Становление и эволюция цифровой вычислительной техники 3 страница
Типы структур вычислительных машин и систем
Достоинства и недостатки архитектуры вычислительных машин и систем изначально зависят от способа соединения компонентов. При самом общем подходе можно говорить о двух основных типах структур вычислительных машин и двух типах структур вычислительных систем.
Структуры вычислительных машин
В настоящее время примерно одинаковое распространение получили два способа построения вычислительных машин: с непосредственными связями и на основе шины.
Типичным представителем первого способа может служить классическая фон-неймановская ВМ (см. рис. 1.3). В ней между взаимодействующими устройствами (процессор, память, устройство ввода/вывода) имеются непосредственные связи. Особенности связей (число линий в шинах, пропускная способность и т. п.) определяются видом информации, характером и интенсивностью обмена. Достоинством архитектуры с непосредственными связями можно считать возможность развязки «узких мест» путем улучшения структуры и характеристик только определенных связей, что экономически может быть наиболее выгодным решением. У фон-неймановских ВМ таким «узким местом» является канал пересылки данных между ЦП и памятью, и «развязать» его достаточно непросто [56]. Кроме того, ВМ с непосредственными связями плохо поддаются реконфигурации.
В варианте с общей шиной все устройства вычислительной машины подключены к магистральной шине, служащей единственным трактом для потоков команд, данных и управления (рис. 1.4). Наличие общей шины существенно упрощает реализацию ВМ, позволяет легко менять состав и конфигурацию машины. Благодаря этим свойствам шинная архитектура получила широкое распространение в мини и микро ЭВМ. Вместе с тем, именно с шиной связан и основной недостаток архитектуры: в каждый момент передавать информацию по шине может только одно устройство. Основную нагрузку на шину создают обмены между процессором и памятью, связанные с извлечением из памяти команд и данных и записью в память результатов вычислений. На операции ввода/вывода остается лишь часть пропускной способности шины. Практика показывает, что даже при достаточно быстрой шине для 90% приложений этих остаточных ресурсов обычно не хватает, особенно в случае ввода или вывода больших массивов данных.
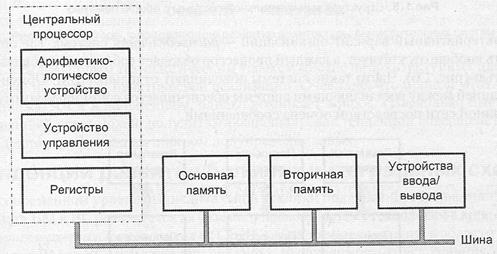
Рис. 1.4. Структура вычислительной машины на базе общей шины
В целом следует признать, что при сохранении фон-неймановской концепции последовательного выполнения команд программы шинная архитектура в чистом ее виде оказывается недостаточно эффективной. Более распространена архитектура с иерархией шин, где помимо магистральной шины имеется еще несколько дополнительных шин. Они могут обеспечивать непосредственную связь между устройствами с наиболее интенсивным обменом, например процессором и кэш-памятью. Другой вариант использования дополнительных шин — объединение однотипных устройств ввода/вывода с последующим выходом с дополнительной шины на магистральную. Все эти меры позволяют снизить нагрузку на общую шину и более эффективно расходовать ее пропускную способность.
Структуры вычислительных систем
Понятие «вычислительная система» предполагает наличие множества процессоров или законченных вычислительных машин, при объединении которых используется один из двух подходов.
В вычислительных системах с общей памятью (рис. 1.5) имеется общая основная память, совместно используемая всеми процессорами системы. Связь процессоров с памятью обеспечивается с помощью коммуникационной сети, чаще всего вырождающейся в общую шину. Таким образом, структура ВС с общей памятью аналогична рассмотренной выше архитектуре с общей шиной, в силу чего ей свойственны те же недостатки. Применительно к вычислительным системам данная схема имеет дополнительное достоинство: обмен информацией между процессорами не связан с дополнительными операциями и обеспечивается за счет доступа к общим областям памяти.
