Алгоритмы. Предварительные сведения
При анализе алгоритма решения какой-либо задачи: нас в первую очередь будет интересовать его трудоемкость, под которой мы понимаем время выполнения соответствующей программы на ЭВМ. Ясно, что этот показатель существенно зависит от типа используемой ЭВМ.
Чтобы сделать наши выводы о трудоемкости алгоритмов в достаточной мере универсальными, будем считать, что все вычисления производятся на некой абстрактной вычислительной машине. Такая машина в состоянии выполнять арифметические операции, сравнения, пересылки и операции условной и безусловной передачи управления. Эти операции считаются элементарными. Каждая из элементарных операций выполняется за единицу времени и, следовательно, время работы алгоритма равно числу выполненных им элементарных операций.
Память абстрактной вычислительной машины состоит из неограниченного числа ячеек, имеющих адреса 1, 2, 3, ..., п, ... Ко всем ячейкам есть прямой доступ.
Остановимся особо на представлении чисел в памяти машины. При анализе алгоритмов наибольший интерес представляет зависимость времени работы алгоритма от числа вершин и (или) ребер графа. Выяснение этой зависимости удобнее проводить, если отвлечься от величины таких числовых параметров, как веса ребер взвешенного графа. Поэтому будем считать, что любое число, независимо от его величины, можно разместить в одной ячейке и каждая ячейка может содержать только одно число. Сделанное допущение будет оставаться в силе на протяжении этого и следующих пяти параграфов, в которых анализируется трудоемкость конкретных алгоритмов. В последнем параграфе этой главы мы несколько изменим модель вычислительной машины, приняв, в частности, иной способ представления чисел.
Алгоритмы можно описывать в терминах элементарных операций. Однако такая запись была бы перегружена непринципиальными деталями, заслоняющими основные идеи алгоритма.
Поэтому записывать алгоритмы будем в виде последовательности пунктов. Каждый пункт содержит один или несколько операторов (инструкций, правил), которые следует выполнить. Внутри пункта эти инструкции выполняются последовательно в том порядке, как они записаны. Если некоторый пункт не содержит указаний на переход к другому пункту, то после выполнения всех его инструкций следует перейти к следующему по порядку пункту. Единственное требование, предъявляемое к инструкциям, состоит в том, чтобы каждая из них легко выражалась через элементарные операции.
В записи алгоритма некоторые его фрагменты будут сопровождаться комментариями. Комментируемый фрагмент может быть отдельным оператором или пунктом, а также группой последовательно расположенных операторов либо пунктов. Комментарии будем писать в квадратных скобках и помещать в начале или в конце комментируемого фрагмента.
Хотя мы и условились при описании алгоритмов не ограничивать себя каким-либо набором стандартных операторов, все же два таких оператора будут использоваться постоянно. Во-первых — это оператор присваивания а: = В. В результате его выполнения переменная а получает новое значение, равное В. Во-вторых — оператор-«конец», выполнение которого означает прекращение вычислений.
Рассмотрим теперь представление информации в памяти машины. Всякую конечную последовательность элементов произвольной природы будем называть спискомг а число элементов списка — его длиной. Элементами могут быть числа, буквы алфавита, векторы, матрицы и-т. п. В той ситуации, когда каждый элемент списка S помещается в одной ячейке (например, является числом),этот список будем размещать в п последовательных ячейках памяти, где п — длина списка. Через S(k) будем обозначать k-й элемент списка S. Аналогично список S длины п будем размещать в nd последовательных ячейках, если для размещения каждого его элемента достаточно d ячеек. Такое представление списка обычно называется последовательным, и ниже используется только-это представление.
Пусть А = \\Aij\\ — матрица порядка п и А` = (A11, A12, ..., A1n, A21, A22, ..., A2n, ..., An1, An2 ,..., Апп)—список ее элементов «по строкам». Принятый нами принцип «одно число — одна ячейка» означает, что матрица порядка п занимает п2 ячеек памяти.
Рассмотрим теперь представление графа G в памяти машины. Пусть VG = (v1, v2, ..., vn). Будем пользоваться тремя способами представления.
