Принципы трансляции программ
Транслятор – это программа, которая переводит входную программу на исходном (входном) языке в эквивалентную ей выходную программу на результирующем (выходном) языке.
В определении транслятора, как и в его работе, участвует три программы.
Во-первых, сам транслятор – программа. Он входит в состав СПО, представляет собой набор машинных команд и данных и выполняется компьютером в рамках ОС.
Во-вторых, исходными данными для транслятора является текст входной программы. Как правило, это файл, содержащий текст программы и удовлетворяющий синтаксическим и семантическим требованиям входного языка.
В-третьих, выходными данными транслятора является текст результирующей программы, которая строится по синтаксическим правилам, заданным в выходном языке транслятора.
Важным требованием в определении транслятора является эквивалентность программ на входе и выходе. Нарушение этого требования делает работу транслятора бесполезной.
С точки зрения принципа работы транслятор выступает как переводчик: преобразует предложения входного языка в эквивалентные им предложения выходного языка. Кроме того, само слово «транслятор» означает «переводчик».
Кроме понятия «транслятор» широко применяется близкое понятие «компилятор».
Компилятор – это транслятор, осуществляющий перевод исходной программы в эквивалентную ей объектную программу на языке ассемблера. Отличие компилятора от транслятора состоит в том, его входная (результирующая) программа должна быть написана на языке машинных команд или на ассемблере. Результат работы транслятора может быть написан на любом языке.
Всякий компилятор является транслятором, но не всякий транслятор является компилятором.
Слово «компилятор» соответствует английскому «составитель», «компоновщик». Выданная компилятором программа или код не может непосредственно выполняться на компьютере из-за того, что не привязана к конкретной области памяти с кодами и данными. Компиляторы – самый распространенный вид трансляторов. Если трансляторы и компиляторы во многом похожи, то существуют принципиально отличное от них понятие интерпретатора.
Интерпретатор – это программа, которая воспринимает входную программу на исходном языке и выполняет ее.
Интерпретатор в отличие от транслятора не выдает результирующую программу или код. После анализа текста исходной программы интерпретатор сразу же ее выполняет в соответствии с ее смыслом. Интерпретатор преобразует исходную программу в машинные коды, которые не доступны пользователю. Машинные коды порождаются интерпретатором, исполняются и уничтожаются.
Процесс компиляции состоит из двух основных этапов − анализа и синтеза .
На этапе анализа распознается текст исходной программы, создаются и заполняются таблицы идентификаторов. Результатом анализа является некое внутреннее представление программы, понятное компилятору.
На этапе синтеза из внутреннего представления программы и информации из таблицы идентификаторов, получается результирующая объектная программа.
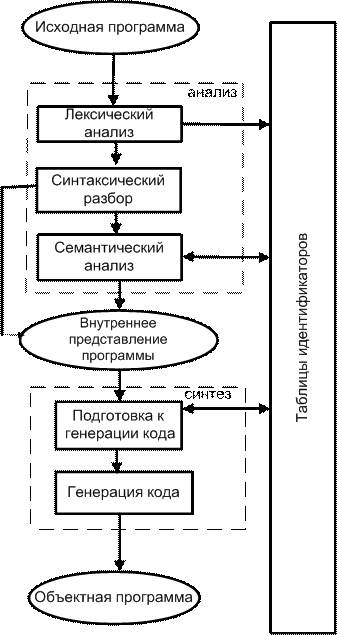
Рис.3.2. Компиляция программ
В составе компилятора присутствует часть, ответственная за анализ и исправление ошибок. При наличии ошибок в тексте исходной программы пользователь должен получить максимально полную информацию о типе ошибки и месте ее возникновения.
Компилятор с точки зрения теории формальных языков выполняет две основные функции:
1) он является распознавателем для языка исходной программы. Получает на вход цепочку символов входного языка, проверяет ее принадлежность языку и выявляет правила, по которым эта цепочка построена;
2) он генерирует результирующую программу. На выходе создается цепочка выходного языка по определенным правилам. Распознавателем сгенерированной цепочки объектной программы будет выступать вычислительная система.
