Становление и эволюция цифровой вычислительной техники 4 страница
Отметим, что в последних микропроцессорах фирмы Intel и AMD широко используются идеи, свойственные RISC-архитектуре, так что многие различия между CISC и RISC постепенно стираются.
Помимо CISC- и RISC-архитектур в общей классификации был упомянут еще один тип АСК — архитектура с командными словами сверхбольшой длины (VLIW). Концепция VLIW базируется на RISC-архитектуре, где несколько простых RISC-команд объединяются в одну сверхдлинную команду и выполняются параллельно. В плане АСК архитектура VLIW сравнительно мало отличается от RISC. Появился лишь дополнительный уровень параллелизма вычислений, в силу чего архитектуру VLIW логичнее адресовать не к вычислительным машинам, а к вычислительным системам.
Таблица 2.1. Сравнительная оценка CISC-, RISC- и VLIW-архитектур
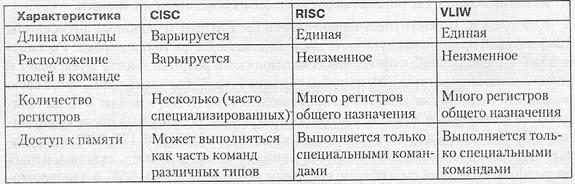
Таблица 2.1 позволяет оцепить наиболее существенные различия в архитектурах типа CISC, RISC и VLIW.
Классификация по месту хранения операндов
Количество команд и их сложность, безусловно, являются важнейшими факторами, однако не меньшую роль при выборе АСК играет ответ на вопрос о том, где могут храниться операнды и каким образом к ним осуществляется доступ. С этих позиций различают следующие виды архитектур системы команд:
· стековую;
· аккумуляторную;
· регистровую;
· с выделенным доступом к памяти.
Выбор той или иной архитектуры влияет на принципиальные моменты: сколько адресов будет содержать адресная часть команд, какова будет длина этих адресов, насколько просто будет происходить доступ к операндам и какой, в конечном итоге, будет общая длина команд.
Стековая архитектура
Стеком называется память, по своей структурной организации отличная от основной памяти ВМ. Принципы построения стековой памяти детально рассматриваются позже, здесь же выделим только те аспекты, которые требуются для пояснения особенностей АСК на базе стека. Стек образует множество логически взаимосвязанных ячеек (рис. 2.4), взаимодействующих по принципу «последним вошел, первым вышел» (LIFO, Last In First Out).
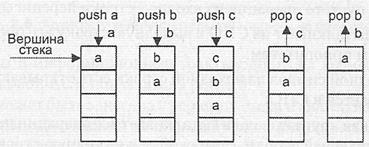
Рис. 2.4. Принцип действия стековой памяти
Верхнюю ячейку называют вершиной стека. Для работы со стеком предусмотрены две операции: push (проталкивание данных в стек) и pop.(выталкивание данных из стека). Запись возможна только в верхнюю ячейку стека, при этом вся хранящаяся в стеке информация предварительно проталкивается на одну позицию вниз. Чтение допустимо также только из вершины стека. Извлеченная информация удаляется из стека, а оставшееся его содержимое продвигается вверх. В вычислительных машинах, где реализована АСК на базе стека (их обычно называют стековыми), операнды перед обработкой помещаются в две верхних ячейки стековой памяти. Результат операции заносится в стек. Принцип действия стековой машины поясним на примере вычисления выражения а = а + b + а×с.
При описании вычислений с использованием стека обычно используется иная форма записи математических выражений, известная как обратная польская запись (обратная польская нотация), которую предложил польский математик Я. Лукашевич. Особенность ее в том, что в выражении отсутствуют скобки, а знак операции располагается не между операндами, а следует за ними (постфиксная форма). Последовательность операций определяется их приоритетами (табл. 2.2).