Первый — задание графа матрицей смежности. Если граф G взвешенный и w(x, у) обозначает вес ребра ху, то вместо матрицы смежности используется матрица весов W(G)=W. У этой матрицы Wjj= w(vi vj), если vivj € EG. Если же vivj ¢ EG, то полагаем Wij = 0 или Wij = ∞ в зависимости от задачи, которую предстоит решить. Из сказанного выше о представлении матрицы в машине следует, что такой способ задания графа требует \G\2ячеек памяти. В предыдущих главах веса предполагались неотрицательными. Теперь снимем это ограничение и будем считать, что весами ребер могут быть любые вещественные числа.
Второй способ — задание графа списком ребер E = (е1, е2, ..., ет), где т = \EG\, ei € EG. Поскольку ребро графа можно хранить, используя две ячейки (по одной на каждую концевую вершину), то для хранения всего списка E достаточно 2т ячеек. Если граф взвешенный, то под каждый элемент списка Е можно отвести три ячейки — две для ребра и одну для его веса, т. е. всего потребуется Зт ячеек.
И, наконец, последний способ, который будет использоваться,— представление графа списками смежности. При таком способе каждой вершине vi ставится в соответствие список Nvi вершин, смежных с vi. Под этот список достаточно отвести deg vi + 1 ячеек — по одной на каждый элемент и одну ячейку для обозначения конца списка. Кроме того, формируется список N = (N1, N2, ..., Nn), где Ni — номер ячейки, в которой хранится первый элемент списка Nvi. Следовательно, такой способ представления графа требует ∑(deg v + 1) + п =
v € vg
= 2m + 2п ячеек памяти. Если граф G взвешенный, то для каждой вершины vi, списка Nvi отводится дополнительно одна ячейка, содержащая число w(vi ,vj).
Хотя представление графа списком ребер является наиболее экономным «по памяти», оно имеет существенный недостаток. Чтобы определить, содержит ли граф данное ребро, надо просматривать поочередно элементы этого списка, а это может потребовать около 2т элементарных операций. Если же граф задан списками смежности, вычислительные затраты составят не более п +• 1 таких операций. Представление графа матрицей смежности, требующее наибольших затрат памяти, обеспечивает, как принято говорить, «прямой доступ» к ребрам графа. Узнать, содержит ли граф ребро vivj можно, вычислив адрес k= in+j и сравнив М (k) с нулем, где М — массив, в котором построчно размещена матрица смежности графа. Сказанное с очевидными изменениями переносится на случай взвешенных и ориентированных графов.
Выбор того или иного задания графа зависит от конкретной задачи, которую предстоит решать.
Во всех рассматриваемых в этой главе задачах главной частью исходной информации служит граф. Кроме этого, исходные данные могут включить номера одной или нескольких выделенных вершин. Если, например, задача состоит в отыскании цепи, соединяющей две заданные вершины графа, то помимо графа необходимо задать ломера этих двух вершин.
После того как всем исходным данным задачи присвоены конкретныезначения и они размещены в памяти ЭВМ, будем называть их входом задачи. Размером (или длиною) входа считается число ячеек, занятых входом. При анализе алгоритма решения любой задачи нас в первую очередь будет интересовать зависимость времени его работы от размера задачи, т. е. от размера входа. Однако, как правило, это время зависит не только от размера входа, но и от других параметров задачи, т. е. время работы алгоритма на входах одинаковой длины может быть не одинаковым. Поясним сказанное на простейшем примере. Пусть элементами списка S = (s1, s2, ..., sm) являются натуральные числа и требуется определить, содержит ли S число, кратное трем. Очевидный алгоритм решения этой простой задачи состоит в следующем: проверяем поочередно делимость элементов списка S на 3 до тех пор, пока не встретится число sp, кратное трем, или же не будут проверены все элементы S. Время выполнения р таких проверок равно t = 2p (p делений и р изменений адреса). Следовательно, при неизменной длине входа т время работы алгоритма будет изменяться в пределах 2 ≤ t ≤ 2т в зависимости от расположения подходящего элемента sp в списке S. Наихудшим, очевидно, будет случай, когда S не содержит чисел, кратных трем, либо когда sm — единственное такое число. Один из основных подходов к определению понятия «трудоемкость алгоритма» ориентируется именно на такого рода наихудший случай.