Кратко представим функции основных фаз компиляции:
Лексический анализ. Эту часть компилятора выполняет сканер, который читает литеры программы (символы) на исходном языке и строит из них слова (лексемы) исходного языка. На входе сканера (лексического анализатора) текст исходной программы, выходная информация передается для дальнейшей обработки на этап синтаксического разбора.
Синтаксический разбор − это основная часть компилятора на этапе анализа. Здесь в тексте исходной программы выделяются синтаксические конструкции. Кроме того, проверяется синтаксическая правильность программы.
Семантический анализ − это часть компилятора, проверяющая часть текста исходной программы с точки зрения семантики входного языка.
Подготовка к генерации кода − на этой фазе компилятор выполняет предварительные действия, непосредственно связанные с синтезом текста результирующей программы: идентификация элементов языка, распределение памяти и т.п. Эта подготовка ещё не ведёт к порождению текста на выходном языке.
Генерация кода − это фаза, на которой непосредственно порождаются команды, составляющие предложения выходного языка и текст результирующей программы в целом. Фаза генерации кода основная на этапе синтеза результирующей программы. Кроме этого, генерация обычно включает в себя и оптимизацию. Оптимизация − это процесс, связанный с обработкой уже порожденного текста и оказывающий существенное влияние на качество и эффективность результирующей программы.
Таблицы идентификаторов
Таблицы идентификаторов – это специальным образом организованные наборы данных, которые хранят информацию об элементах исходной программы. Содержимое таблицы идентификаторов используется для порождения текста результирующей программы. В процессе компиляции нужно хранить информацию о переменных, константах, функциях и т.п. Конкретный состав таблицы идентификаторов зависит от используемого входного языка программирования.
Порядок выполнения фаз компиляции может меняться в разных вариантах компиляторов. В одних компиляторах просмотр текста исходной программы сопровождается выполнением всех фаз компиляции и получением результата − объектного кода. В других − над исходным текстом выполняются только некоторые фазы компиляции, и получается не конечный результат, а набор некоторых промежуточных данных, которые снова подвергаются обработке. Причем несколько раз. Реальные компиляторы транслируют текст исходной программы за несколько проходов. Проход − это процесс последовательного чтения компилятором данных из внешней памяти, их обработки и записи результата во внешнюю память. Чаще всего один проход включает в себя выполнение одной или нескольких фаз компиляции. В качестве внешней памяти могут выступать любые носители информации − ОП, накопители на магнитных дисках, лентах и т.д. При выполнении каждого прохода компилятору доступна информация, полученная в результате всех предыдущих проходов. Но, как правило, в первую очередь используется информация, полученная на проходе, непосредственно предшествующему текущему. Информация, получаемая компилятором при выполнении проходов, недоступна пользователю. Человек, компилирующий свою программу, видит только исходный текст программы и результирующую объектную программу. Очевидно, что цель разработчиков компиляторов − максимально сократить количество проходов. Это необходимо для увеличения скорости работы компилятора и уменьшения объема необходимой ему памяти. Идеал − однопроходный компилятор, получающий на вход исходную программу и сразу же генерирующий результирующую объектную программу.
Но сократить число проходов не всегда возможно. Количество проходов определяется, прежде всего, грамматикой и семантическими правилами исходного языка. Чем сложнее грамматика языка и чем больше вариантов предполагают семантические правила − тем больше проходов будет выполнять компилятор. Например, компиляторы с языка Pascal работают быстрее, чем компиляторы с языка С из-за того, что грамматика языка Pascal более проста, а семантические правила более жёсткие.
Однопроходные компиляторы − редкость, они возможны только для очень простых языков. Реальные компиляторы выполняют от двух до пяти проходов и являются многопроходными. Например, трехпроходный компилятор работает так:
− первый проход − лексический анализ;
− второй − синтаксический разбор и семантический анализ;
− третий − генерация и оптимизация кода.
Дата добавления: 2018-11-25; просмотров: 448;