Різниця
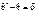
називається зміщенням статистичної оцінки 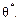
Оцінювальний параметр може мати кілька точкових незміщених статистичних оцінок, що можна зобразити так (рис. 116):
Наприклад, нехай 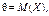 яка має дві незміщені точкові статистичні оцінки —
яка має дві незміщені точкові статистичні оцінки — 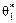 і
і 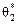 . Тоді щільності ймовірностей для
. Тоді щільності ймовірностей для 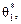 матимуть такий вигляд (рис. 117):
матимуть такий вигляд (рис. 117):


Рис. 117
Із графіків щільностей бачимо, що оцінка 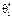 порівняно з оцінкою
порівняно з оцінкою 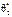 має ту перевагу, що в малому околі параметра θ,
має ту перевагу, що в малому околі параметра θ, 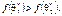 Звідси випливає, що оцінка
Звідси випливає, що оцінка 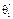 частіше набуватиме значення в цьому околі, ніж оцінка
частіше набуватиме значення в цьому околі, ніж оцінка 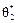 .
.
Але на «хвостах» розподілів маємо іншу картину: більші відхилення від θбудуть спостерігатися для статистичної оцінки 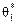 частіше, ніж для . Тому, порівнюючи дисперсії статистичних оцінок
частіше, ніж для . Тому, порівнюючи дисперсії статистичних оцінок 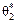 як міру розсіювання, бачимо, що має меншу дисперсію, ніж оцінка .
як міру розсіювання, бачимо, що має меншу дисперсію, ніж оцінка .
Точкова статистична оцінка називається ефективною, коли при заданому обсязі вибірки вона має мінімальну дисперсію. Отже, оцінка буде незміщеною й ефективною.
Точкова статистична оцінка називається ґрунтовною, якщо у разі необмеженого збільшення обсягу вибірки 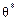 наближається до оцінювального параметра θ, а саме:
наближається до оцінювального параметра θ, а саме:
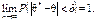
56. Інтервальні статистичні оцінки для параметрів генеральної сукупностіТочкові статистичні оцінки є випадковими величинами, а тому наближена заміна θ на часто призводить до істотних похибок, особливо коли обсяг вибірки малий. У цьому разі застосовують інтервальні статистичні оцінки.Статистична оцінка, що визначається двома числами, кінцями інтервалів, називається інтервальною.Різниця між статистичною оцінкою та її оцінювальним параметром θ, взята за абсолютним значенням, називається точністю оцінки, а саме:
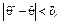 (414)
(414)
де δ є точністю оцінки.
Оскільки є випадковою величиною, то і δ буде випадковою, тому нерівність (414) справджуватиметься з певною ймовірністю.
Імовірність, з якою береться нерівність (414), тобто
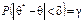 ,(415)
,(415)
називають надійністю.
Рівність (415) можна записати так:
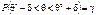 .(416)
.(416)
Інтервал 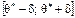 , що покриває оцінюваний параметр θ генеральної сукупності з заданою надійністю g, називають довірчим.
, що покриває оцінюваний параметр θ генеральної сукупності з заданою надійністю g, називають довірчим.
57.Нульова й альтернативна гіпотези
Гіпотезу, що підлягає перевірці, називають основною. Оскільки ця гіпотеза припускає відсутність систематичних розбіжностей (нульові розбіжності) між невідомим параметром генеральної сукупності і величиною, що одержана внаслідок обробки вибірки, то її називають нульовою гіпотезою і позначають Н0.
Зміст нульової гіпотези записується так:
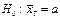 ;
;
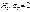 ;
;
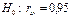 .
.
Кожній нульовій гіпотезі можна протиставити кілька альтернативних (конкуруючих) гіпотез, які позначають символом Нa, що заперечують твердження нульової. Так, наприклад, нульова гіпотеза стверджує: 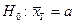 , а альтернативна гіпотеза —
, а альтернативна гіпотеза — 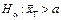 , тобто заперечує твердження нульової.
, тобто заперечує твердження нульової.
58. Область прийняття гіпотези. Критична область. Критична точкаМножину W всіх можливих значень статистичного критерію K можна поділити на дві підмножини А і 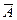 , які не перетинаються.
, які не перетинаються.
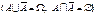 .
.
Сукупність значень статистичного критерію K Î А, за яких нульова гіпотеза не відхиляється, називають областю прийняття нульової гіпотези.Сукупність значень статистичного критерію K Î , за яких нульова гіпотеза не приймається, називають критичною областю.Отже, А — область прийняття Н0,
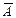 — критична область, де Н0 відхиляється.Точку або кілька точок, що поділяють множину W на підмножини А і , називають критичними і позначають через Kкр.
