Помните, что большинство журналов доступны для чтения только привилегированным пользователям! Для получения привилегий воспользуйтесь командами su или sudo.
Для ведения журналов в операционной системе Debian GNU/Linux используется демон rsyslogd. Его базовая настройка выполняется в файле /etc/rsyslog.conf, а дополнительные (пользовательские) правила размещаются в файлах, находящихся в директории /etc/rsyslog.d. Указанный демон имеет развитую систему правил, благодаря которой каждое пришедшее сообщение может быть классифицировано и сохранено в том или и ином файле журнала. Более подробно узнать о том, как это делается можно из документации [1].
Не смотря на все плюсы rsyslogd, исторически так сложилось, что высоконагруженные приложения, которые обязаны сохранять всю без исключения информацию о действиях пользователя, ведут файлы журналов самостоятельно. Дело в том, что rsyslogd и его предшественник syslogd принимают сообщения, используя протокол UDP, который не гарантирует доставку сообщений, а значит, в файлах журналов могут быть сохранены не все события.
Для определения ядра пользовательской аудитории веб-сайта в целях противодействия DDoS-атакам необходимо собрать информацию по пользователям, их IP-адресам и по тому, когда и какую информацию они просматривают на сайте. Для этих целей удобно использовать файлы журналов веб-сервера.
На сегодняшний день на высоконагруженных веб-сайтах на запросы пользователей в первую очередь отвечает веб-сервер nginx. Такой приоритет ему отдан благодаря его лёгкости, но в тоже время функциональности и отказоустойчивости. После получения запроса от пользователя nginx принимает решение в зависимости от настроек ответить ли пользователю самостоятельно (например, переслать существующий файл), передать запрос для дальнейшей обработки в другую программу (например, в apache с модулем php), поставить запрос в очередь, либо прервать его выполнение. Таким образом, можно быть уверенным, что все HTTP запросы к веб-сайту будут отображены в журналах доступа nginx.
Как правило, размещение файлов-журналов nginx настраивается в конфигурационных файлах каждого узла в папке /etc/nginx/sites-available. За это отвечают параметры access_log и error_log в секции server.
ü access_log – путь к журналу доступа, куда пишутся все выполненные запросы и IP-адреса клиентов.
ü error_log – путь к журналу ошибок, куда пишутся все запросы, завершённые с ошибкой и IP-адреса клиентов.
Nginx ведёт файлы журналов самостоятельно, без использования демона rsyslogd, так как в случае большого количества запросов (например, в случае DDoS-атаки) rsyslogd не сможет гарантировать запись всех обращений пользователей в журнал, что приведёт к проблемам в безопасности системы.
Если системный администратор не предусмотрел иного размещения файлов-логов, то журналы доступа хранятся в /var/log/nginx/example.com-access.log, а ошибок в /var/log/nginx/example.com-error.log, где example.com это название узла, для которого сохраняется журнал в этом файле. Как правило, для каждого узла используется свой файл журнала. Иногда системные администраторы перемещают соответствующие файлы журналов узла в подпапку пользователя на виртуальном хостинге, чтобы дать доступ пользователю к журналам узла, за который он отвечает по протоколу FTP и т.п.
Необходимо понимать, что директория, в которой хранятся файлы журналов имеет конечный размер и рано или поздно место в ней закончится, если не удалять старые файлы. Для этих целей в Debian GNU/Linux предоставляется утилита logrotate. Это мощное средство, позволяющее задать для разных типов журналов различный период ротации (удаление старых файлов и создание новых), сжатие и удержание в течение определённого времени старых файлов журналов.