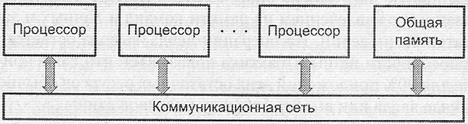
Рис 1.5. Структура вычислительной системы с общей памятью
Альтернативный вариант организации — распределенная система, где общая память вообще отсутствует, а каждый процессор обладает собственной локальной памятью (рис. 1.6). Часто такие системы объединяют отдельные ВМ. Обмен информацией между составляющими системы обеспечивается с помощью коммуникационной сети посредством обмена сообщениями.
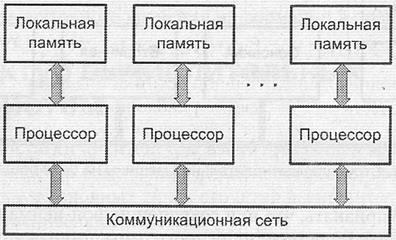
Рис 1.6. Структура распределенной вычислительной системы
Подобное построение ВС снимает ограничения, свойственные для общей шины, но приводит к дополнительным издержкам на пересылку сообщений между процессорами или машинами.
Перспективы совершенствования архитектуры ВМ и ВС
Совершенствование архитектуры вычислительных машин и систем началось с момента появления первых ВМ и не прекращается по сей день. Каждое изменение в архитектуре направлено на абсолютное повышение производительности или, по крайней мере, на более эффективное решение задач определенного класса. Эволюцию архитектур определяют самые различные факторы, главные из которых показаны на рис. 1.7. Не умаляя роли ни одного из них, следует признать, что наиболее очевидные успехи в области средств вычислительной техники все же связаны с технологическими достижениями. Характер и степень влияния прочих факторов подробно описаны в [120] и в данном учебнике не рассматриваются.
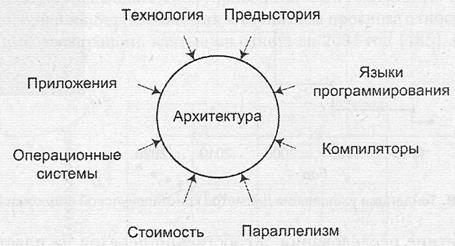
Рис 1.7. Факторы, определяющие развитие архитектуры вычислительных систем
С каждым новым технологическим успехом многие из архитектурных идей переходят на уровень практической реализации. Очевидно, что процесс этот будет продолжаться и в дальнейшем, однако возникает вопрос: «Насколько быстро?» Косвенный ответ можно получить, проанализировав тенденции совершенствования технологий, главным образом полупроводниковых.
Тенденции развития больших интегральных схем
На современном уровне вычислительной техники подавляющее большинство устройств ВМ и ВС реализуется на базе полупроводниковых технологий в виде сверхбольших интегральных микросхем (СБИС). Каждое нововведение в области архитектуры ВМ и ВС, как правило, связано с необходимостью усложнения схемы процессора или его составляющих и требует размещения на кристалле СБИС все большего числа логических или запоминающих элементов. Задача может быть решена двумя путями: увеличением размеров кристалла и уменьшением площади, занимаемой на кристалле элементарным транзистором, с одновременным повышением плотности упаковки таких транзисторов на кристалле.
Наиболее перспективным представляется увеличение размеров кристалла, однако только на первый взгляд. Кристаллической подложкой микросхемы служит тонкая пластина, представляющая собой срез цилиндрического бруска полупроводникового материала. Полезная площадь подложки ограничена вписанным в окружность квадратом или прямоугольником. Увеличение диаметра кристаллической подложки на 10% на практике позволяет получить до 60% прироста числа транзисторов на кристалле. К сожалению, технологические сложности, связанные с изготовлением кристаллической подложки большого размера без ухудшения однородности ее свойств по всей поверхности, чрезвычайно велики. Фактические тенденции в плане увеличения размеров кристаллической подложки СБИС иллюстрирует рис. 1.8.
Точки излома на графике соответствуют годам, когда переход на новый размер кристалла становится повсеместным. Каждому переходу обычно предшествуют 2-3-летние исследования, а собственно переход на пластины увеличенного диаметра происходит в среднем один раз в 9 лет.