Таблица 2.2. Приоритеты операций в обратной польской нотации
| Операция | Символ операции | Приоритет |
| Открывающаяся скобка | ( | |
| Закрывающаяся скобка | ) | |
| Сложение | вычитание | +| – | |
| Умножение | деление | *| / | |
| Возведение в степень | ** |
При преобразовании традиционной записи выражения в постфиксную используется логическая структура, аналогичная стеку, которую, чтобы не путать ее со стеком вычислительной машины, назовем стеком последовательности операций (СПО). Формирование выходной строки с выражением в обратной польской нотации осуществляется в соответствии со следующим алгоритмом:
1. Исходная строка с выражением просматривается слева направо.
2. Операнды переписываются в выходную строку.
3. Знаки операций заносятся в СПО по следующим правилам:
□ если СПО пуст, то операция из входной строки переписывается в СПО;
□ операция выталкивает из СПО в выходную строку все операции с большим или равным приоритетом;
□ если очередной символ из исходной строки есть открывающая скобка, то он проталкивается в СПО;
□ закрывающая круглая скобка выталкивает все операции из СПО до ближайшей открывающей скобки, сами скобки в выходную строку не переписываются, а уничтожают друг друга.
Процесс получения обратной польской записи для правой части выражения а = а + b + а×с представлен в табл. 2.3.
Таблица 2.3. Формирование обратной польской записи для выражения а = а + b + а×с
| Просматриваемый символ | |||||||||
| Входная строка | а | + | b | + | а | × | с | ||
| Состояние стека последовательности операций | + | + | ×+ | + | |||||
| Выходная строка | а | ь | + | а | с | × | + |
Таким образом, рассмотренное выше выражение в польской записи имеет вид: а = ab+ac×+. Данная форма записи однозначно определяет порядок загрузки операндов и операций в стек (рис. 2.5).
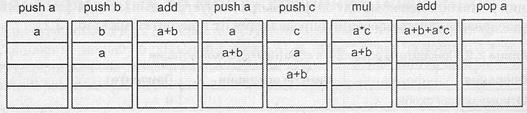
Рис. 2.5. Последовательность вычисления выражения а = ab+ac×+ на вычислительной машине
со стековой архитектурой
Основные узлы и информационные тракты одного из возможных вариантов ЗМ на основе стековой АСК показаны на рис. 2.6.
Информация может быть занесена в вершину стека из памяти или из АЛУ. Для записи в стек содержимого ячейки памяти с адресом x выполняется команда push х, по которой информация считывается из ячейки памяти, заносится в регистр данных, а затем проталкивается в стек. Результат операции из АЛУ заносится в вершину стека автоматически.
Сохранение содержимого вершины стека в ячейке памяти с адресом х производится командой pop х. По этой команде содержимое верхней ячейки стека подается на шину, с которой и производится запись в ячейку x, после чего вся находящаяся в стеке информация проталкивается на одну позицию вверх.
Для выполнения арифметической или логической операции на вход АЛУ подается информация, считанная из двух верхних ячеек стека (при этом содержимое стека продвигается на две позиции вверх, то есть операнды из стека удаляются). Результат операции заталкивается в вершину стека. Возможен вариант, когда результат сразу же переписывается в память с помощью автоматически выполняемой операции pop х.
Верхние ячейки стековой памяти, где хранятся операнды и куда заносится результат операции, как правило, делаются более быстродействующими и размещаются в процессоре, в то время как остальная часть стека может располагаться в основной памяти и частично даже на магнитном диске.
К достоинствам АСК на базе стека следует отнести возможность сокращения адресной части команд, поскольку все операции производятся через вершину стека, то есть адреса операндов и результата в командах арифметической и логической обработки информации указывать не нужно. Код программы получается компактным. Достаточно просто реализуется декодирование команд.
С другой стороны, стековая АСК по определению не предполагает произвольного доступа к памяти, из-за чего компилятору трудно создать эффективный программный код, хотя создание самих компиляторов упрощается. Кроме того, стек становится «узким местом» ВМ в плане повышения производительности. В силу упомянутых причин, данный вид АСК долгое время считался неперспективным и встречался, главным образом, в вычислительных машинах 1960-х годов, например в ВМ фирмы Burroughs (В5500, В6500) или фирмы Hewlett-Packard (НР2116В, HP 3000/70).