Определим трудоемкость (или сложность) алгоритма решения данной задачи как функцию f, ставящую в соответствие каждому натуральному числу п время работы f(n) алгоритма в худшем случае на входах длины п. Иначе говоря, f(n)—максимальное время работы алгоритма по всем входам данной задачи длины п. Анализ эффективности каждого из представленных в последующих параграфах алгоритмов заключается в выяснении вопроса: как быстро растет функция f(n) с ростом п? При ответе на этот вопрос обычно используют O-символику.
Будем говорить, что неотрицательная функция f(n) не превосходит по порядку функцию g(n), если существует такая константа с, что f(n)< cg(n) для всех п ≥ 0; при этом будем писать f(n) = O(g(n)). Часто встречающемуся далее выражению «трудоемкость (сложность) алгоритма есть (равна, составляет) O(g(n))» придается именно этот смысл. В частности, трудоемкость 0(1) означает, что время работы соответствующего алгоритма не зависит от длины входа. Иногда вместо «трудоемкость алгоритма есть O(g(n))» будем говорить «алгоритм решает задачу за время O(g(n))».
Алгоритм с трудоемкостью О (п), где п — длина входа, называют линейным. Линейный алгоритм ограниченное (константой) число раз просматривает входную информацию и для подавляющего большинства «естественных» задач является неулучшаемым (по порядку) в смысле трудоемкости. Поэтому отыскание линейного алгоритма для некоторой задачи часто является своего рода «последней» точкой» в ее алгоритмическом решении.
Алгоритм, сложность которого равна О(пс), где с — константа, называется полиномиальным. Особая роль полиномиальных алгоритмов выяснится в § 78. Здесь заметим, что все задачи, считающиеся трудными для алгоритмического решения, не имеют в настоящее время полиномиальных алгоритмов. Более того, понятие «полиномиальный алгоритм» является сейчас наиболее распространенной формализацией интуитивного представления об эффективном алгоритме. Эта формализация, как и любая другая, не свободна от недостатков. Так, например, едва ли кто решится назвать эффективным алгоритм, время работы которого на входе длины п составляет n100. Тем не менее отмеченный недостаток не столь серьезен, как это может показаться на первый взгляд. На практике дело обстоит таким образом, что появление полиномиального алгоритма решения какой-либо задачи приводит в конце концов к алгоритму, трудоемкость которого оценивается сверху полиномом небольшой степени. В большинстве случаев эта степень не превосходит трех и оценка, как правило, имеет один из следующих видов: О(п3), О(п2), О(п√n), O(nlogn), О(п).
Представленные в последующих параграфах алгоритмы используют две важные структуры данных. Это — списки, в которых удаление элементов и включение новых элементов производится специальным образом.
Список S назовем стеком, если удаление и добавление элементов производится с одного конца. Выполнение этих операций осуществляется с помощью переменной t — адреса (указателя) первой ячейки, занятой последним элементом списка S. Если каждый элемент занимает d ячеек, то для удаления элемента из стека достаточно «передвинуть указатель», т. е. выполнить одну элементарную операцию t := t — d. Включение какого-либо элемента а в стек S — это выполнение двух элементарных операций: t:— t + d, S(t):=a. Стек S пуст, если t<l, где l — адрес первой ячейки S.
Пусть, например, каждый элемент стека S = (s1, s2, s3 , s4 , s5) занимает одну ячейку. Рассмотрим последовательность операций (*, *, s7, s8, *, s9), где «*» означает удаление элемента из S, a «si»—добавление элемента si к S. Тогда S изменяется следующим образом: (s1, s2, s3 , s4), t = 4; (s1, s2, s3 ), t = 3; (s1, s2, s3 , s7), t = 4; (s1, s2, s3 , s7, s8), t = 5; (s1, s2, s3 , s7), t = 4; (s1, s2, s3 , s7, s9), t = 5.
Список Q называется очередью, если все удаления элементов из этого списка производятся с одного конца Q, а добавления — с другого. Эти операции выполняются с помощью двух указателей l и t. Переменная t имеет тот же смысл, что и в предыдущем случае, а переменная l — это адрес первой ячейки очереди Q. Удаление элемента заключается в выполнении операции l:=l + d, а добавление производится точно так же, как и в случае стека. Пусть, например, Q=(q1 , q2 , q3, q4, q5) и последовательность производимых над Q операций имеет вид (*, q6 , *, * , q7, *). Тогда результаты выполнения этих операций выглядят так: (q2 , q3, q4, q5), l = 2, t = 5; ( q2 , q3, q4, q5, q6 ) l = 2, t = 6; (q3, q4, q5, q6), l = 3, t = 6; (q4, q5, q6), l = 4, t =6; (q4 , q5 , q6,, q7), l = 4, t = 7; (q5 , q6 , q7), l = 5, t = 7.
Описывая алгоритмы, мы, как правило, не указываем в явном виде механизм изменения стека или очереди. Вместо этого просто пишем «занести х в стек S (в очередь Q или «исключить х из стека S (из очереди Q)». Очевидно, что каждая из перечисленных операций выполняется за время O(1).
Будем считать, наконец, что вершины графа G, к которому применяется алгоритм, занумерованы числами 1, 2, ..., |G|. Это — имена вершин, и в процессе работы алгоритма они не меняются, хотя при этом вершинам могут присваиваться и другие, дополнительные номера (метки).
Поиск в глубину
В этом параграфе рассматривается один из методов обхода всех вершин и ребер графа. Этот метод, именуемый поиском в глубину (сокращенно ПГ), послужил основой для разработки ряда быстрых алгоритмов на графах. Один из таких алгоритмов — алгоритм выделения двусвязных компонент графа — приводится в § 74. Дадим вначале некоторые определения. Ориентирований граф D — (V, A) назовем ориентированным деревом корнем r € V,если каждая его вершина достижима из и основание графа D — граф Db — является деревом. В тех случаях, когда недоразумение исключено, ориентированное дерево с корнем r будем называть просто деревом.
Пусть G — неориентированный связный граф, В провесе поиска в глубину вершинам графа G присваиваютcя номера (ПГ-номера), а его ребра помечаются. В начале ребра не помечены, вершины не имеют ПГ-номеров. Начинаем с произвольной вершины v0. Присваиваем ей ПГ-номер ПГ(v0)=1 и выбираем произвольное ребро v0w Ребро v0w помечается как «прямое», а вершина w включает (из v0) ПГ-номер ПГ(w)=2. После этого переводим в вершину w. Пусть в результате выполнения нескольких шагов этого процесса пришли в вершину х, и Пусть k — последний присвоенный ПГ-номер. Далее действуем в зависимости от ситуации следующим образом.
1. Имеется непомеченное ребро ху. Если у вершины уже есть ПГ-номер, то ребро ху помечаем как «обратное» продолжаем поиск непомеченного ребра, инцидентного вершине х. Если же вершина у ПГ-номера не имеет, то полагаем ПГ(y) = k + 1, ребро ху помечаем как «прямое» : переходим в вершину у. Вершина у считается получившей свой ПГ-номер из вершины х. На следующем шаге будем просматривать ребра, инцидентные вершине у.
2. Все ребра, инцидентные вершине х, помечены. В этом случае возвращаемся в вершину, из которой х получила свой ПГ-номер.
Процесс закончится, когда все ребра будут помечены : произойдет возвращение в вершину v0.
Описанный процесс можно реализовать так, чтобы ремя работы соответствующего алгоритма составляло (/EG/ + /G/).
Такой алгоритм (алгоритм A1) мы сейчас рассмотрим. Пусть граф G задан списками смежности, т. е. Nv — список вершин, инцидентных вершине v, и v0 — исходная вершина, с которой начинается поиск. В процессе работы алгоритма каждая вершина графа ровно один раз включается в список Q и исключается из него. Вершина включается в этот список сразу после получения ПГ-номера, исключается, как только произойдет возвращение из этой вершины. Включение и исключение вершин производятся всегда с конца списка, т. е. Q — стек. Результат работы алгоритма — четыре списка ПГ, F, Т и В: ПГ(v)— ПГ-номер вершины v; F(v)—имявершины, из которой вершина v получила свой ПГ-номер; Т и В— соответственно списки ориентированных «прямых» и «обратных» ребер графа G. Эти ребра получают ориентацию в процессе работы алгоритма a1. Именно, если ребро ху помечается из вершины х как «прямое», то в Т заносится дуга (х, у), а если — как «обратное», то эта дуга заносится в В.
 |
Алгоритм A1 поиска в глубину в неориентированном связном графе.