— критична область, де Н0 відхиляється.Точку або кілька точок, що поділяють множину W на підмножини А і , називають критичними і позначають через Kкр.
Існують три види критичних областей:
Якщо при K < Kкрнульова гіпотеза відхиляється, то в цьому разі ми маємо лівобічну критичну область, яку умовно можна зобразити (рис. 119).

Рис. 119
Якщо при 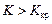 нульова гіпотеза відхиляється, то в цьому разі маємо правобічну критичну область (рис. 120).
нульова гіпотеза відхиляється, то в цьому разі маємо правобічну критичну область (рис. 120).
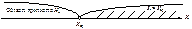
Рис. 120
Якщо ж при  і при
і при  нульова гіпотеза відхиляється, то маємо двобічну критичну область (рис. 121).
нульова гіпотеза відхиляється, то маємо двобічну критичну область (рис. 121).
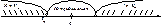
Рис. 121
Лівобічна і правобічна області визначаються однією критичною точкою, двобічна критична область — двома критичними точками, симетричними відносно нуля.
59. Загальний алгоритм перевірки правильності нульової гіпотези
Для перевірки правильності Н0 задається так званий рівень значущості a.
a — це мала ймовірність, якою наперед задаються. Вона може набувати значення a = 0,005; 0,01; 0,001.
В основу перевірки Н0 покладено принцип 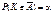 , тобто ймовірність того, що статистичний критерій потрапляє в критичну область
, тобто ймовірність того, що статистичний критерій потрапляє в критичну область 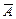 , дорівнює малій імовірності a. Якщо ж виявиться, що
, дорівнює малій імовірності a. Якщо ж виявиться, що 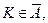 а ця подія малоймовірна і все ж відбулася, то немає підстав приймати нульову гіпотезу.
а ця подія малоймовірна і все ж відбулася, то немає підстав приймати нульову гіпотезу.
Пропонується такий алгоритм перевірки правильності Н0:
1. Сформулювати Н0 й одночасно альтернативну гіпотезу Нa.
2. Вибрати статистичний критерій, який відповідав би сформульованій нульовій гіпотезі.
3. Залежно від змісту нульової та альтернативної гіпотез будується правобічна, лівобічна або двобічна критична область, а саме:
нехай 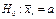 , тоді, якщо
, тоді, якщо
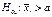 , то вибирається правобічна критична область, якщо
, то вибирається правобічна критична область, якщо
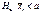 , то вибирається лівобічна критична область і коли
, то вибирається лівобічна критична область і коли
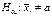 , то вибирається двобічна критична область.
, то вибирається двобічна критична область.
4. Для побудови критичної області (лівобічної, правобічної чи двобічної) необхідно знайти критичні точки. За вибраним статистичним критерієм та рівнем значущості a знаходяться критичні точки.
5. За результатами вибірки обчислюється спостережуване значення критерію 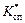 .
.
6. Відхиляють чи приймають нульову гіпотезу на підставі таких міркувань:
у разі, коли 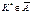 , а це є малоймовірною випадковою по-
, а це є малоймовірною випадковою по-
дією, 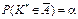 і, незважаючи на це, вона відбулася, то в цьому разі Н0 відхиляється:
і, незважаючи на це, вона відбулася, то в цьому разі Н0 відхиляється:
для лівобічної критичної області
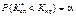 ; (441)
; (441)
для правобічної критичної області
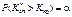 ; (442)
; (442)
для двобічної критичної області
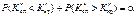 (443)
(443)
або
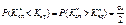 , (444)
, (444)
ураховуючи ту обставину, що критичні точки 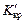 і
і 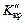 симетрично розташовані відносно нуля.
симетрично розташовані відносно нуля.
60. Помилки першого та другого роду. Потужність критерію
Якою б не була малою величина a, потрапляння спостережуваного значення 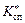 у критичну область
у критичну область 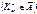 ніколи не буде подією абсолютно неможливою. Тому не виключається той випадок, коли Н0 буде правильною, а
ніколи не буде подією абсолютно неможливою. Тому не виключається той випадок, коли Н0 буде правильною, а 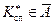 , а тому нульову гіпотезу буде відхилено.
, а тому нульову гіпотезу буде відхилено.
Отже, при перевірці правильності Н0 можуть бути допущені помилки. Розрізняють при цьому помилки першого і другого роду.