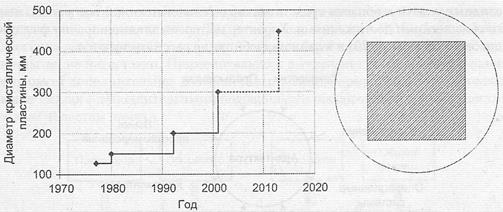
Рис.1.8. Тенденции увеличения диаметра кристаллической подложки СБИС
Пока основные успехи в плане увеличения емкости СБИС связаны с уменьшением размеров элементарных транзисторов и плотности их размещения на кристалле. Здесь тенденции эволюции СБИС хорошо описываются эмпирическим законом Мура [168]. В 1965 году Мур заметил, что число транзисторов, которое удается разместить на кристалле микросхемы, удваивается каждые 12 месяцев. Он предсказал, что эта тенденция сохранится в 70-е годы, а начиная с 80-х темп роста начнет спадать. В 1995 году Мур уточнил свое предсказание, сделав прогноз, что удвоение числа транзисторов далее будет происходить каждые 24 месяца.
Создание интегральных микросхем предполагает два этапа. Первый из них носит название литографии и заключается в получении маски, определяющей структуру будущей микросхемы. На втором этапе маска накладывается на полупроводниковую пластину, после чего пластина облучается, в результате чего и формируется микросхема. Уменьшение размеров элементов на кристалле напрямую зависит от возможностей технологии (рис. 1.9).
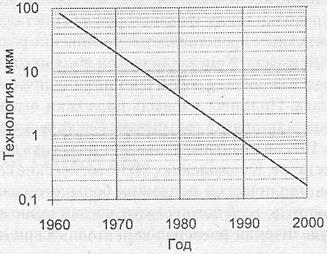
Рис1.9. Размер минимального элемента на кристалле интегральной микросхемы
Современный уровень литографии сделал возможным серийный выпуск СБИС, в которых размер элемента не превышает 0,13 мкм. Чтобы оценить перспективы развития возможностей литографии на ближайший период, обратимся к прогнозу авторитетного эксперта в области полупроводниковых технологий — International Technology Roadmap for Semiconductors. Результаты прогноза относительно будущих достижений литографии, взятые из отчета за 2001 год [185], приведены на рис. 1.10.
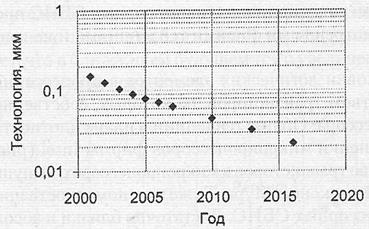
Рис. 1.10. Прогноз максимальных размеров элементов на кристалле СБИС
Наконец, еще одна общая тенденция в технологии СБИС — переход от алюминиевых соединительных линий на кристалле на медные. «Медная» технология позволяет повысить быстродействие СБИС примерно на 10% с одновременным снижением потребляемой мощности.
Приведенные выше закономерности определяют общие направления совершенствования технологий СБИС. Для более объективного анализа необходимо принимать во внимание функциональное назначение микросхем. В аспекте архитектуры ВМ и ВС следует отдельно рассмотреть «процессорные» СБИС и СБИС запоминающих устройств.
Тенденции развития элементной базы процессорных устройств
Современные технологии производства сверхбольших интегральных микросхем позволяют разместить на одном кристалле логические схемы всех компонентов процессора. В настоящее время процессоры всех вычислительных машин реализуются в виде одной или нескольких СБИС. Более того, во многих многопроцессорных ВС используются СБИС, где на одном кристалле располагаются сразу несколько процессоров (обычно не очень сложных). Каждый успех создателей процессорных СБИС немедленно положительно отражается на характеристиках ВМ и ВС. Совершенствование процессорных СБИС ведется по разным направлениям. Для целей данного учебника основной интерес представляет увеличение количества логических элементов, которое может быть размещено на кристалле, и повышение быстродействия этих логических элементов. Увеличение быстродействия ведет к наращиванию производительности процессоров даже без изменения их архитектуры, а в совокупности с повышением плотности упаковки логических элементов открывает возможности для реализации ранее недоступных архитектурных решений.
К увеличению числа логических элементов на кристалле ведут три пути:
· увеличение размеров кристалла;
· уменьшение размеров элементарных транзисторов;
· уменьшение ширины проводников, образующих внутренние шины или соединяющих логические элементы между собой.
