Помните, что большинство команд администрирования доступны только привилегированным пользователям! Для получения привилегий воспользуйтесь командами su или sudo.
Скрипт работает по следующему алгоритму:
1. Каждый файл содержит в себе частичные данные за двое суток: за те, что указаны в его имени, и за прошлые. Необходимо выбрать данные одних календарных суток, которые находятся в двух файлах, например файлы 2014-06-20 и 2014-06-21 содержат полный журнал от 20 июня 2014 года.
2. Обработаем первый файл. Учитывая только данные за 20 июня подсчитаем, сколько обращений было за каждый час в отдельности. Запишем результат в массив.
3. Аналогично нужно поступить со вторым файлом, но новые данные нужно добавлять в тот же массив.
4. Сохраним массив, содержащий почасовое распределение количества запросов к веб-серверу, в файл.
Далее рассмотрим текст скрипта с комментариями:
| <?php // php activity-time.php 2014-06-20 2014-06-21 //Пример использования скрипта if ($argc!=3) exit("Неверное число параметров!\n"); //Проверяется передано ли нужное количество параметров $rgx = '/^201\d-\d\d-(\d\d)$/'; //Регулярное выражение для выборки дня для анализа из первого переданного имени файла. То есть для 2014-06-20 будет выбрано 20. preg_match($rgx, $argv[1], $res); //Сравнение первого параметра с регулярным выражением $rgx и сохранение результата в виде массива в переменную $res $day=$res[1]; //Получаем из массива $res день, для которого проводится анализ, и сохраняем в переменную $day //Инициализация массива для сбора статистики посещений за каждый час в сутках $hours=array( '00' => 0, '01' => 0, '02' => 0, '03' => 0, '04' => 0, '05' => 0, '06' => 0, '07' => 0, '08' => 0, '09' => 0, '10' => 0, '11' => 0, '12' => 0, '13' => 0, '14' => 0, '15' => 0, '16' => 0, '17' => 0, '18' => 0, '19' => 0, '20' => 0, '21' => 0, '22' => 0, '23' => 0 ); day2hours($argv[1], $day, $hours); //Обработка первого файла day2hours($argv[2], $day, $hours); //Обработка второго файла function day2hours($filename, $day, &$hours){ //Функция обработки файлов журналов $handle = @fopen($filename, 'r'); //Открываем файл $filename для чтения if ($handle) { //Если файл успешно открыт $rgx = '/^.+ \[(\d\d)\/...\/201\d:(\d\d):\d\d:\d\d \+0400\]/'; //Регулярное выражение для выборки дня месяца и часа из каждой записи в файле журнала while (($data = fgets($handle, 8000)) !== false) { //Считываем строку длиной до 8000 символов из файла журнала preg_match($rgx, $data, $res); //Проводим поиск по регулярному выражению $rgx в строке $data и выводим все совпадения в массив $res if ($res[1]==$day) $hours[$res[2]]++; //Если первый аргумент массива $res равен анализируемому дню $day, значит в массиве $hours прибавляем одно посещение к определённому часу $res[2] } if (!feof($handle)) { //Если предыдущий цикл закончился, а конец файла всё ещё не достигнут, значит произошла ошибка чтения из файла. echo "Error: unexpected fgets() fail\n"; //Выводим ошибку } fclose($handle); //Закрываем открытый файл }else exit("Файл не найден!\n"); //Выводим ошибку и выходим, если файл не удалось открыть } $date=$argv[1].'.count'; //Добавляем к имени первого файла расширение count и сохраняем в переменную $date $hours=implode("\r\n",$hours); //Конвертируем массив с почасовой статистикой $hours в текстовый вид (таблицу) file_put_contents($date,$hours); //Сохраняем таблицу с почасовой статистикой за сутки в файл $date |
Обратите внимание на формат файлов журналов nginx, приведённый ниже:
| 127.0.0.1 - frank [09/Aug/2014:06:25:02 +0400] "GET /apache_pb.gif HTTP/1.0" 200 2326 "http://www.example.com/start.html" "Mozilla/4.08 [en] (Win98; I ;Nav)" 31.184.219.88 - - [09/Aug/2014:06:25:03 +0400] "GET /groups/19541 HTTP/1.0" 200 4334 "-" "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_9_2) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/33.0.1750.152 Safari/537.36" 5.255.253.92 - - [09/Aug/2014:06:25:05 +0400] "GET /friends/18332 HTTP/1.1" 200 4057 "-" "Mozilla/5.0 (compatible; YandexBot/3.0; +http://yandex.com/bots)" |
Таким образом, выполнив следующие команды, мы получим семь файлов: 2014-06-20.count, 2014-06-21.count и т.д.
| cd /var/archive/ php activity-time.php 2014-06-20 2014-06-21 php activity-time.php 2014-06-21 2014-06-22 … php activity-time.php 2014-06-26 2014-06-27 |
Эти файлы будут содержать таблицы с почасовой статистикой посещений сайта за соответствующий день. По этим файлам можно построить графики, изображённые на рисунке 4.5.
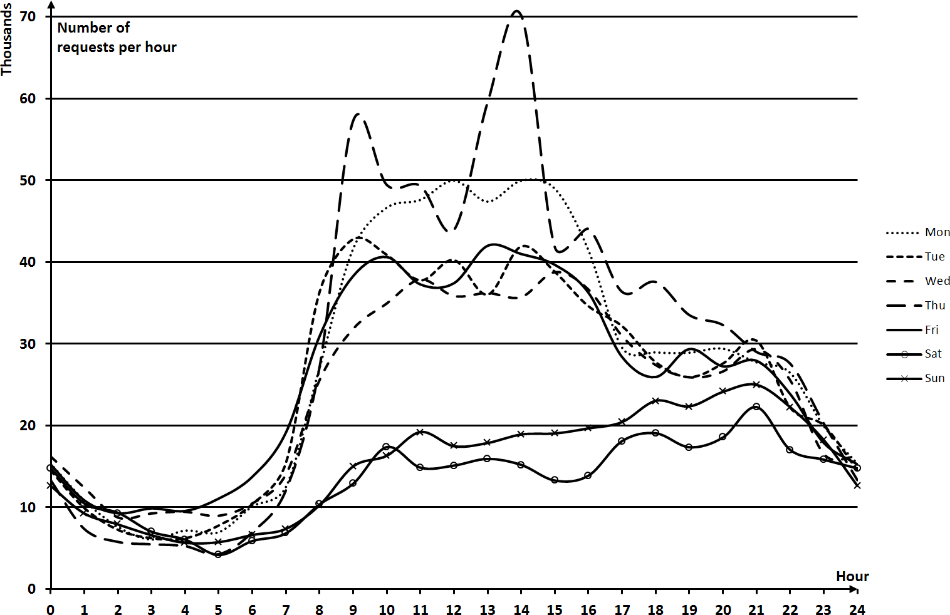
Рисунок 4.5 – Почасовая статистика посещений сайта за неделю
Как видно из рисунка, статистика сильно различается по дням недели, но при этом в любой день наименьшее число посещений находится в районе 4 часов утра. Именно это время мы возьмём для начала отсчёта новых суток и соответственно с него должен начинаться каждый файл журнала.
Следовательно, необходим скрипт, который преобразует имеющиеся в распоряжении файлы журналов веб-сервера к единой точке отсчёта времени – 4 часам утра. Алгоритм прост – проходим по всем записям файла журнала и распределяем эти записи в новые файлы в соответствии со временем каждой записи. Код скрипта с пояснениями приведён ниже:
| <?php // time-sync.php 2014-06-20 //Пример использования скрипта if ($argc!=2) exit("Неверное число параметров!\n"); //Проверяется передано ли нужное количество параметров $month=array('Jan' => '01', 'Feb' => '02', 'Mar' => '03', 'Apr' => '04', 'May' => '05', 'Jun' => '06', 'Jul' => '07', 'Aug' => '08', 'Sep' => '09', 'Oct' => 10, 'Nov' => 11, 'Dec' => 12); //Массив соответствия буквенного значения месяца числовому $hin = @fopen($argv[1], 'r'); //Открываем файл журнала if ($hin) { //Если файл открыт продолжаем обработку //Регулярное выражение для разбора даты записи в файле журнала $rgx = '/^.+ \[(\d\d)\/(...)\/(\d\d\d\d):(\d\d):\d\d:\d\d \+0400\]/'; while (($data = fgets($hin, 16384)) !== false) { //Считываем строку максимальной длиной 16384 символа из файла preg_match($rgx, $data, $res); //Проводим поиск по регулярному выражению $rgx в строке $data и выводим все совпадения в массив $res if (isset($day)) { //Если переменная $day задана if ($day!=$res[1] && $res[4]>=4) { //Создаём новый файл, если день текущей записи журнала не совпадает с днём первой записи и время больше или равно 4 часам ночи fclose($hout); //Закрываем ранее открытый для записи файл //Открываем (создаём новый, если не существует) файл в директории new, и задаём имя исходя из даты в записи журнала $hout=fopen('new/'.$res[3].'-'.$month[$res[2]].'-'.$res[1],'a'); $day=$res[1]; //Задаём день из записи журнала } }else{ //Если переменная $day не задана (это первая запись в файле) //Открываем (создаём новый, если не существует) файл в директории new, и задаём имя исходя из даты в записи журнала $hout=fopen('new/'.$res[3].'-'.$month[$res[2]].'-'.$res[1],'a'); $day=$res[1]; //Задаём день из записи журнала } fwrite($hout,$data); //Переносим запись журнала из файла $hin в файл $hout } if (!feof($hin)) { //Если предыдущий цикл закончился, а конец файла всё ещё не достигнут, значит произошла ошибка чтения из файла. echo "Error: unexpected fgets() fail\n"; //Выводим ошибку } if (isset($hout)) fclose($hout); //Закрываем файл $hout, если открыт fclose($hin); //Закрываем файл $hin }else exit("Файл не найден!\n"); //Если файл $hin открыть не удалось – выводим ошибку |
Теперь необходимо заранее создать директорию new, в которую будут помещаться приведённые к временному соответствию файлы журналов. Запускать скрипт необходимо строго последовательно в соответствии с датой для каждого файла журнала. Пример использования приведён ниже:
| cd /var/archive/ mkdir new php time-sync.php 2014-06-20 php time-sync.php 2014-06-21 php time-sync.php 2014-06-22 … |
Теперь сутками мы будем называть промежуток времени с 04:00:00 до 03:59:59. Файлы журналов, приведённые к этому промежутку, находятся в директории new.
Пришло время получить статистику по каждому из дней анализа. Следующие значения уже можно вычислить:
1. IP-адреса запросов к веб-серверу за сутки
| cd /var/archive/new/ # Переходим в каталог с файлами журналов cat 2014-06-20 | grep -o "^[0-9\.]*" > 2014-06-20.ip # IP-адреса запросов сохраняются в файл 2014-06-20.ip |
2. Уникальные IP-адреса за сутки
| cat 2014-06-20.ip | sort –u > 2014-06-20.sort # Сохраняет в файл 2014-06-20.sort уникальные IP-адреса клиентов за сутки |
3. Уникальные IP-адреса со времени начала анализа на каждые сутки
| cat 2014-06-19.all 2014-06-20.sort | sort –u > 2014-06-20.all # Добавляем к базе данных уникальные IP-адреса за 20 июля 2014 года отбрасывая повторения # Если файл 2014-06-19.all ещё не существует просто не указывайте его |
4. Новые (не встречавшиеся ранее) IP-адреса за сутки
| cat 2014-06-19.all 2014-06-20.all | sort | uniq –u > 2014-06-20.new # Вычисляем построчную разницу между текущим состоянием базы данных IP-адресов и прошлым |
Вышеописанные расчёты могут быть автоматизированы следующим образом:
| OLD='2014-05-31' # Дата прошлого состояния базы данных NEW='2014-06-01' # Дата, с которой начнётся анализ END='2014-07-01' # Дата окончания анализа while [ "$NEW" != "$END" ] do #echo 'old '$OLD' new '$NEW OLD=`date -d $OLD' 1 days' +%Y-%m-%d` # +1 день к $OLD NEW=`date -d $NEW' 1 days' +%Y-%m-%d` # +1 день к $NEW cat $NEW | grep -o "^[0-9\.]*" > $NEW.ip cat $NEW.ip | sort -u > $NEW.sort cat $OLD.all $NEW.sort | sort –u > $NEW.all cat $OLD.all $NEW.all | sort | uniq –u > $NEW.new #Выведем количество строк (IP-адресов) в получившихся файлах IP=`cat $NEW.ip | wc -l` SORT=`cat $NEW.sort | wc -l` ALL=`cat $NEW.all | wc -l` NEW=`cat $NEW.new | wc -l` echo $NEW $IP $SORT $ALL $NEW done |
Для запуска скрипта необходимо сохранить его в файл и выполнить:
| bash script.sh |
1. Количество обращений с каждого IP-адреса за сутки (таблицей)
| cat 2014-06-20.ip | sort | uniq –c > 2014-06-20.count |
2. Сколько суток задействован IP-адрес
| START='2014-06-01' # Дата, с которой начнётся анализ END='2014-07-01' # Дата окончания анализа (не включается) CUR=$START while [ "$CUR" != "$END" ] # Цикл от начальной даты до конечной do ALL=$ALL$CUR'.sort ' # В переменную $ALL через пробел записываем все файлы для анализа CUR=`date -d $CUR' 1 days' +%Y-%m-%d` # +1 день к $CUR done cat $ALL | sort | uniq –c > $START_$END.assigned |
Вышеописанные скрипты выводят таблицы, которые могут быть открыты табличным процессором (например, Microsoft Excel) и по ним построены графики для наглядного анализа.
4.4.Обработка статистики NetFlow
Ранее в главе был рассмотрен процесс настройки мониторинга сетевого трафика с использованием протокола NetFlow на базе операционной системы Debian GNU/Linux версии 7.6.0. Теперь каждую минуту в директории /var/cache/nfdump на вашем компьютере создаётся новый бинарный файл NetFlow с записями о сетевых потоках за прошлую минуту. При ротации файла запускается скрипт /usr/local/sbin/nfdump.pl, который должен производить следующие операции:
1. Преобразовывать бинарные файлы в текстовые таблицы, пригодные для статистической обработки.
2. Выводить статистику по количеству завершившихся потоков.
3. Обнаруживать атаку на веб-сервер по количеству запросов с одного IP-адреса.
4. Заносить IP-адрес атакующего в файл журнала.
5. Блокировать IP-адрес атакующего компьютера.
6. Разблокировать IP-адрес через определённое время.
Так как текстовые файлы nfdump представляют собой таблицы большого объёма, то для их разбора лучше всего подойдёт специально для этих целей созданный скриптовой язык Perl. Именно на нём будет выполнен обрабатывающий скрипт. Интерпретатор этого языка уже предустановлен в базовой версии Debian сервера.
Для разблокировки IP-адреса при блокировании он должен быть куда-то записан, а также сохранено время блокировки. Удобней всего проводить запись в базу данных. Кроме того, в БД можно сохранять ежеминутную статистику по количеству потоков. Для этого установим, если этого не было сделано раньше, базу данных MySQL:
| apt-get install mysql-server |
Дата добавления: 2017-03-29; просмотров: 628;