Якщо Н0 є правильною, але її відхиляють на основі її перевірки, то буде допущена помилка першого роду.
Якщо Н0 є неправильною, але її приймають, то в цьому разі буде допущена помилка другого роду.
Між помилками першого і другого роду існує тісний зв’язок.
Нехай, для прикладу, перевіряється 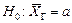 . При великих обсягах вибірки n
. При великих обсягах вибірки n 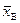 , як випадкова величина, закон розподілу ймовірностей якої асимптотично наближатиметься до нормального з числовими характеристиками:
, як випадкова величина, закон розподілу ймовірностей якої асимптотично наближатиметься до нормального з числовими характеристиками:
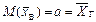 ,
, 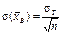 .
.
Тому, коли гіпотеза Н0є правдивою, 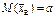 . Цей розподіл має такий вигляд (рис. 122, крива f (x; a)).
. Цей розподіл має такий вигляд (рис. 122, крива f (x; a)).
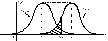
Рис. 122
Коли альтернативна гіпотеза заперечує Н0 і стверджує 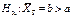 , то в цьому разі нормальна крива буде зміщена праворуч (на рис. 122, крива f (x; b)).
, то в цьому разі нормальна крива буде зміщена праворуч (на рис. 122, крива f (x; b)).
За вибраним рівнем значущості a визначається критична область (рис. 122).
Коли 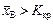 , то Н0 відхиляється з імовірністю помилки першого роду:
, то Н0 відхиляється з імовірністю помилки першого роду:
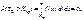 (445)
(445)
Коли 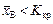 , то Н0 не відхиляється, хоча може бути правильною альтернативна гіпотеза Нa.
, то Н0 не відхиляється, хоча може бути правильною альтернативна гіпотеза Нa.
Отже, в цьому разі припускаються помилки другого роду.
Імовірність цієї помилки, яку позначають символом b, може бути визначена на кривій f (x; b), а саме:
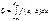 . (446)
. (446)
Ця ймовірність на рис. 122 показана штрихуванням площі під кривою f (x; b), що міститься ліворуч Kкр.
Якщо з метою зменшення ризику відхилити правильну гіпотезу Н0 зменшуватимемо значення a, то в цьому разі критична точка Kкр зміщуватиметься праворуч, що, у свою чергу, спричинює збільшення ймовірності помилки другого роду, тобто величини b.
Різницю 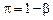 називають імовірністю обґрунтованого відхилення Н0, або потужністю критерію.
називають імовірністю обґрунтованого відхилення Н0, або потужністю критерію.
Під час розв’язування практичних завдань може виникнути потреба вибору статистичного критерію з їх певної множини. У цьому разі вибирають той критерій, якому притаманна найбільша потужність.
61.Елементи дисперсійного аналізу.Дисперсійний аналіз був створений спочатку для статистичної обробки агрономічних дослідів. В наш час його також використовують як в економічних експериментах, так і технічних, соціальних.
Сутність цього аналізу полягає в тому, що загальну дисперсію досліджуваної ознаки розділяють на окремі компоненти, які обумовлені впливом певних конкретних чинників. Істотність їх впливу на цю ознаку здійснюється методом дисперсійного аналізу.
Відповідно до дисперсійного аналізу будь-який його результат можна подати у вигляді суми певної кількості компонент. Так, наприклад, якщо досліджується вплив певного чинника на результат експерименту, то модель, що описує структуру останнього, можна подати так:
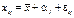 , (467)
, (467)
де 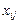 — значення ознаки Х, одержане при i-му експерименті на
— значення ознаки Х, одержане при i-му експерименті на
j-му рівні фактора. Під рівнем фактора розуміють певну його міру. Наприклад, якщо фактором є добрива, які вносяться в ґрунт з метою збільшення врожайності сільськогосподарської культури, то рівнем фактора в цьому разі є кількість добрива, що вноситься в ґрунт; 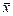 — загальна середня величина ознаки Х;
— загальна середня величина ознаки Х; 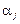 — ефект впливу фактора на значення ознаки Х на j-му рівні;
— ефект впливу фактора на значення ознаки Х на j-му рівні; 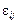 — випадкова компонента, що впливає на значення ознаки Х в i-му експерименті на j-му рівні.
— випадкова компонента, що впливає на значення ознаки Х в i-му експерименті на j-му рівні.
При цьому 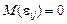 і як випадковi величини мають закон розподілу ймовірностей
і як випадковi величини мають закон розподілу ймовірностей 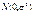 і між собою незалежні (
і між собою незалежні ( 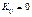 ).