Последние события в области вычислительной техники свидетельствуют о возрождении интереса к стековой архитектуре ВМ. Связано это с популярностью языка Java и расширением сферы применения языка Forth, семантике которых наиболее близка именно стековая архитектура. Среди современных ВМ со стековой АСК можно упомянуть машины JEM 1 и JEM 2 компании aJile Systems и Clip фирмы Imsys. Особо следует отметить стековую машину IGNITE компании Patriot Scienist, которую ее авторы считают представителем нового вида АСК — архитектурой с безоперандным набором команд. Для обозначения таких ВМ они предлагают аббревиатуру ROSC (Removed Operand Set Computer). ROSC-архитектура заложена и в некоторые российские проекты, например разработки ИТФ «Технофорт». Строго говоря, по своей сути ROSC мало отличается от традиционной архитектуры на базе стека, и выделение ее в отдельный вид представляется не вполне обоснованным.
Аккумуляторная архитектура
Архитектура на базе аккумулятора исторически возникла одной из первых. В ней для хранения одного из операндов арифметической или логической операции в процессоре имеется выделенный регистр — аккумулятор. В этот же регистр заносится и результат операции. Поскольку адрес одного из операндов предопределен, в командах обработки достаточно явно указать местоположение только второго операнда. Изначально оба операнда хранятся в основной памяти, и до выполнения операции один из них нужно загрузить в аккумулятор. После выполнения команды обработки результат находится в аккумуляторе и, если он не является операндом для последующей команды, его требуется сохранить в ячейке памяти.
Типичная архитектура ВМ на базе аккумулятора показана на рис. 2.7.
Для загрузки в аккумулятор содержимого ячейки х предусмотрена команда загрузки load х. По этой команде информация считывается из ячейки памяти х, выход памяти подключается к входам аккумулятора и происходит занесение считанных данных в аккумулятор.
Запись содержимого аккумулятора в ячейку х осуществляется командой сохранения store х, при выполнении которой выходы аккумулятора подключаются к шине, после чего информация с шины записывается в память.
Для выполнения операции в АЛУ производится считывание одного из операндов из памяти в регистр данных. Второй операнд находится в аккумуляторе. Выходы регистра данных и аккумулятора подключаются к соответствующим входам АЛУ. По окончании предписанной операции результат с выхода АЛУ заносится в аккумулятор.
Достоинствами аккумуляторной АСК можно считать короткие команды и простоту декодирования команд. Однако наличие всего одного регистра порождает многократные обращения к основной памяти
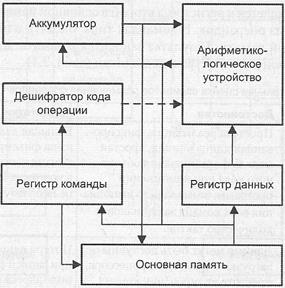
Рис. 2.7. Архитектура вычислительной машины на базе аккумулятора
АСК на базе аккумулятора была популярна в ранних ВМ, таких, например, как IBM 7090, DEC PDP-8, MOS 6502.
Регистровая архитектура
В машинах данного типа процессор включает в себя массив регистров (регистровый файл), известных как регистры общего назначения (РОН). Эти регистры, в каком-то смысле, можно рассматривать как явно управляемый кэш для хранения недавно использовавшихся данных.
Размер регистров обычно фиксирован и совпадает с размером машинного слова. К любому регистру можно обратиться, указав его номер. Количество РОИ в архитектурах типа CISC обычно невелико (от 8 до 32), и для представления номера конкретного регистра необходимо не более пяти разрядов, благодаря чему в адресной части команд обработки допустимо одновременно указать номера двух, а зачастую и трех регистров (двух регистров операндов и регистра результата). RISC-архитектура предполагает использование существенно большего числа РОН (до нескольких сотен), однако типичная для таких ВМ длина команды (обычно 32 разряда) позволяет определить в команде до трех регистров.
Регистровая архитектура допускает расположение операндов в одной из двух запоминающих сред: основной памяти или регистрах. С учетом возможного размещения операндов в рамках регистровых АСК выделяют три подвида команд обработки:
· регистр-регистр;
· регистр-память;
· память-память.