Увеличение размеров кристаллов процессорных СБИС происходит в соответствии с ранее рассмотренными общими тенденциями и не имеет каких-либо особенностей.
Плотность упаковки логических элементов в процессорных СБИС принято оценивать количеством транзисторов, из которых, собственно, и строятся логические схемы процессора. Общие тенденции в плане плотности упаковки проследим на примере линейки микропроцессоров фирмы Intel (рис. 1.11). Из рисунка видно, что количество транзисторов в микропроцессорах, выпущенных до 2002 года, хорошо согласуется с законом Мура. Та же закономерность прослеживается и для других типов процессорных СБИС. Достаточно близки и абсолютные показатели разных микропроцессоров, выпущенных приблизительно в один и тот же период. Так, микропроцессор Pentium 4 фирмы Intel содержит 42 млн транзисторов, а микропроцессор Athlon XL фирмы AMD — 37 млн.
Чтобы оценить перспективы роста плотности упаковки на ближайшие два десятилетия, на рис. 1.11 дополнительно приведены прогностические данные на период до 2020 года, взятые из [185]. Нетрудно заметить, что прогноз также не слишком расходится с уточненным законом Мура. Общий итог можно сформулировать следующим образом: плотность упаковки логических схем процессорных СБИС каждые два года будет возрастать вдвое.
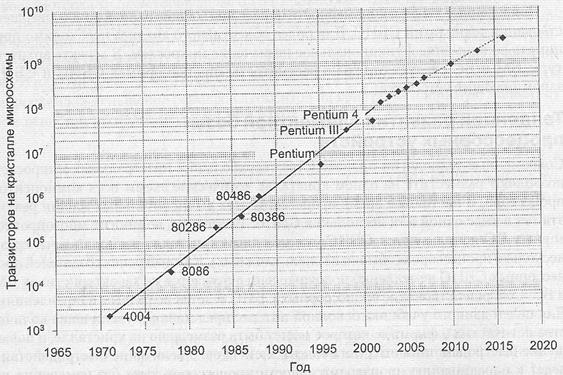
Рис 1.11. Тенденции увеличения количества транзисторов на кристаллах процессорных СБИС
В качестве параметра, характеризующего быстродействие логических схем процессорных СБИС, обычно используют так называемую внутреннюю тактовую частоту. На рис. 1.12 показаны значения тактовых частот микропроцессоров фирмы Intel. Из графика видно стремление к росту внутренней тактовой частоты процессорных СБИС: удвоение частоты происходит в среднем каждые два года. На рисунке присутствует также прогноз на ближайший период (данные взяты из [185]), из которого явствует, что в ближайшем будущем темп увеличения внутренней тактовой частоты может несколько снизиться.
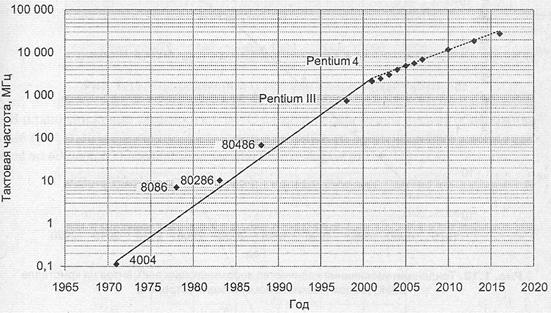
Рис. 1.12. Тенденции увеличения внутренней тактовой частоты процессорных СБИС
Тенденции развития полупроводниковых запоминающих устройств
По мере повышения возможностей вычислительных средств растут и «аппетиты» программных приложений относительно емкости основной памяти. Эту ситуацию отражает так называемый закон Паркинсона: «Программное обеспечение увеличивается в размерах до тех пор, пока не заполнит всю доступную на данный момент память». В цифрах тенденция возрастания требований к емкости памяти выглядит так: увеличение в полтора раза каждые два года. Основная память современных ВМ и ВС формируется из СБИС полупроводниковых запоминающих устройств, главным образом динамических ОЗУ. Естественные требования к таким СБИС: высокие плотность упаковки запоминающих элементов и быстродействие, низкая стоимость.