).
Складнішою моделлю аналізу є вивчення впливу на результати експерименту кількох факторів. Зокрема при аналізі впливу двох факторів структура моделі набуває такого вигляду:
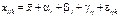 , (468)
, (468)
де 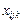 — значення ознаки Х в i-му експерименті на j-му рівні впливу фактора А і на k-му рівні впливу фактора В; — загальна середня величина ознаки Х;
— значення ознаки Х в i-му експерименті на j-му рівні впливу фактора А і на k-му рівні впливу фактора В; — загальна середня величина ознаки Х; 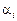 — ефект впливу фактора А на i-му рівні;
— ефект впливу фактора А на i-му рівні; 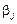 — ефект впливу фактора B на j-му рівні;
— ефект впливу фактора B на j-му рівні; 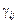 — ефект одночасного впливу факторів А і В;
— ефект одночасного впливу факторів А і В; 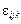 — випадкова компонента.
— випадкова компонента.
Нехай потрібно дослідити вплив на ознаку Х певного одного фактора. Результати експерименту ділять на певне число груп, які відрізняються між собою ступенем дії фактора
Відповідно до моделі однофакторного дисперсійного аналізу необхідно визначити дві дисперсії, а саме: міжгрупову (дисперсію групових середніх), зумовлену впливом досліджуваного фактора на ознаку Х, і внутрішньогрупову, зумовлену впливом інших випадкових факторів.
Загальна дисперсія розглядається як сума квадратів відхилень:
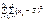 .Тоді поділ загальної дисперсії на компоненти здійснюється так:
.Тоді поділ загальної дисперсії на компоненти здійснюється так:
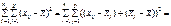
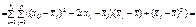
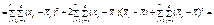
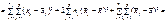
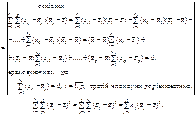
Таким чином, дістаємо:
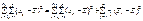 . (469)
. (469)
де 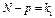 є числом ступенів свободи для
є числом ступенів свободи для 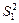 , оскільки при цьому використовується р співвідношень при обчисленні групових середніх
, оскільки при цьому використовується р співвідношень при обчисленні групових середніх 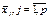 .
.
Виправлена дисперсія 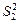 , що характеризує розсіювання групових середніх
, що характеризує розсіювання групових середніх 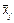 відносно загальної середньої
відносно загальної середньої 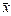 , яке викликане впливом фактора на результат експерименту ознаки Х, обчислюється за формулою:
, яке викликане впливом фактора на результат експерименту ознаки Х, обчислюється за формулою:
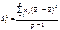 , (472)
, (472)
де 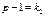 — це число ступенів свободи для , оскільки групові середні варіюють відносно однієї загальної середньої .
— це число ступенів свободи для , оскільки групові середні варіюють відносно однієї загальної середньої .
Порівняння двох дисперсій ґрунтується на перевірці правильності нульової гіпотези: 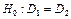 — про рівність дисперсій двох вибірок.
— про рівність дисперсій двох вибірок.
За статистичний критерій вибирається випадкова величина
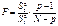 , (473)
, (473)
що має розподіл Фішера—Снедекора з 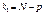 ,
, 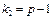 ступенями свободи.
ступенями свободи.
За значеннями a, , 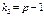 , знаходимо критичну точку
, знаходимо критичну точку
62. Двофакторний дисперсійний аналіз
Нехай необхідно визначити вплив двох факторів А і В на певну ознаку Х. Для цього необхідно, щоб дослід здійснювався при фіксованих рівнях факторів А і В, а також їх одночасній дії на ознаку. При цьому дослід здійснюватимемо n раз для кожного з рівнів факторів А і В.
Позначимо через конкретне значення ознаки Х, якого вона набуває при i-му експерименті, j-му рівні фактора A і k-му рівні фактора В.
Результат експерименту зручно подати у вигляді таблиці, яка поділена на блоки, в кожному з яких ураховується на певних рівнях факторів А і В їх вплив на конкретні значення ознаки 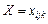 (табл. 3).
(табл. 3).
Виходячи з даних табл., 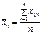 (474)
(474)
є середнім значенням ознаки Х для кожного блока;
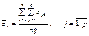 (475)
(475)
є середнім значенням ознаки Х за стовпцями;
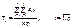 (476)
(476)
є середнім значенням ознаки Х за рядками;
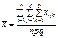 (477)
(477)
є загальною середньою ознакою Х;
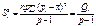 (478)
(478)
є виправленою дисперсією, яка зумовлена впливом фактора А на ознаку Х;
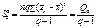 (479)
(479)
є виправленою дисперсією, яка зумовлена впливом фактора В на ознаку Х;
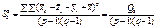 (480)
(480)
є виправленою дисперсією, яка зумовлена одночасним впливом на ознаку Х факторів А і В;
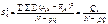 (481)
(481)
є виправленою дисперсією, яка зумовлена впливом на ознаку Х інших, не головних факторів.