В варианте «регистр-регистр» операнды могут находиться только в регистрах. В них же засылается и результат. Подтип «регистр-память» предполагает, что один
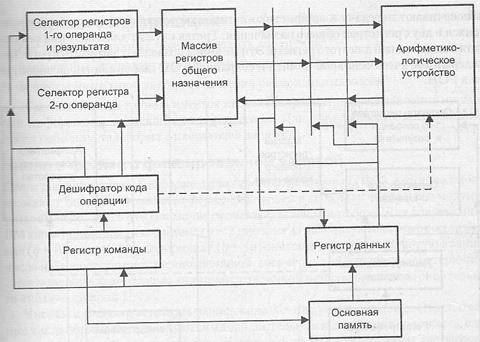
Рис. 2.8. Архитектура вычислительной машины на базе регистров общего назначения
К достоинствам регистровых АСК следует отнести: компактность получаемого кода, высокую скорость вычислений за счет замены обращений к основной памяти на обращения к быстрым регистрам. С другой стороны, данная архитектура требует более длинных инструкций по сравнению с аккумуляторной архитектурой. Примерами машин на базе РОН могут служить CDC 6600, IBM 360/370, PDP-11, все современные персональные компьютеры. Правомочно утверждать, что в наши дни этот вид архитектуры системы команд является преобладающим.
Архитектура с выделенным доступом к памяти
В архитектуре с выделенным доступом к памяти обращение к основной памяти возможно только с помощью двух специальных команд: load и store. В английской транскрипции данную архитектуру называют Load/Store architecture. Команда load (загрузка) обеспечивает считывание значения из основной памяти и занесение его в регистр процессора (в команде обычно указывается адрес ячейки памяти и номер регистра). Пересылка информации в противоположном направлении производится командой store (сохранение). Операнды во всех командах обработки информации могут находиться только в регистрах процессора (чаще всего в регистрах общего назначения). Результат операции также заносится в регистр. В архитектуре отсутствуют команды обработки, допускающие прямое обращение к основной памяти. Допускается наличие в АСК ограниченного числа команд, где операнд является частью кода команды.
Состав и информационные тракты ВМ с выделенным доступом к памяти показаны на рис. 2.9. Две из трех шин, расположенных между массивом РОН и АЛУ, обеспечивают передачу в арифметико-логическое устройство операндов, хранящихся в двух регистрах общего назначения. Третья служит для занесения результата в выделенный для этого регистр. Эти же шины позволяют загрузить в регистры содержимое ячеек основной памяти и сохранить в ОП информацию, находящуюся в РОН.
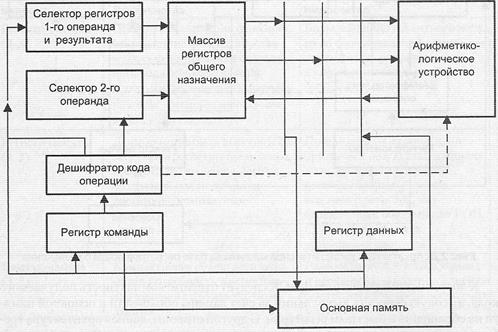
Рис. 2.9. Архитектура вычислительной машины с выделенным доступом к памяти
АСК с выделенным доступом к памяти характерна для всех вычислительных машин с RISC-архитектурой. Команды в таких ВМ, как правило, имеют длину 32 бита и трехадресный формат. В качестве примеров вычислительных машин с выделенным доступом к памяти можно отметить HP PA-RISC, IBM RS/6000, Sun SPARC, MIPS R4000, DEC Alpha и т. д. К достоинствам АСК следует отнести простоту декодирования и исполнения команды.
Типы и форматы операндов
Машинные команды оперируют данными, которые в этом случае принято называть операндами. К наиболее общим (базовым) типам операндов можно отнести: адреса, числа, символы и логические данные. Помимо них ВМ обеспечивает обработку и более сложных информационных единиц: графических изображений, аудио-, видео- и анимационной информации. Такая информация является производной от базовых типов данных и хранится в виде файлов на внешних запоминающих устройствах. Для каждого типа данных в ВМ предусмотрены определенные форматы.
Числовая информация
Среди цифровых данных можно выделить две группы:
· целые типы, используемые для представления целых чисел;
· вещественные типы для представления рациональных чисел.
В рамках первой группы имеется несколько форматов представления численной информации, зависящих от ее характера. Для представления вещественных чисел используется форма с плавающей запятой.
Числа в форме с фиксированной запятой
Представление числа X в форме с фиксированной запятой (ФЗ), которую иногда называют также естественной формой, включает в себя знак числа и его модуль в q-ичном коде. Здесь q — основание системы счисления или база. Для современных ВМ характерна двоичная система (q = 2), но иногда используются также восьмеричная (q = 8) или шестнадцатеричная (q = 16) системы счисления. Запятую в записи числа называют соответственно двоичной, восьмеричной или шестнадцатеричной. Знак положительного числа кодируется двоичной цифрой 0, а знак отрицательного числа — цифрой 1.
Числам с ФЗ соответствует запись вида Х = ±an-1...a1a0a-1a-2...a-r Отрицательные числа обычно представляются в дополнительном коде. Разряд кода числа, в котором размещается знак, называется знаковым разрядом, кода. Разряды, где располагаются значащие цифры числа, называются цифровыми разрядами кода. Знаковый разряд размещается левее старшего цифрового разряда. Положение запятой одинаково для всех чисел и в процессе решения задач не меняется. Хотя запятая и фиксируется, в коде числа она никак не выделяется, а только подразумевается. В общем случае разрядная сетка ВМ для размещения чисел в форме с ФЗ имеет вид, представленный на рис. 2.10, где п разрядов используются для записи целой части числа и r разрядов — для дробной части.
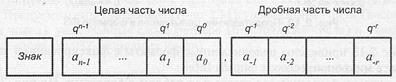
Рис. 2.10. Формат представления чисел с фиксированной запятой
При заданных значениях п и r диапазон изменения модулей чисел, коды которых могут быть представлены в данной разрядной сетке, определяется соотношением
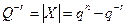
Если число является смешанным (содержит целую и дробную части), оно обрабатываются как целое, хотя и не является таковым (в этом случае применяют термин масштабируемое целое). Обработка смешанных чисел в ВМ встречается крайне редко. Как правило, используются ВМ с дробной (п = 0) либо целочисленной (r = 0) арифметикой.
При фиксации запятой перед старшим цифровым разрядом (рис. 2.11) могут быть представлены только правильные дроби. Для ненулевых чисел возможны два варианта представления (нулевому значению соответствуют нули во всех разрядах): знаковое и беззнаковое. Фиксация запятой перед старшим разрядом встречалась в ряде машин второго поколения, но в настоящее время практически отжила свое.
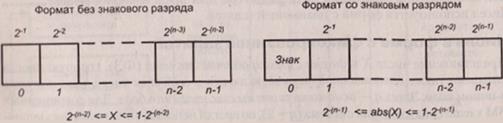
Рис. 2.11. Представление дробных чисел в формате ФЗ
При фиксации запятой после младшего разряда представимы лишь целые числа. Это наиболее распространенный способ, поэтому в дальнейшем понятие ФЗ будет связываться исключительно с целыми числами, а операции с числами в форме ФЗ будут характеризоваться как целочисленные. Здесь также возможны числа со знаком и без знака (рис. 2.12):
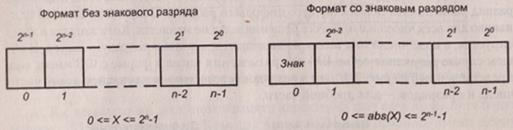
Рис. 2.12. Представление целых чисел в формате ФЗ
На рис. 2.13 приведены целочисленные форматы с фиксированной запятой, принятые в микропроцессорах фирмы Intel.
Целые числа применяются также для работы с адресами. На рис. 2.13 это 32-разрядный формат ближнего и 48-разрядный формат дальнего указателей.
Представление чисел в формате ФЗ упрощает аппаратурную реализацию ВМ и сокращает время выполнения машинных операций, однако при решении задач необходимо постоянно следить за тем, чтобы все исходные данные, промежуточные и результаты не выходили за допустимый диапазон формата, иначе возможно переполнение разрядной сетки и результат вычислений будет неверным.