Глобальные настройки logrotate хранятся в файле /etc/logrotate.conf, но часто они конкретизированы для определённых журналов в /etc/logrotate.d. Например, по умолчанию файл /etc/logrotate.d/nginx выглядит следующим образом:
| /var/log/nginx/*.log { #фильтр файлов, к которым применяются правила daily #ежедневная ротация файлов журнала missingok #в случае отсутствия файла журнала перейти к обработке следующего не выдавая сообщения об ошибке rotate 52 #файл журнала будет удалён через 52 ротации compress #старые версии файлов журнала будут сжаты (по умолчанию gzip) delaycompress #отложить сжатие предыдущего файла журнала до следующего циклического сдвига notifempty #не сдвигать журнал, если он пуст create 0640 www-data adm #непосредственно после обращения (перед выполнением скрипта postrotate) создать файл журнала (с тем же именем, что и только что сдвинутый журнал), задать режим доступа к файлу 0640, владельца www-data и группу adm sharedscripts #указывает, что скрипты prerotate и postrotate будут выполняться только один раз, вне зависимости от количества файлов, подходящих под шаблон /var/log/nginx/*.log prerotate #нижеследующий скрипт будет выполнен перед ротацией журнала и только в случае, если журнал действительно будет сдвинут #выполняет файлы в директории httpd-prerotate в случае существования (по умолчанию отсутствует) if [ -d /etc/logrotate.d/httpd-prerotate ]; then \ run-parts /etc/logrotate.d/httpd-prerotate; \ fi; \ endscript postrotate #нижеследующий скрипт будет выполнен после ротации журнала и только в случае, если журнал действительно будет сдвинут #отправляет демону nginx сигнал на ротацию логов [ ! -f /var/run/nginx.pid ] || kill -USR1 `cat /var/run/nginx.pid` endscript } |
Приведённая выше конфигурация говорит о том, что файлы в директории /var/log/nginx с расширением *.log будут ротироваться раз в сутки. При этом к имени файла будет добавляться номер его ротации, например example.com-access.log.1, а на его месте будет создан новый файл с именем example.com-access.log. Начиная со второй ротации, файл будет сжат и к его первоначальному имени помимо номера ротации будет добавлено расширение архива, например example.com-access.log.2.gz. Такое поведение обусловлено механизмом inode в файловой системе Linux, при которой имя файла используется лишь для поиска соответствующей inode в файловой системе. В дальнейшем доступ к файлу происходит именно по inode вне зависимости от имени файла, его размещения и даже существования, так как можно отправить команду удаления файла, которая удалит имя файла, но фактически он будет доступен, пока есть программы, которые держат открытыми inode этого файла. То есть сначала logrotate изменяет имя файла журнала, затем создаёт новый файл со старым именем и отправляет уведомление о ротации демону nginx, который в свою очередь имеет возможность завершить все необходимые операции ввода-вывода со старым файлом и только после этого начать запись в новый файл. В связи с тем, что у logrotate нет информации о том, в какой момент nginx освободит старый файл, архивирование при первой ротации не производится. При следующей ротации файл example.com-access.log.2.gz будет переименован в example.com-access.log.3.gz и так далее до 52. При ротации файл example.com-access.log.52.gz будет удалён.
Более подробную информацию по настройкам logrotate можно получить по команде man logrotate или в русскоязычном варианте в источнике [2].
Для формирования пользовательского ядра аудитории необходимо собрать, а затем обработать файлы журналов веб-сервера nginx минимум за месяц. Конечно, такой длительный рутинный процесс нужно автоматизировать. В данном случае можно либо поменять настройки logrotate таким образом, чтобы файлы логов не удалялись более длительное время и собирались без сжатия. Для этого нужно удалить опции compress и delaycompress для отмены сжатия, а также notifempty – чтобы ежедневно иметь новый файл, даже если он пустой. Rotate нужно установить в значение 100 и более, но необходимо учесть, что слишком большое значение приведёт к замедление выполнения logrotate и лишней нагрузке на файловую систему, так как при каждой ротации будут переименоваться большое количество файлов.
Более универсальным решением будет оставить настройки ротации журнала nginx по умолчанию, а вместо этого создать директорию /etc/logrotate.d/httpd-prerotate и в ней файл nginx следующего содержания:
| cp /var/log/nginx/example.com-access.log.1 /var/archive/`date +\%F` |
Запуск этого скрипта задан в файле /etc/logrotate.d/nginx (ранее он был рассмотрен). По умолчанию он выполняется один раз перед ротацией журналов. Скрипт состоит всего из одной строчки, написанной на bash, и производит копирование файла /var/log/nginx/example.com-access.log.1 в файл с именем /var/archive/`date +\%F`. Последняя часть команды взята в апострофы и при интерпретации bash будет заменена результатом выполнения команды date +\%F, то есть текущей датой в формате гггг-мм-дд. Директорию /var/archive необходимо создать вручную и позаботиться, чтобы в ней всегда хватало места для накопления архивов журнала.