Обчислюються спостережувані значення критерію
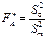 ;
; 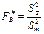 ;
; 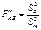 .
.
При рівні значущості a визначають критичні точки:
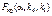 ,
, 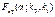 ,
, 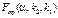 .
.
Якщо:
1) 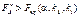 , то нульова гіпотеза про відсутність впливу фактора А відхиляється;
, то нульова гіпотеза про відсутність впливу фактора А відхиляється;
2) 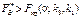 , то нульова гіпотеза про відсутність впливу фактора В відхиляється;
, то нульова гіпотеза про відсутність впливу фактора В відхиляється;
3) 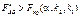 , то нульова гіпотеза про відсутність спільного впливу факторів А і В відхиляється.
, то нульова гіпотеза про відсутність спільного впливу факторів А і В відхиляється.
63.Елементи теорії регресії і кореляції.
Кожній величині, яку дістають у результаті проведення експерименту, притаманний елемент випадковості, що виявляється більшою чи меншою мірою залежно від її природи.
При сумісній появі двох і більше величин у результаті проведення експерименту дослідник має підстави для встановлення певної залежності між ними, зв’язку.
Показником, що вимірює стохастичний зв’язок між змінними, є коефіцієнт кореляції, який свідчить з певною мірою ймовірності, наскільки зв’язок між змінними близький до строгої лінійної залежності.
За наявності кореляційного зв’язку між змінними необхідно виявити його форму функціональної залежності (лінійна чи нелінійна), а саме:
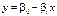 ; (482)
; (482)
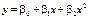 ; (483)
; (483)
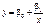 . (484)
. (484)
Наведені можливі залежності між змінними X і Y (482), (483), (484) називають функціями регресії. Форму зв’язку між змінними X і Y можна встановити, застосовуючи кореляційні поля, які зображені на рисунках 147—149.
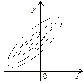 Рис. 147
Рис. 147
| 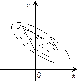 Рис. 148
Рис. 148
|  Рис. 149
Рис. 149
|
Тут кожній точці з координатами xi, yi відповідає певне числове значення ознак X та Y.
На рис. 147 більшість точок утворюють множину, що має тенденцію при збільшенні значень X зумовлювати збільшення значень ознаки Y.
На рис. 148 множина точок має тенденцію при збільшенні значень Х зумовлювати зменшення Y.
На рис. 149 точки рівномірно розміщені на координатній площині х0y, що свідчить про відсутність кореляційної залежності між ознаками Х і Y.
Отже, на основі розміщення точок кореляційного поля дослідник має підстави для гіпотетичного припущення про лінійні чи нелінійні залежності між ознаками Х і Y.
Для двовимірного статистичного розподілу вибірки ознак (Х, Y) поняття статистичної залежності між ознаками Х та Y має таке визначення:
статистичною залежністю Х від Y називають таку, за якої при зміні значень ознаки Y = yi змінюється умовний статистичний розподіл ознаки Х, статистичною залежністю ознаки Y від Х називають таку, за якої зі зміною значень ознаки X = xi змінюється умовний статистичний розподіл ознаки Y.
Звідси випливає визначення кореляційної залежності між ознаками X і Y. Кореляційною залежністю ознаки X від Y називається функціональна залежність умовного середнього 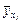 від аргументу х, що можна записати так:
від аргументу х, що можна записати так:
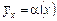 .
.
 Аналогічно кореляційною залежністю ознаки X від Y називається функціональна залежність умовного середнього
Аналогічно кореляційною залежністю ознаки X від Y називається функціональна залежність умовного середнього 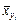 від аргументу y, що можна записати, так:
від аргументу y, що можна записати, так:
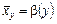 .
.
Між ознаками Х та Y може існувати статистична залежність і за відсутності кореляційної. Але коли існує кореляційна залежність між ознаками Х та Y, то обов’язково між ними існуватиме і статистична залежність.
64. Рівняння лінійної парної регресії
 Нехай між змінними Х та Y теоретично існує певна лінійна залежність. Це твердження може ґрунтуватися на тій підставі, наприклад, що кореляційне поле для пар
Нехай між змінними Х та Y теоретично існує певна лінійна залежність. Це твердження може ґрунтуватися на тій підставі, наприклад, що кореляційне поле для пар 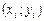 має такий вигляд (рис. 150).
має такий вигляд (рис. 150).
Як бачимо, насправді між ознаками Х і Y спостерігається не такий тісний зв’язок, як це передбачає функціональна залежність.
Окремі спостережувані значення y, як правило, відхилятимуться від передбаченої лінійної залежності під впливом випадкових збудників, які здебільшого є невідомими. Відхилення від передбаченої лінійної форми зв’язку можуть статися внаслідок неправильної специфікації рівняння, тобто ще з самого початку неправильно вибране рівняння, що описує залежність між X і Y.
Будемо вважати, що специфікація рівняння вибрана правильно. Ураховуючи вплив на значення Y збурювальних випадкових факторів, лінійне рівняння зв’язку X і Y можна подати в такому вигляді:
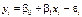 , (485)
, (485)
де 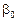 ,
, 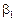 є невідомі параметри регресії,
є невідомі параметри регресії, 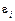 є випадковою змінною, що характеризує відхилення y від гіпотетичної теоретичної регресії.
є випадковою змінною, що характеризує відхилення y від гіпотетичної теоретичної регресії.
Отже, в рівнянні (485) значення «y» подається у вигляді суми двох частин: систематичної 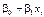 і випадкової
і випадкової 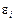 . Параметри , є невідомими величинами, а є випадковою величиною, що має нормальний закон розподілу з числовими характеристиками:
. Параметри , є невідомими величинами, а є випадковою величиною, що має нормальний закон розподілу з числовими характеристиками: 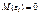 ,
, 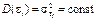 . При цьому елементи послідовності
. При цьому елементи послідовності 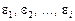 є некорельованими
є некорельованими 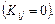
У результаті статистичних спостережень дослідник дістає характеристики для незалежної змінної х і відповідні значення залежної змінної у.
 Отже, необхідно визначити параметри ,
Отже, необхідно визначити параметри , 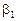 . Але істинні значення цих параметрів дістати неможливо, оскільки ми користуємося інформацією, здобутою від вибірки обмеженого обсягу. Тому знайдені значення параметрів будуть лише статистичними оцінками істинних (невідомих нам) параметрів , . Якщо позначити параметри
. Але істинні значення цих параметрів дістати неможливо, оскільки ми користуємося інформацією, здобутою від вибірки обмеженого обсягу. Тому знайдені значення параметрів будуть лише статистичними оцінками істинних (невідомих нам) параметрів , . Якщо позначити параметри 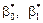 , які дістали способом обробки вибірки, моделі
, які дістали способом обробки вибірки, моделі
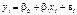 (486)
(486)
відповідатиме статистична оцінка
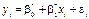 . (487)
. (487)
65. Визначення параметрів 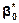 ,
, 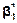 .Якщо ми прийняли гіпотезу про лінійну форму зв’язку між ознаками Х і Y, то однозначно вибрати параметри
.Якщо ми прийняли гіпотезу про лінійну форму зв’язку між ознаками Х і Y, то однозначно вибрати параметри 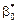 ,
, 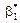 , які є точковими статистичними оцінками відповідно для параметрів , , практично неможливо. І справді, через кореляційне поле (рис. 150) можна провести безліч прямих. Тому необхідно вибрати такий критерій, за яким можна здійснити вибір параметрів , .
, які є точковими статистичними оцінками відповідно для параметрів , , практично неможливо. І справді, через кореляційне поле (рис. 150) можна провести безліч прямих. Тому необхідно вибрати такий критерій, за яким можна здійснити вибір параметрів , .
На практиці найчастіше параметри , визначаються за методом найменших квадратів, розробка якого належить К. Гауссу і П. Лапласу. Цей метод почали широко застосовувати в економіко-статистичних обчисленнях, відколи була створена теорія регресії.
Відповідно до цього методу рівняння лінійної парної регресії 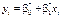 необхідно вибрати так, щоб сума квадратів відхилень спостережуваних значень від лінії регресії була б мінімальною.
необхідно вибрати так, щоб сума квадратів відхилень спостережуваних значень від лінії регресії була б мінімальною.
Для цього розглянемо графік (рис. 151):
Через кореляційне поле проведена лінія регресії 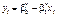 . Відхилення будь-якої точки із координатами xi, yi становить величину :
. Відхилення будь-якої точки із координатами xi, yi становить величину :
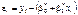 . (488)
. (488)
Тут: yi — спостережуване значення ознаки Y, яке дістали внаслідок реалізації вибірки; 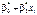 — значення ознаки Y, обчислене за умови, що X = xi.
— значення ознаки Y, обчислене за умови, що X = xi.
Як бачимо, величина є функцією від параметрів 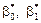 . Функція від цих параметрів і буде узагальнюючим показником розсіювання точок навколо прямої, а саме:
. Функція від цих параметрів і буде узагальнюючим показником розсіювання точок навколо прямої, а саме:
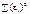 . (489)
. (489)
Звідси є сенс узяти критерій, згідно з яким параметри , 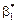 необхідно добирати так, щоб сума квадратів відхилень
необхідно добирати так, щоб сума квадратів відхилень 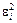 була мінімальною:
була мінімальною:
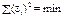 (490)
(490)
Позначивши 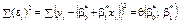 , розглянемо необхідну умову існування мінімуму функції
, розглянемо необхідну умову існування мінімуму функції 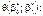
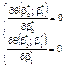 (491)
(491)
Дістанемо лінійне рівняння відносно параметрів , :
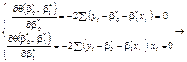
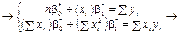
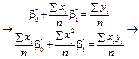
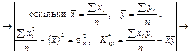
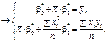 (492)
(492)
Розв’язавши систему (492) відносно параметрів 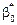 ,
, 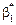 , знайдемо:
, знайдемо:
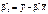 ; (493)
; (493)
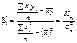 . (494)
. (494)
Помноживши ліву і праву частини (494) на 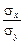 , дістанемо:
, дістанемо:
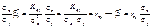 , (495)
, (495)
де rxy —парний коефіцієнт кореляції між ознаками X і Y. Тоді
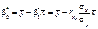 . (496)
. (496)
З урахуванням (495), (496) рівняння лінійної парної регресії набере такого вигляду:
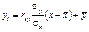 (497)
(497)
або
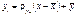 , (498)
, (498)
де 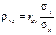 і називають коефіцієнтом регресії.
і називають коефіцієнтом регресії.
Приклад. Залежність розчинності уі тіосульфату від температури хі наведено парним статистичним розподілом вибірки:
| Y = yi | 33,5 | 37,0 | 41,2 | 46,1 | 50,0 | 52,9 | 56,8 | 64,3 | 69,9 |
| X = xi |
Потрібно: 1) побудувати кореляційне поле залежності ознаки Y від X;
2) визначити точкові незміщені статистичні оцінки 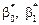 . Обчислити rxy ;
. Обчислити rxy ;
3) побудувати графік лінії регресії.
Розв’язання. 1) кореляційне поле залежності ознаки Y від X має такий вигляд (рис. 152).
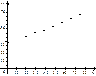
Рис. 152
З рис. 152 бачимо, що зі збільшенням значень ознаки 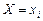 залежна зміна
залежна зміна 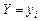 має тенденцію до збільшення.
має тенденцію до збільшення.
Тому припускаємо, що між ознаками Х та Y існує лінійна функціональна залежність
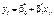
2) для визначення параметрів 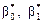 скористаємося таблицею, що має такий вигляд:
скористаємося таблицею, що має такий вигляд:
| № з/п | хі | уі | 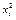
| хі уі | 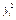
|
| 33,5 | 1122,25 | ||||
| 37,0 | 1369,00 | ||||
| 41,2 | 1697,44 | ||||
| 46,1 | 2125,21 | ||||
| 50,0 | 2500,00 | ||||
| 52,9 | 2798,41 | ||||
| 56,8 | 3226,24 | ||||
| 64,3 | 4134,49 | ||||
| 69,9 | 4886,01 | ||||
| Σ | 451,7 | 23859,05 |
Скориставшись формулами (494), (496), дістанемо
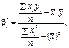
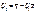
Оскільки n = 9, 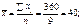
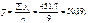
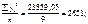
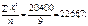
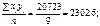
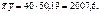
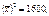 одержимо:
одержимо:
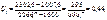
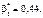
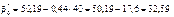
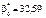
Отже, рівняння регресії буде таким:
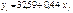
Для обчислення 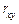 необхідно знайти
необхідно знайти 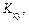
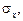
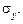
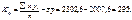
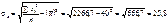 ;
;
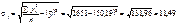 ;
;
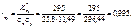
Як бачимо, коефіцієнт кореляції близький за своїм значенням до одиниці, що свідчить про те, що залежність між Х та Y є практично лінійною.