Плотность упаковки запоминающих элементов на кристалле динамического ОЗУ принято характеризовать емкостью хранимой информации в битах. Представление о современном состоянии и перспективах на ближайшее будущее дает график, приведенный на рис. 1.13. Для СБИС памяти также подтверждается справедливость закона Мура и предсказанное им уменьшение темпов повышения плотности упаковки. В целом можно предсказать, что число запоминающих элементов на кристалле будет возрастать в два раза каждые полтора года.
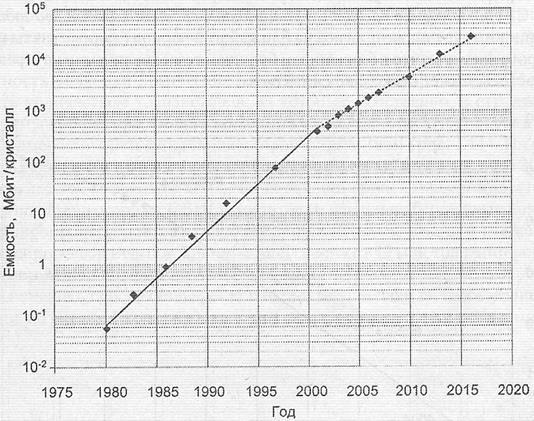
Рис. 1.13. Тенденции увеличения количества запоминающих элементов на кристалле СБИС динамических запоминающих устройств
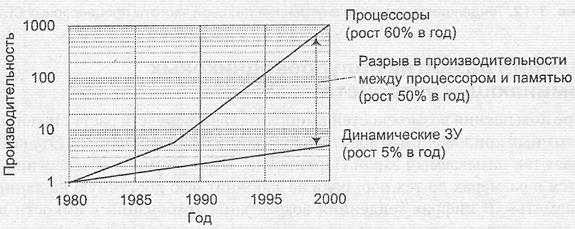
Рис. 1.14. Разрыв в производительности процессоров и динамических запоминающих устройств
С быстродействием СБИС памяти дело обстоит хуже. Высокая скорость процессоров уже давно находится в противоречии с относительной медлительностью запоминающих устройств основной памяти. Проблема постоянно усугубляется несоответствием темпов роста тактовой частоты процессоров и быстродействия памяти, и особых перспектив в этом плане пока не видно, что иллюстрирует рис. 1.14.
Абсолютные темпы снижения длительности цикла памяти, начиная с 1980 года, показаны на рис. 1.15. Общая тенденция: на двукратное уменьшение длительности цикла динамического ЗУ уходит примерно 15 лет.
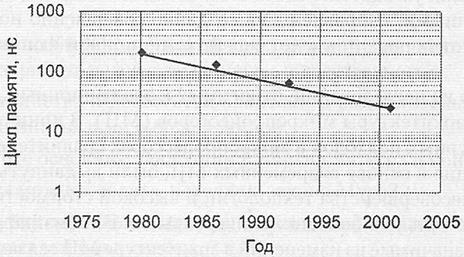
Рис. 1.15. Быстродействие микросхем динамической памяти
В плане снижения стоимости СБИС памяти перспективы весьма обнадеживающие (рис. 1.16). В течение достаточно длительного времени стоимость в пересчете на один бит снижается примерно на 25-40% в год.
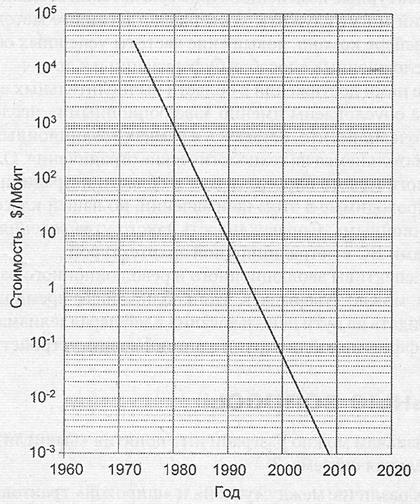
Рис. 1.16. Тенденции снижения стоимости СБИС динамической памяти в пересчете на 1 Мбит
Перспективные направления исследований в области архитектуры
Основные направления исследований в области архитектуры ВМ и ВС можно условно разделить на две группы: эволюционные и революционные. К первой группе следует отнести исследования, целью которых является совершенствование методов реализации уже достаточно известных идей. Изыскания, условно названные революционными, направлены на создание совершенно новых архитектур, принципиально отличных от уже ставшей традиционной фон-неймаповской архитектуры.
