Лексический и синтаксический анализ и генерация кода.
Лексический анализ — процесс аналитического разбора входной последовательности символов (например, такой как исходный код на одном из языков программирования) с целью получения на выходе последовательности символов, называемых «токенами» (подобно группировке букв в слова). Группа символов входной последовательности, идентифицируемая на выходе процесса как токен, называется лексемой. В процессе лексического анализа производится распознавание и выделение лексем из входной последовательности символов.
Как правило, лексический анализ производится с точки зрения определённого формального языка или набора языков. Язык, а точнее его грамматика, задаёт определённый набор лексем, которые могут встретиться на входе процесса.
Традиционно принято организовывать процесс лексического анализа, рассматривая входную последовательность символов как поток символов. При такой организации процесс самостоятельно управляет выборкой отдельных символов из входного потока.
Распознавание лексем в контексте грамматики обычно производится путём их идентификации (или классификации) согласно идентификаторам (или классам) токенов, определяемых грамматикой языка. При этом любая последовательность символов входного потока (лексема), которая согласно грамматике не может быть идентифицирована как токен языка, обычно рассматривается как специальный токен-ошибка.
Каждый токен можно представить в виде структуры, содержащей идентификатор токена (или идентификатор класса токена) и, если нужно, последовательность символов лексемы, выделенной из входного потока (строку, число и т. д.).
Цель такой конвертации обычно состоит в том, чтобы подготовить входную последовательность для другой программы, например для грамматического анализатора, и избавить его от определения лексических подробностей в контекстно-свободной грамматике (что привело бы к усложнению грамматики).
Лексический анализатор (англ. lexical analyzer или коротко lexer) — это программа или часть программы, выполняющая лексический анализ. Лексический анализатор обычно работает в две стадии: сканирование и оценка.
На первой стадии, сканировании, лексический анализатор обычно реализуется в виде конечного автомата, определяемого регулярными выражениями. В нём кодируется информация о возможных последовательностях символов, которые могут встречаться в токенах . Например, токен «целое число» может содержать любую последовательность десятичных цифр. Во многих случаях первый непробельный символ может использоваться для определения типа следующего токена, после чего входные символы обрабатываются один за другим пока не встретится символ, не входящий во множество допустимых символов для данного токена. В некоторых языках правила разбора лексем несколько более сложные и требуют возвратов назад по читаемой последовательности.
Полученный таким образом токен содержит необработанный исходный текст (строку). Для того чтобы получить токен со значением, соответствующим типу (напр. целое или дробное число), выполняется оценка этой строки — проход по символам и вычисление значения.
Токен с типом и соответственно подготовленным значением передаётся на вход синтаксического анализатора.
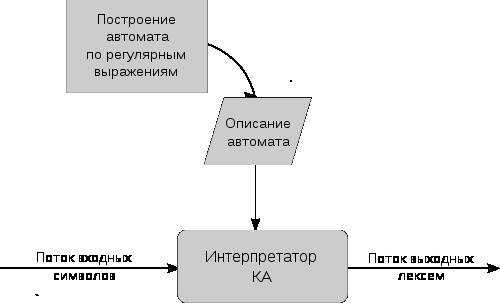
Рисунок .3.3
Синтакси́ческий ана́лиз (па́рсинг) — это процесс сопоставления линейной последовательности лексем (слов, токенов) языка с его формальной грамматикой. Результатом обычно является дерево разбора (синтаксическое дерево). Синтаксический анализатор (парсер) — это программа или часть программы, выполняющая синтаксический анализ.
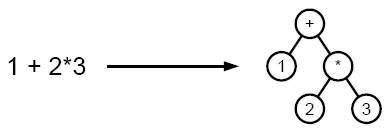
Пример разбора выражения в дерево
При парсинге исходный текст преобразуется в структуру данных, обычно — в дерево, которое отражает синтаксическую структуру входной последовательности и хорошо подходит для дальнейшей обработки.
Как правило, результатом синтаксического анализа является синтаксическая структура предложения, представленная либо в виде дерева зависимостей, либо в виде дерева составляющих, либо в виде некоторой комбинации первого и второго способов представления.