Графік парної лінійної функції регресії подано на рис. 153.
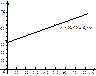
Рис. 153
Якщо параметри 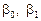 рівняння (486) — сталі величини, то
рівняння (486) — сталі величини, то 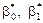 , які обчислені шляхом обробки реалізованої вибірки, є випадковими величинами і виконують функцію точкових статистичних оцінок для них.
, які обчислені шляхом обробки реалізованої вибірки, є випадковими величинами і виконують функцію точкових статистичних оцінок для них.
66. Властивості 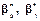 .Точкові статистичні оцінки
.Точкові статистичні оцінки 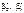 можна подати в такому вигляді:
можна подати в такому вигляді:
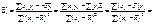
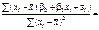
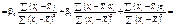
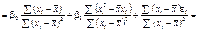
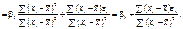
 Оскільки
Оскільки 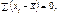
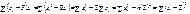
Отже, дістали:
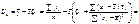
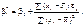 (499)
(499)
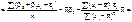
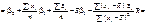
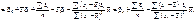
Остаточно маємо:
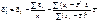 .
. 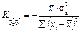 (500)
(500)
Рівняння регресії можна подати в такому вигляді:
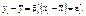
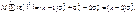
Звідси маємо
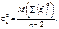
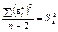
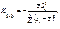 1)є точковою незміщеною статистичною для
1)є точковою незміщеною статистичною для 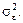
З наведених вище перетворень можна зробити висновок, що:
випадкова величина
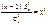 (519)матиме розподіл
(519)матиме розподіл 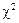 із
із 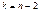 ступенями свободи;випадкові величини:
ступенями свободи;випадкові величини: 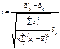
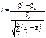
матимуть розподіл Стьюдента (t-розподіл) із 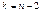 ступенями свободи.
ступенями свободи.
67. Довірчі інтервали для 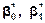 .Побудова довірчого інтервалу для параметра
.Побудова довірчого інтервалу для параметра 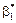 із заданою надійністю γ здійснюється використовуючи (520). Отже, маємо:
із заданою надійністю γ здійснюється використовуючи (520). Отже, маємо:
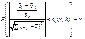
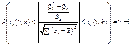
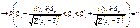 .
.
Отже, довірчий інтервал для параметра 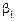 буде
буде
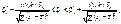 (521)
(521)
де 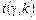 знаходимо за таблицею (додаток 3) за заданою надійністю γ і числом ступенів свободи
знаходимо за таблицею (додаток 3) за заданою надійністю γ і числом ступенів свободи 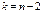 ;
;
Побудова довірчого інтервалу для параметра із заданою надійністю γ.
Аналогічно скориставшись (520), маємо
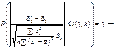
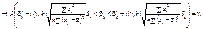
Отже, довірчий інтервал для параметра буде таким:
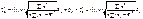 (522)
(522)
68. Множинна лінійна регресія. На практиці здебільшого залежна змінна 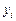 пов’язана з впливом не одного, а кількох аргументів. У цьому разі регресію називають множинною. При цьому якщо аргументи в функції регресії в першій степені, то множинна регресія називається лінійною, у противному разі — множинною нелінійною регресією.Деякі елементи матричної алгебри:
пов’язана з впливом не одного, а кількох аргументів. У цьому разі регресію називають множинною. При цьому якщо аргументи в функції регресії в першій степені, то множинна регресія називається лінійною, у противному разі — множинною нелінійною регресією.Деякі елементи матричної алгебри:
а) норма вектора. Ортогональні вектори і матриці
Якщо 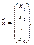 тоді
тоді 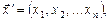 тоді норма вектора
тоді норма вектора 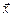 буде число, яке дістанемо за формулою
буде число, яке дістанемо за формулою
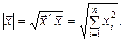 (534)
(534)
У разі, коли 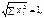 то вектор називають нормованим. Якщо для квадратної матриці А виконується рівність
то вектор називають нормованим. Якщо для квадратної матриці А виконується рівність 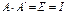 (E — одинична матриця
(E — одинична матриця 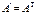 ), то вона називається ортогональною;
), то вона називається ортогональною;
б) диференціювання векторів
Нехай задано два вектори 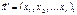
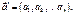 тоді
тоді
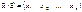
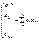
маємо:
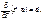
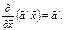 (535)
(535)
(536)
Дата добавления: 2014-11-29; просмотров: 1385;