Большинство из исследований, относимых к эволюционным, связано с совершенствованием архитектуры микропроцессоров (МП). В принципе кардинально новых архитектурных подходов в микропроцессорах сравнительно мало. Основные идеи, лежащие в основе современных МП, были выдвинуты много лет тому назад, но из-за несовершенства технологии и высокой стоимости реализации нашли применение только в больших универсальных ВМ (мэйнфреймах) и суперЭВМ. Наиболее значимые из изменений в архитектуре МП связаны с повышением уровня параллелизма на уровне команд (возможности одновременного выполнения нескольких команд). Здесь в первую очередь следует упомянуть конвейеризацию, суперскалярную обработку и архитектуру с командными словами сверхбольшой длины (VLIW). После успешного переноса на МП глобальных архитектурных подходов «больших» систем основные усилия исследователей теперь направлены на частные архитектурные изменения. Примерами таких эволюционных архитектурных изменений могут служить: усовершенствованные методы предсказания переходов в конвейере команд, повышение частоты успешных обращений к кэш-памяти за счет усложненных способов буферизации и т. п.
Наблюдаемые нами достижения в области вычислительных средств широкого применения пока обусловлены именно «эволюционными» исследованиями. Однако уже сейчас очевидно, что, оставаясь в рамках традиционных архитектур, мы довольно скоро натолкнемся на технологические ограничения. Один из путей преодоления технологического барьера лежит в области нетрадиционных подходов. Исследования, проводимые в этом направлении, по нашей классификации отнесены к «революционным». Справедливость такого утверждения подтверждается первыми образцами ВС с нетрадиционной архитектурой.
Оценивая перспективы эволюционного и революционного развития вычислительной техники, можно утверждать, что на ближайшее время наибольшего прогресса можно ожидать на пути использования идей параллелизма на всех его уровнях и создания эффективной иерархии запоминающих устройств.
Контрольные вопросы
1. По каким признакам можно разграничить понятия «вычислительная машина» и «вычислительная система»?
2. В чем состоит различие между «узкой» и «широкой» трактовкой понятия «архитектура вычислительной машины»?
3. Какой уровень детализации вычислительной машины позволяет определить, можно ли данную ВМ причислить к фон-неймановским?
4. Какие закономерности в эволюции вычислительных машин породили появление нового научного направления — «Теория эволюции компьютеров»?
5. По каким признакам выделяют поколения вычислительных машин?
6. Поясните определяющие идеи для каждого из этапов эволюции вычислительной техники.
7. Какой из принципов фон-неймановской концепции вычислительной машины можно рассматривать в качестве наиболее существенного?
8. Оцените достоинства и недостатки архитектур вычислительных машин с непосредственными связями и общей шиной.
9. Сформулируйте основные тенденции развития интегральной схемотехники.
10. Какие выводы можно сделать, исходя из закона Мура?
11. Охарактеризуйте основные направления в дальнейшем развитии архитектуры вычислительных машин и систем.
Глава 2
Архитектура системы команд
Системой команд вычислительной машины называют полный перечень команд, которые способна выполнять данная ВМ. В свою очередь, под архитектурой системы команд (АСК) принято определять те средства вычислительной машины, которые видны и доступны программисту. АСК можно рассматривать как линию согласования нужд разработчиков программного обеспечения с возможностями создателей аппаратуры вычислительной машины (рис. 2.1).
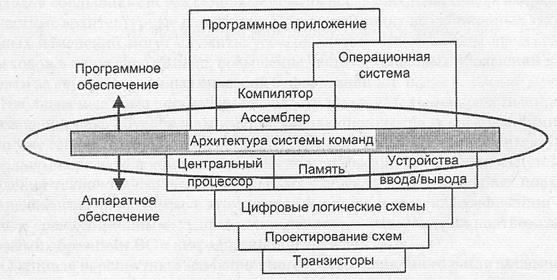
Рис. 2.1. Архитектура системы команд как интерфейс между программным и аппаратным обеспечением
В конечном итоге, цель тех и других — реализация вычислений наиболее эффективным образом, то есть за минимальное время, и здесь важнейшую роль играет правильный выбор архитектуры системы команд.