1 ПГ(v):=1, Q(1):= v0, F(vo):=0, T:=¢, B:=¢, k:=1,р:=1 [k — последний присвоенный ПГ-номер, р — указатель конца стека Q, т. е. Q(p)— имя последней вершины стека Q].
2. v := Q(p) [v — исследуемая вершина].
3. Просматривая список Nv, найти такую вершину w,что ребро vw не помечено, и перейти к п. 4. Если таких вершин нет, то перейти к п. 5.
4. Если вершина w имеет ПГ-номер, то пометить ребро vw как «обратное» и занести дугу (v, w) в список В. Перейти к п. 3 и продолжить просмотр списка Nv. Иначе k:=k + 1, ПГ(w):=k, F(w):=v, ребро vw пометить как «прямое» и дугу (v, w) занести в список T, р:=р+ 1, Q(p):=w [вершина w получила ПГ-номер и занесена встек Q]. Перейти к п. 2.
5. р := р — 1 [вершина v вычеркнута из Q]. Если р = 0, то конец. Иначе перейти к п. 2.
Корректность алгоритма очевидна. Оценим его трудоемкость. Каждое включение и исключение вершины из стека Q выполняется за время O(1). Поэтому для всей работы, связанной с изменением стека Q, достаточно времени O (|G|). Каждое выполнение п. 4 требует O (1) времени, и для каждой вершины v € VG этот пункт выполняется deg v раз. Поэтому затраты на его выполнение в
целом составят O (∑deg v) = О (|EG|). Суммарное время выполнения п. 3 также составит O(|EG|), если позаботиться о том, чтобы каждая вершина списка Nv просматривалась только один раз при всех выполнениях данного пункта. Этого легко добиться, если, например, ввести такую новую функцию (массив) t, что t(v)—номер первой непросмотренной вершины в списке Nv. Тогда следующий просмотр п. 3 следует начинать с вершины z = Nv(t(v)).
Итак, трудоемкость алгоритма A1 составляет O(|EG|+|G|). Ясно, что это время является наилучшим возможным по порядку, так как каждая вершина и каждое ребро графа G должны быть просмотрены хотя бы один раз.
Легко видеть, что требуемый для реализации алгоритма A1 объем памяти также составляет O(|EG|+|G|).
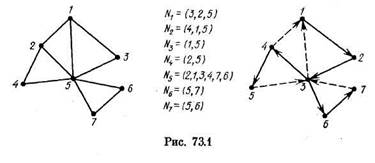
На рис. 73.1 слева изображены граф G и списки смежности, которыми он задан. Справа представлены результаты применения к этому графу поиска в глубину из
вершины v0 = 1. «Прямые» ребра проведены сплошными линиями, а «обратные» пунктирными. Каждой вершине приписан ее ПГ-номер.
Из способа построения множеств Т и В непосредственно вытекают следующие утверждения.
Утверждение 73.1. Дуги множества Т образуют ориентированное остовное дерево с корнем в вершине v0. Это остовное дерево часто называют остовным глубинным деревом (ОГД). Обозначать
его будем также через Т.
Утверждение 73.2. Если ориентированное ребро (х, у) принадлежит В, то ПГ(х)>ПГ(у), т. е. «обратные» ребра всегда ведут к ранее пройденным вершинам.
Поиск в глубину используется в качестве составной тасти во многих алгоритмах. Отметим одну задачу, решение которой можно получить с помощью алгоритма A1 фазу, почти без дополнительных вычислительных затрат. Это — задача выделения связных компонент графа. Чтобы решить ее за время O(|EG|+|G|), достаточно один раз просмотреть список вершин графа, выполняя следующие действия. Если просматриваемая вершина vl имеет ПГ-номер, то перейти к следующей. Иначе — положить v0 = vl ПГ(v0) = k + 1, где k — последний присвоенный ПГ-номер, и применить поиск в глубину.После его окончания (т. е. выделения компоненты, содержащей vl) продолжить просмотр списка, перейти к вершине vl+1. Различать вершины разных компонент можно, например, по их ПГ-номерам, если для каждой компоненты запомнить последний ПГ-номер.
Дата добавления: 2019-07-26; просмотров: 706;