Синтаксический анализ – это процесс, который определяет, принадлежит ли некоторая последовательность лексем языку, порождаемому грамматикой. В принципе, по любой грамматике можно построить синтаксический анализатор, но грамматики, используемые на практике, имеют специальную форму. Например, известно, что для любой контекстно-свободной грамматики может быть построен анализатор, сложность которого не превышает O(n3) для входной строки длины n, но в большинстве случаев по заданному языку программирования мы можем построить такую грамматику, которая позволит сконструировать и более быстрый анализатор. Анализаторы реально используемых языков обычно имеют линейную сложность; это достигается, например, за счет просмотра исходной программы слева направо с заглядыванием вперед на один терминальный символ (лексический класс).
Вход синтаксического анализатора – последовательность лексических и таблицы, например, таблица внешних представлений, которые являются выходом лексического анализатора.
Выход синтаксического анализатора – дерево разбора и таблицы, например, таблица идентификаторов и таблица типов, которые являются входом для следующего просмотра компилятора (например, это может быть просмотр, осуществляющий контроль типов).
Большинство известных методов анализа принадлежат одному из двух классов, один из которых объединяет нисходящие (top-down) алгоритмы, а другой – восходящие (bottom-up) алгоритмы. Происхождение этих терминов связано с тем, каким образом строятся узлы синтаксического дерева: либо от корня (аксиомы грамматики) к листьям (терминальным символам), либо от листьев к корню.
Нисходящие анализаторы строят вывод, начиная от аксиомы грамматики и заканчивая цепочкой терминальных символов. С нисходящими анализаторами связаны так называемые LL-грамматики, которые обладают следующими свойствами:
Они могут быть проанализированы без возвратов.
Первая буква L означает, что мы просматриваем входную цепочку слева направо (leftto- right scan)
Вторая буква L означает, что строится левый вывод цепочки (leftmost derivation).
Популярность нисходящих анализаторов связана с тем, эффективный нисходящий анализатор достаточно легко может быть построен вручную, например, методом рекурсивного спуска. Кроме того, LL-грамматики легко обобщаются: грамматики, не являющиеся LL-грамматиками, обычно могут быть проанализированы методом рекурсивного спуска с возвратами.
С другой стороны, восходящие анализаторы могут анализировать большее количество грамматик, чем нисходящие, и поэтому именно для таких методов существуют программы, которые умеют автоматически строить анализаторы. С восходящими анализаторами связаны LR-грамматики. В этом обозначении буква L по-прежнему означает, что входная цепочка просматривается слева направо (left-to-right scan), а буква R означает, что строится правый вывод цепочки (rightmost derivation). С помощью LR- грамматик можно определить большинство использующихся в настоящее время языков программирования.
Загрузчик.
Поскольку результатом трансляции является модуль на языке, близком к машинному, в нем уже не остается признаков того, на каком исходном языке был написан программный модуль. Это создает принципиальную возможность создавать программы из модулей, написанных на разных языках. Специфика исходного языка, однако, может сказываться на физическом представлении базовых типов данных, способах обращения к процедурам/функциям и т.п. Для совместимости разноязыковых модулей должны выдерживаться общие соглашения.
Большая часть объектного модуля - команды и данные машинного языка именно в той форме, в какой они будут существовать во время выполнения программы. Однако, программа в общем случае состоит из многих модулей. Поскольку транслятор обрабатывает только один конкретный модуль, он не может должным образом обработать те части этого модуля, в которых запрограммированы обращения к данным или процедурам, определенным в другом модуле. Такие обращения называются внешними ссылками. Те места в объектном модуле, где содержатся внешние ссылки, транслируются в некоторую промежуточную форму, подлежащую дальнейшей обработке. Говорят, что объектный модуль представляет собой программу на машинном языке с неразрешенными внешними ссылками.
Разрешение внешних ссылок выполняется на следующем этапе подготовки, который обеспечивается Редактором Связей (Компоновщиком). Редактор Связей соединяет вместе все объектные модули, входящие в программу. Поскольку Редактор Связей "видит" уже все компоненты программы, он имеет возможность обработать те места в объектных модулях, которые содержат внешние ссылки. Результатом работы Редактора Связей является загрузочный модуль.