Как правило, по умолчанию любой веб-сервер ведёт файлы журналов доступа в стандартизованном NCSA формате Common Log Format [3] или в более актуальном Extended Common Log Format (Combined Log Format) [4]. Они представляют собой несколько последовательно записанных через запятую параметров:
| remotehost rfc931 authuser [date] "request" status bytes referrer agent |
remotehost
IP-адрес или DNS-имя клиента, сделавшего запрос.
rfc931
Имя пользователя удалённой машины, с которой отправлен запрос. Современные веб-сервера не запрашивают эту информацию, поэтому данное поле всегда “-”.
authuser
Имя пользователя при включенной HTTP-аутентификации на веб-сервере. Как правило, на общедоступных серверах HTTP-аутентификация не производится и это поле задано в “-”.
[date]
Дата и время получения запроса.
"request"
Первая строка заголовка запроса, полученная от клиента.
status
Статус ответа на запрос.
bytes
Размер переданного документа в байтах.
Следующие два параметра записываются только при использовании Extended Common Log Format. Эта информация передаётся браузером пользователя и ей нельзя полностью доверять.
referrer
Страница, с которой производится переход.
agent
Информация о браузере пользователя, его операционной системе и некоторых дополнительных настройках программного окружения.
В настоящее время по умолчанию nginx настроен на ведение журнала в ECLF формате. Пример нескольких записей ECLF из файла журнала nginx:
| 127.0.0.1 - frank [09/Aug/2014:06:25:02 +0400] "GET /apache_pb.gif HTTP/1.0" 200 2326 "http://www.example.com/start.html" "Mozilla/4.08 [en] (Win98; I ;Nav)" 31.184.219.88 - - [09/Aug/2014:06:25:03 +0400] "GET /groups/19541 HTTP/1.0" 200 4334 "-" "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_9_2) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/33.0.1750.152 Safari/537.36" 5.255.253.92 - - [09/Aug/2014:06:25:05 +0400] "GET /friends/18332 HTTP/1.1" 200 4057 "-" "Mozilla/5.0 (compatible; YandexBot/3.0; +http://yandex.com/bots)" |
4.2.Настройка мониторинга трафика с помощью NetFlow
В данном пункте работы рассматривается мониторинг сетевого трафика с использованием протокола NetFlow на базе операционной системы Debian GNU/Linux версии 7.6.0.
NetFlow — сетевой протокол, предназначенный для учёта сетевого трафика, разработанный компанией Cisco Systems. Является фактическим промышленным стандартом и поддерживается не только оборудованием Cisco, но и многими другими устройствами (в частности, Juniper и Enterasys). Также существуют свободные реализации для UNIX-подобных систем. [wiki: NetFlow]
Для сбора информации о трафике по протоколу NetFlow требуются следующие компоненты:
Сенсор – собирает статистику по проходящему через него трафику. Обычно это L3-коммутатор или маршрутизатор, но в рамках данной работы будет показана установка сенсора fprobe на базе компьютера с операционной системой Debian.
Коллектор – собирает получаемые от сенсора данные и помещает их в хранилище. Он может быть организован на отдельном оборудовании с большим дисковым массивом для накопления данных, либо, как в данной работе, установлен совместно с сенсором. Коллектор может быть реализован с помощью программы nfcapd.
Анализатор – обрабатывает собранные коллектором данные и формирует пригодные для чтения человеком отчёты. С целью автоматического обнаружения DDoS-атак анализатор выполнен в виде скрипта и будет рассмотрен далее. Для преобразования в текстовый вид бинарных файлов с записями NetFlow с коллектора используется программа nfdump.
Принципиальная схема защиты сети от DDoS-атак приведена на рисунке 4.1.
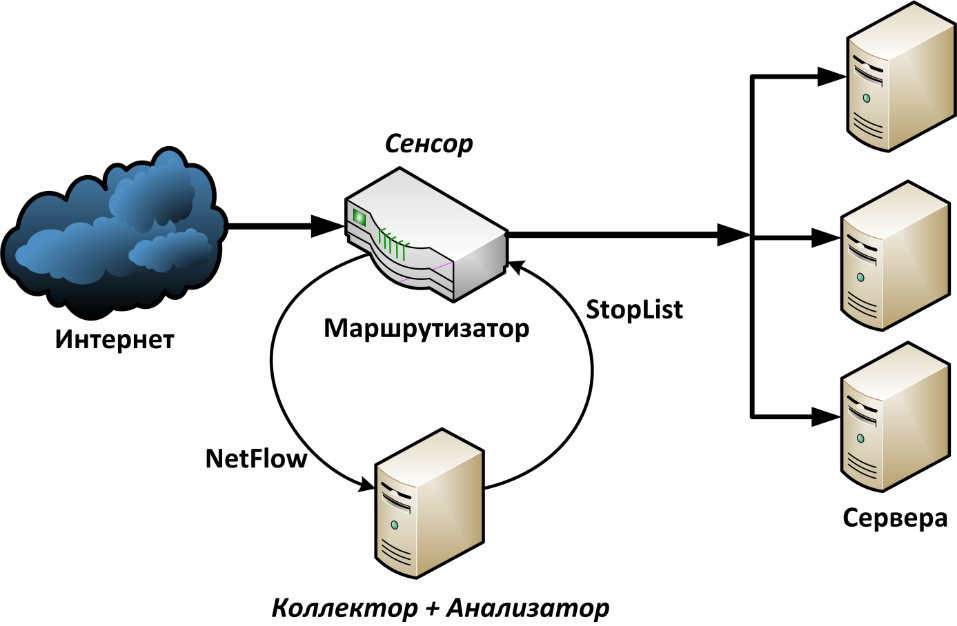
Рисунок 4.1 – Принципиальная схема защиты сети
В рамках данной работе будет показаны принципы организовации защиты на своём рабочем месте, то есть сенсор, коллектор и анализатор необходимо поставить на одном компьютере.
Вывод программы nfdump после обработки бинарного файла NetFlow показан на рисунке 4.2.
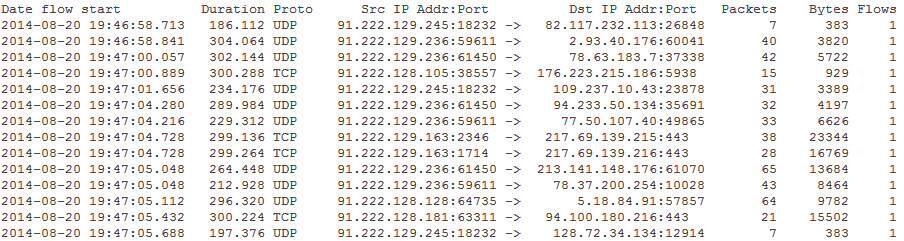
Рисунок 4.2 – Информация NetFlow после обработки программой nfdump
Таким образом, для исследования доступны следующие информационные поля:
Data flow start – время начала потока.
Duration – длительность потока.
Src IP Addr:Port – IP-адрес и порт источника потока.
Dst IP Addr:Port – IP-адрес и порт назначения потока.
Packets – количество пакетов, входящих в поток данных.
Bytes – объём данных, переданных в потоке.
Flows – указывает для какого количества потоков собрана информация. По умолчанию, если не включена агрегация потоков, в этом поле информация об одном потоке.
Формат может быть изменён при необходимости [5].
Первым делом узнаем, какие сетевые интерфейсы присутствуют на компьютере и с какого необходимо собирать статистику. Для этого необходимо выполнить команду ifconfig:
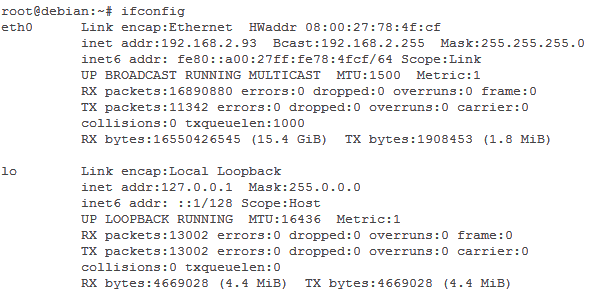
Как правило, отображаются два интерфейса: eth0 – сетевой адаптер Ethernet и lo – сетевой интерфейс замыкания на себя, так называемый localhost. Эта информация понадобится в дальнейшем при настройке. Если на вашем компьютере присутствуют другие сетевые интерфейсы, то необходимо выбрать тот, с которого будет собираться статистика. Как правило, интересует интерфейс, на котором наибольшее количество принятых/отправленных пакетов (поля RX packets и TX packets).
Дата добавления: 2017-03-29; просмотров: 616;