Упакованные целые числа
В АСК современных микропроцессоров имеются команды, оперирующие целыми числами, представленными в упакованном виде. Связано это с обработкой мультимедийной информации. Формат предполагает упаковку в пределах достаточно длинного слова (обычно 64-разрядного) нескольких небольших целых чисел, а соответствующие команды обрабатывают всё эти числа параллельно. Если каждое из чисел состоит из четырех двоичных разрядов, то в 64-разрядное слово можно поместить до 16 таких чисел. Неиспользованные разряды заполняются нулями.

Рис. 2.13. Целочисленные форматы микропроцессоров фирмы Intel
В микропроцессорах фирмы Intel, начиная с Pentium ММХ, присутствуют специальные команды для обработки мультимедийной информации (ММХ-команды), оперирующие целыми числами, упакованными в квадрослова (64-разрядные слова). Предусмотрены три формата (рис. 2.14): упакованные байты (восемь 8-разрядных чисел); упакованные слова (четыре 16-разрядных числа) и упакованные двойные слова (два 32-разрядных числа).

Рис. 2.14. Форматы упакованных целых чисел в технологиях ММХ и 3DNow!
Байты в формате упакованных байтов нумеруются от 0 до 7, причем байт 0 располагается в младших разрядах квадрослова. Аналогичная система нумерации и размещения упакованных чисел применяется для упакованных слов (номера 0-3) и упакованных двойных слов (номера 0-1).
Идентичные форматы упакованных данных применяются также в другой технологии обработки мультимедийной информации, предложенной фирмой AMD. Эта технология носит название SDNow!, а реализована в микропроцессорах данной фирмы.
Десятичные числа
В ряде задач, главным образом, у четно-статистического характера, приходится иметь дело с хранением, обработкой и пересылкой десятичной информации. Особенность таких задач состоит в том, что обрабатываемые числа могут состоять из различного и весьма большого количества десятичных цифр. Традиционные методы обработки с переводом исходных данных в двоичную систему счисления и обратным преобразованием результата зачастую сопряжены с существенными накладными расходами. По этой причине в ВМ применяются иные специальные формы представления десятичных данных. В их основу положен принцип кодирования каждой десятичной цифры эквивалентным двоичным числом из четырех битов (тетрадой), то есть так называемым двоично-десятичным кодом (BCD — Binary Coded Decimal).
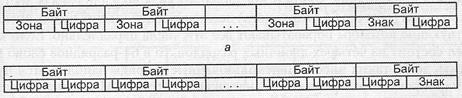
Рис. 2.15. Форматы десятичных чисел: а — зонный; б — уплотненный
Используются два формата представления десятичных чисел (все числа рассматриваются как целые): зонный (распакованный) и уплотненный (упакованный). В обоих форматах каждая десятичная цифра представляется двоичной тетрадой, то есть заменяется двоично-десятичным кодом. Из оставшихся задействованных шести четырехразрядных двоичных комбинаций (24 =16) две служат для кодирования знаков «+» и «-». Например, в ВМ семейства IBM 360/370/390 для знака «плюс» выбран код 11002 = C1G, а для знака «минус» — код 11012 = DIC.
Зонный формат (рис. 2.15, а) применяется в операциях ввода/вывода. В нем под каждую цифру выделяется один байт, где младшие четыре разряда отводятся под код цифры, а в старшую тетраду (поле зоны) записывается специальный код «зона», не совпадающий с кодами цифр и знаков. В IBM'360/370/390 это код 11112 = F,6. Исключение составляет байт, содержащий младшую цифру десятичного числа, где в поле зоны хранится знак числа. На рис. 2.16 показана запись числа -7396 в зонном формате. В некоторых ВМ принят вариант зонного формата, где поле зоны заполняется нулями.