В упрощенной трактовке время выполнения программы (Твыч) можно определить через число команд в программе (Nком), среднее количество тактов процессора, приходящихся на одну команду (CPI), и длительность тактового периода τпр:
Твыч = Nком × CPI × τпр
Каждая из составляющих выражения зависит от одних аспектов архитектуры системы команд и, в свою очередь, влияет на другие (рис. 2.2), что свидетельствует о необходимости чрезвычайно ответственного подхода к выбору АСК.
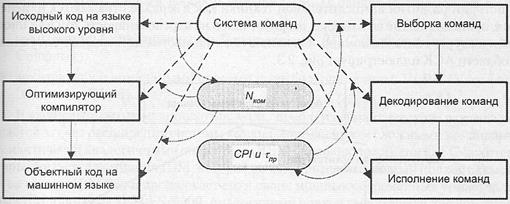
Рис. 2.2. Взаимосвязь между системой команд и факторами, определяющими эффективность вычислений
Общая характеристика архитектуры системы команд вычислительной машины складывается из ответов на следующие вопросы:
1. Какого вида данные будут представлены в вычислительной машине и в какой форме?
2. Где эти данные могут храниться помимо основной памяти?
3. Каким образом будет осуществляться доступ к данным?
4. Какие операции могут быть выполнены над данными?
5. Сколько операндов может присутствовать в команде?
6. Как будет определяться адрес очередной команды?
7. Каким образом будут закодированы команды?
Предметом данной главы является обзор наиболее распространенных архитектур системы команд, как в описательном плане, так и с позиций эффективности. В главе приводятся доступные статистические данные, позволяющие дополнить качественный анализ различных АСК количественными показателями. Большинство представленных статистических данных почерпнуто из общепризнанного источника — публикаций Д. Хеннеси и Д. Паттерсона. Данные были получены в результате реализации на вычислительной машине DEC VAX трех программных продуктов: компилятора с языка С GCC, текстового редактора ТеХ и системы автоматизированного проектирования Spice. Считается, что GCC и ТеХ показательны для программных приложений, где превалируют целочисленные вычисления и обработка текстов, a Spice может рассматриваться как типичный представитель вычислений с вещественными числами. С учетом того, что архитектура вычислительной машины VAX в известном смысле уже устарела, Хеннеси и Паттерсоном, а также приверженцами их методики были проведены дополнительные исследования, где программы GCC, Spice и ТеХ выполнялись на более современной ВМ, в частности MIPS R2000. Доступные данные для этого варианта также приводятся.
Классификация архитектур системы команд
В истории развития вычислительной техники как в зеркале отражаются изменения, происходившие во взглядах разработчиков на перспективность той или иной архитектуры системы команд. Сложившуюся на настоящий момент ситуацию в области АСК иллюстрирует рис. 2.3.
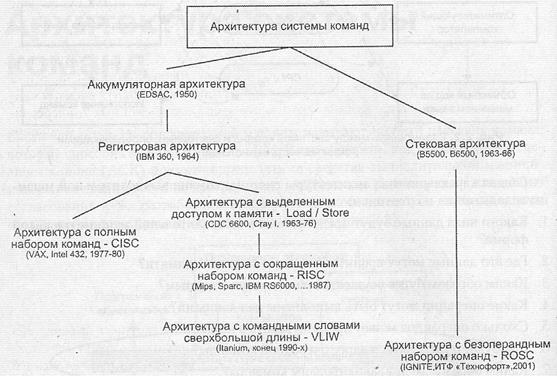
Рис. 2.3. Хронология развития архитектур системы команд
Среди мотивов, чаще всего предопределяющих переход к новому типу АСК, остановимся на двух наиболее существенных. Первый — это состав операций, выполняемых вычислительной машиной, и их сложность. Второй — место хранения операндов, что влияет на количество и длину адресов, указываемых в адресной части команд обработки данных. Именно эти моменты взяты в качестве критериев излагаемых ниже вариантов классификации архитектур системы команд.