Загрузочный модуль - программный модуль, представленный в форме, пригодной для загрузки в оперативную память для выполнения.
Загрузочный модуль сохраняется в виде файла на внешней памяти. Для выполнения программа должна быть перенесена (загружена) в оперативную память. Иногда при этом требуется некоторая дополнительная обработка (например, настройка адресов в программе на ту область оперативной памяти, в которую программа загрузилась). Эта функция выполняется Загрузчиком, который обычно входит в состав операционной системы.
Возможен также вариант, в котором редактирование связей выполняется при каждом запуске программы на выполнение и совмещается с загрузкой.
Загрузчик - это системная программа, выполняющая загрузку. Многие загрузчики обеспечивают, кроме того, перемещение и связывание. В некоторых системах функция связывания отделена от функций перемещения и загрузки. Связывание выполняется специальной программой связывания (или редактором связей), перемещение и загрузка - загрузчиком.
Связывание - это связывание двух или более отдельных оттранслированных программ.
Перемещение - это модификация объектной программы так, чтобы она могла загружаться с адреса, отличного от первоначального.
Функции загрузчика:
o распределение ОП;
o перемещение программы;
o связывание модулей;
o загрузка программ в ОП и запуск на выполнение.
Это делает Связывающий Загрузчик. Вариант связывания при запуске более расходный, т.к. затраты на связывание тиражируются при каждом запуске. Но он обеспечивает:
o большую гибкость в сопровождении, так как позволяет менять отдельные объектные модули программы, не меняя остальных модулей;
o экономию внешней памяти, т.к. объектные модули, используемые во многих программах не копируются в каждый загрузочный модуль, а хранятся в одном экземпляре.
Виды загрузчиков
Загрузчики типа «компиляция-выполнение»
Одним из возможных способов выполнения функции загрузчика может быть такая организация работы ассемблера, при которой ассемблер, работая в одной части памяти, помещает машинные команды и данные по мере ассемблирования непосредственно в выделенные для них ячейки памяти. После завершения компиляции ассемблер передает управление в точку входа полученной программы. Это очень простое решение, позволяющее обойтись без каких-либо дополнительных процедур. Такая схема называется «компиляция-выполнение», а «загрузчик» состоит из одной команды, которая передает управление ассемблированной программе.
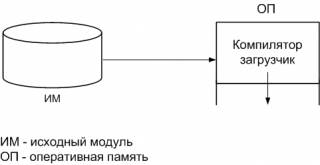
Однако эта схема имеет ряд недостатков:
o некоторая часть памяти не может быть использована, т.к. занятая ассемблером память недоступна для объектной программы;
o при каждом новом прогоне приходиться заново транслировать программу пользователя;
o трудно организовать работу нескольких сегментов программы, особенно, если исходные тексты написаны на разных языках, т.к. каждый язык создает свою среду в ОП.
Достоинства:
o распределение памяти выполняется автоматически;
o одна и та же программа-компилятор выполняет функции перемещения и связывания, загрузки и запуска.
Абсолютный загрузчик
Учитывая недостатки загрузчиков типа «компиляция-выполнение», видно, что целесообразным будет организовать хранение результатов трансляции на некотором внешнем носителе с тем, чтобы загрузить их, когда понадобится выполнить полученную программу. При этом ассемблированная программа может быть загружена в ту же область, которую раньше занимал ассемблер. Эта форма вывода называется объектной программой. Тогда работа загрузчика будет заключаться в том, что он принимает на входе ассемблированные команды и информацию, представленную в виде объектной программы, а сам в свою очередь помещает в память машинные команды, данные в выполнимой машинной форме. Этот тип загрузки устраняет основные недостатки рассмотренного ранее типа.
Простейший загрузчик, работающий по общей схеме, называется абсолютным. При этом ассемблер выводит результаты трансляции исходной программы почти в такой же форме как при схеме «компиляция-выполнение», за исключением того, что результаты помещаются не непосредственно в память, а выводятся на носитель. