистемам, но при этом значительно увеличивается нагрузка при обработке данных. Часто обработчик событий и сообщений управляет регистром подсистем и событиями, на которые они реагируют. Подсистемы генерируют события, в которых, возможно, есть данные для обработки. Обработчик регистрирует событие, принимая во внимание его регистр, и передает это событие в те подсистемы, которые на него реагируют.
Обработчик события всегда поддерживает двухточечное взаимодействие. Поэтому подсистемы могут явно отправить сообщение другой подсистеме. Существует множество разновидностей этой модели. Брокеры запросов к объектам также поддерживают данную модель управления при взаимодействии между распределенными объектами.
Преимуществом модели передачи сообщений является относительно простая модернизация систем, построенных в соответствии с этой моделью. Новую подсистему можно интегрировать в систему, регистрируя ее события в обработчике событий. Каждая подсистема может активизировать любую другую подсистему, не зная ее имени или размещения. Подсистемы также можно реализовать на разных машинах.
Недостатком данной модели является то, что подсистемам неизвестно, когда произойдет обработка события. Генерируя событие, подсистема не знает, какая именно система прореагирует на него. Вполне допустима ситуация, когда разные подсистемы реагируют на одинаковые события. Это может привести к конфликтам при получении доступа к результатам обработки события.
Системы реального времени, в которых одним из требований является быстрая обработка внешних событий, должны быть событийно-управляемыми. Например, система реального времени, управляющая системой безопасности автомобиля, должна определить возможную аварию и успеть наполнить воздухом подушку безопасности до того, как голова водителя ударится о руль. Для того чтобы обеспечить быструю реакцию на события, необходимо использовать управление, основанное на прерываниях.
На рис. 16.4 показана модель управления, основанная на прерываниях. Для каждого тина прерываний существует свой обработчик. Каждый тип прерывания ассоциируется с ячейкой памяти, в которой хранится адрес обработчика прерывания. При получении определенного прерывания аппаратный переключатель немедленно передает управление обработчику прерывания. В ответ на событие, вызванное прерыванием, обработчик может запустить или завершить другие процессы.
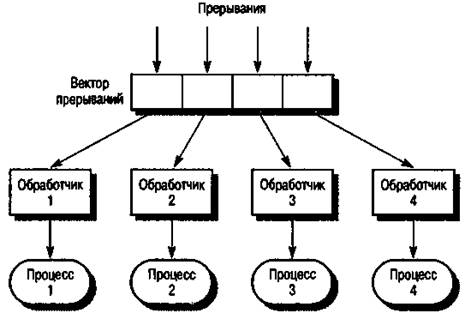
Рис. 16.4. Модель управления, основанная на прерываниях
Данная модель используется только в жестких системах реального времени, где требуется немедленная реакция на определенные события. Можно скомбинировать эту модель с моделью централизованного управления. Центральный диспетчер обрабатывает нормальный ход выполнения системы, а в критических ситуациях используется управление, основанное на прерываниях.
Преимуществом такого подхода является мгновенная реакция системы на происходящие события, недостатками — сложность программирования и аттестации системы. Практически невозможно имитировать все прерывания в процессе тестирования системы. Сложно изменять системы, разработанные на основе такой модели, так как число прерываний ограничено аппаратурой. Никакие другие типы событий не обрабатываются, если достигнут этот предел. Ограничение иногда можно обойти, если на одном прерывании определить несколько типов событий и предоставить для их обработки отдельный обработчик. Однако, если требуется очень быстрая реакция на прерывание, такой подход оказывается непрактичным.
16.3. Модульная декомпозиция
После этапа разработки системной структуры в процессе проектирования следует этап декомпозиции подсистем на модули. Между разбивкой системы на подсистемы и подсистем на модули нет принципиальных отличий. На этом этапе можно использовать модели, рассмотренные в разделе 16.1. Однако компоненты модулей обычно меньше компонентов подсистем, поэтому можно использовать специальные модели декомпозиции.
Здесь рассматриваются две модели, используемые на этапе модульной декомпозиции подсистем.
1. Объектно-ориентированная модель. Система состоит из набора взаимодействующих объектов.
2. Модель потоков данных. Система состоит из функциональных модулей, которые получают на входе данные и преобразуют их некоторым образом в выходные данные. Такой подход часто называется конвейерным.
В объектно-ориентированной модели модули представляют собой объекты с собственными состояниями и определенными операциями над этими состояниями. В модели потоков данных модули выполняют функциональные преобразования. В обеих моделях модули реализованы либо как последовательные компоненты, либо как процессы.
По возможности разработчикам не стоит принимать поспешных решений о том, будет ли система параллельной или последовательной. Проектирование последовательной системы имеет ряд преимуществ: последовательные программы легче проектировать, реализовать, проверять и тестировать, чем параллельные системы, где очень сложно формализовать, управлять и проверять временные зависимости между процессами. Лучше сначала разбить систему на модули, а на этапе реализации решить, как организовать их выполнение — последовательно или параллельно.