Классификация по составу и сложности команд
Современная технология программирования ориентирована на языки высокого уровня (ЯВУ), главная цель которых — облегчить процесс программирования. Переход к ЯВУ, однако, породил серьезную проблему: сложные операторы, характерные для ЯВУ, существенно отличаются от простых машинных операций, реализуемых в большинстве вычислительных машин. Проблема получила название семантического разрыва, а ее следствием становится недостаточно эффективное выполнение программ на ВМ. Пытаясь преодолеть семантический разрыв, разработчики вычислительных машин в настоящее время выбирают один из трех подходов и, соответственно, один из трех типов АСК:
· архитектуру с полным набором команд: CISC (Complex Instruction Set Computer);
· архитектуру с сокращенным набором команд: RISC (Reduced Instruction Set Computer);
· архитектуру с командными словами сверхбольшой длины: VLIW (Very Long Instruction Word).
В вычислительных машинах типа CISC проблема семантического разрыва решается за счет расширения системы команд, дополнения ее сложными командами, семантически аналогичными операторам ЯВУ. Основоположником CISC-архитектуре считается компания IBM, которая начала применять данный подход с семейства машин IBM 360 и продолжает его в своих мощных современных универсальных ВМ, таких как IBM ES/9000. Аналогичный подход характерен и для компании Intel в ее микропроцессорах серии 8086 и Pentium. Для CISC-архитектуры типичны:
· наличие в процессоре сравнительно небольшого числа регистров общего назначения;
· большое количество машинных команд, некоторые из них аппаратно реализуют сложные операторы ЯВУ;
· разнообразие способов адресации операндов;
· множество форматов команд различной разрядности;
· наличие команд, где обработка совмещается с обращением к памяти.
К типу CISC можно отнести практически все ВМ, выпускавшиеся до середины 1980-х годов, и значительную часть производящихся в настоящее время. Рассмотренный способ решения проблемы семантического разрыва вместе с тем ведет к усложнению аппаратуры ВМ, главным образом устройства управления, что, в свою очередь, негативно сказывается на производительности ВМ в целом. Это заставило более внимательно проанализировать программы, получаемые после компиляции с ЯВУ. Был предпринят комплекс исследований [128,158,177,209], в результате которых обнаружилось, что доля дополнительных команд, эквивалентных операторам ЯВУ, в общем объеме программ не превышает 10-20%, а для некоторых наиболее сложных команд даже 0,2%. В то же время объем аппаратных средств, требуемых для реализации дополнительных команд, возрастает весьма существенно. Так, емкость микропрограммной памяти при поддержании сложных команд может увеличиваться на 60%.
Детальный анализ результатов упомянутых исследований привел к серьезному пересмотру традиционных решений, следствием чего стало появление RISC-архитектуры. Термин RISC впервые был использован Д. Паттерсоном и Д. Дитцелем в 1980 году [177]. Идея заключается в ограничении списка команд ВМ наиболее часто используемыми простейшими командами, оперирующими данными, размещенными только в регистрах процессорах. Обращение к памяти допускается лишь с помощью специальных команд чтения и записи. Резко уменьшено количество форматов команд и способов указания адресов операндов. Сокращение числа форматов команд и их простота, использование ограниченного количества способов адресации, отделение операций обработки данных от операций обращения к памяти позволяет существенно упростить аппаратные средства ВМ и повысить их быстродействие. RISC-архитектура разрабатывалась таким образом, чтобы уменьшить Твыч а счет сокращения CPI и τпр. Как следствие, реализация сложных команд за счет последовательности из простых, но быстрых RISC-команд оказывается не менее эффективной, чем аппаратный вариант сложных команд в CISC-архитектуре.
Элементы RISC-архитектуры впервые появились в вычислительных машинах CDC 6600 и суперЭВМ компании Cray Research. Достаточно успешно реализуется RISC-архитектура и в современных ВМ, например в процессорах Alpha фирмы DEC, серии РА фирмы Hewlett-Packard, семействе PowerPC и т. п.
Дата добавления: 2019-04-03; просмотров: 1386;