Рис. 2.16. Представление числа -7396 в зонном формате
При выполнении операций сложения и вычитания над десятичными числами обычно используется упакованный формат и в нем же получается результат (умножение и деление возможно только в зонном формате). В упакованном формате (рис. 2.15, б) каждый байт содержит коды двух десятичных цифр. Правая тетрада последнего байта предназначается для записи знака числа. Десятичное число должно занимать целое количество байтов. Если это условие не выполняется, то четыре старших двоичных разряда левого байта заполняется нулями. Так, представление числа -7396 в упакованном формате имеет вид, приведенный на рис. 2.17.

Рис. 2.17. Представление числа -7396 в упакованном формате
Размещение знака в младшем байте, как в зонном, так и в упакованном представлениях, позволяет задавать десятичные числа произвольной длины и передавать их в виде цепочки байтов. В этом случае знак указывает, что байт, в котором он содержится, является последним байтом данного числа, а следующий байт последовательности — это старший байт очередного числа.
Числа в форме с плавающей запятой
От недостатков ФЗ в значительной степени свободна форма представления чисел с плавающей запятой (ПЗ), известная также под названиями нормальной или полулогарифмической формы. В данном варианте каждое число разбивается на две группы цифр. Первая группа цифр называется мантиссой, вторая — порядком. Число представляется в виде произведения 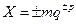 , где т — мантисса числа X, р — порядок числа, q — основание системы счисления.
, где т — мантисса числа X, р — порядок числа, q — основание системы счисления.
Для представления числа в форме с ПЗ требуется задать знаки мантиссы и порядка, их модули в 17-ичном коде, а также основание системы счисления (рис. 2.18). Нормальная форма неоднозначна, так как взаимное изменение тир приводит к «плаванию» запятой, чем и обусловлено название этой формы.

Рис. 2.18. форма представления чисел с плавающей запятой
Диапазон и точность представления чисел с ПТ зависят от числа разрядов, отводимых под порядок и мантиссу. На рис. 2.19 показаны диапазоны разрядностей порядка и мантиссы, характерные для известных ВМ.
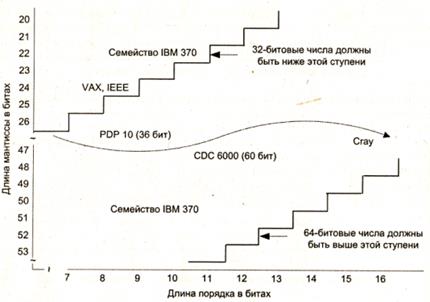
Рис. 2.19. Типовые разрядности полей порядка и мантиссы
Помимо разрядности порядка и мантиссы диапазон представления чисел зависит и от основания используемой системы счисления, которое может быть отличным от 2. Например, в универсальных ВМ (мэйнфреймах) фирмы IBM используется база 16. Это позволяет при одинаковом количестве битов, отведенных под порядок, представлять числа в большем диапазоне. Так, если поле порядка равно 7 битам, максимальное значение qp, на которое умножается мантисса, равно 2128 (при q = 2) или 16128 (при q = 16), а диапазоны представления чисел соответственно составят 10-19 < |Х| < 10+19 и 10-76 < |Х| < 10+76. Известны также случаи использования базы 8, например, в ВМ В-5500 фирмы Burroughs.
В большинстве вычислительных машин для упрощения операций над порядками последние приводят к целым положительным числам, применяя так называемый смещенный порядок. Для этого к истинному порядку добавляется целое положительное число — смещение (рис. 2.20). Например, в системе со смещением 128 порядок -3 представляется как 125 (-3 + 128). Обычно смещение выбирается равным половине представимого диапазона порядков. Отметим, что смещенный порядок занимает все биты поля порядка, в том числе и тот, который ранее использовался для записи знака порядка.

Рис. 2.20. Формат числа с ПЗ со смещенным порядком
Мантисса в числах с ПЗ обычно представляется в нормализованной форме. Это означает, что на мантиссу налагаются такие условия, чтобы она по модулю была меньше единицы 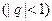 , а первая цифра после точки отличалась от нуля. Полученная таким образом мантисса называется нормализованной. Для применяемых в ВМ систем счисления можно записать:
, а первая цифра после точки отличалась от нуля. Полученная таким образом мантисса называется нормализованной. Для применяемых в ВМ систем счисления можно записать:
Дата добавления: 2019-04-03; просмотров: 449;