16.3.1. Объектные модели
Объектно-ориентированная архитектурная модель структурирует систему в виде совокупности слабо связанных объектов с четко определенными интерфейсами. Объекты вызывают сервисы, предоставляемые другими объектами.
На рис. 16.5 представлен пример объектно-ориентированной архитектурной модели для системы обработки счетов. Данная система выписывает счета заказчикам, получает платежи, отправляет квитанции по поступившим платежам и уведомления по неоплаченным счетам.
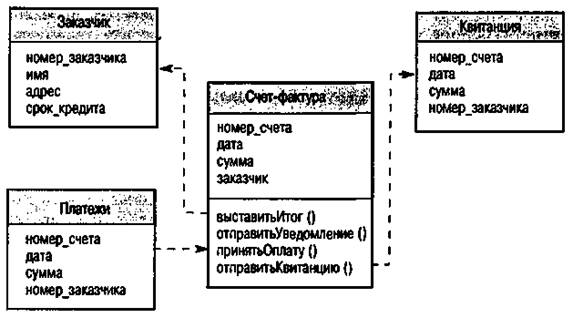
Рис. 16.5. Объектная модель системы обработки счетов
В этом примере используется система нотации языка моделирования UML, в которой классы объектов имеют имена и набор атрибутов. Операции, если они есть, определяются в нижней части прямоугольника, обозначающего объект. Штриховые стрелки означают, что объекты используют свойства или сервисы, предоставляемые другими объектами.
На этапе объектно-ориентированной декомпозиции определяются классы объектов, их свойства и операции. При реализации системы из этих классов создаются объекты; для координации операций объектов используется какая-либо модель управления. В нашем конкретном примере класс Счет имеет различные связанные операции (методы), которые реализуют функциональные средства системы. Этот класс использует другие классы, представляющие заказчиков, платежи и квитанции.
Преимущества объектно-ориентированного подхода хорошо известны. Поскольку объекты слабо связаны между собой, можно изменять реализацию того или иного объекта, не воздействуя на остальные объекты. Структуру системы легко понять, так как объекты часто являются объектами реального мира. Для непосредственной реализации системных компонентов можно использовать объектно-ориентированные языки программирования.
Вместе с тем объектно-ориентированный подход имеет и недостатки. При использовании сервисов объекты должны явно ссылаться на имена других объектов и знать их интерфейс. Если при изменении системы требуется изменить интерфейс, необходимо оценить эффект от такого изменения с учетом всех пользователей изменяемого объекта. Многие объекты реального мира сложно представить в виде системных объектов.
16.3.2. Модели потоков данных
В управляемой потоками данных модели данные проходят через последовательность преобразований. Каждый шаг обработки данных реализован в виде преобразования. Данные, поступающие на вход системы, проходят через все преобразования и достигают выхода системы. Преобразования могут выполняться последовательно или параллельно. Обработка данных может быть пакетной или поэлементной.
Если преобразования представлены в виде отдельных процессов, такую модель иногда называют конвейером или моделью фильтров, следуя терминологии, принятой в системе Unix. Последняя поддерживает конвейеры, которые действуют как хранилища данных, и набор команд, представляющих функциональные преобразования. Здесь используется термин «фильтр», поскольку преобразование «фильтрует» данные во время обработки потока данных.
Различные варианты модели потоков данных возникли вместе с появлением первых компьютеров, предназначенных для автоматизированной обработки данных. Когда преобразования последовательно обрабатывают пакеты данных, такая архитектурная модель называется пакетной последовательной моделью. Она является основой для многих классов систем обработки данных. Примером могут быть системы (например, системы обработки счетов), которые генерируют большое количество выходных отчетов, полученных с помощью несложных вычислений, но с большим количеством входных записей.
Пример такого типа системной архитектуры показан на рис. 16.6. Здесь организация выписывает счета заказчикам. Раз в неделю платежные квитанции согласуются со счетами. Для оплаченных счетов выдается квитанция. По счетам, не оплаченным в течение установленного срока, выдается соответствующее уведомление.
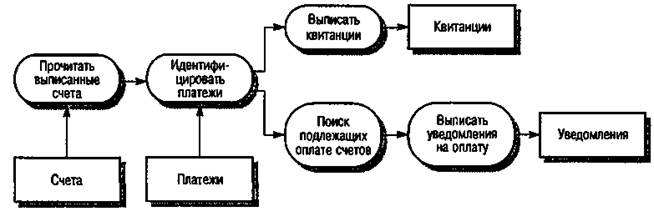
Рис. 16.6. Модель потоков данных для систем обработки счетов
Отметим, что данная модель представляет только часть системы обработки счетов — при выписке счетов используются другие преобразования. Сравните данную модель с объектно-ориентированной, рассмотренной в предыдущем разделе. Объектная модель более абстрактна, так как в ней не содержится информации о последовательности действий.
Дата добавления: 2015-03-23; просмотров: 1425;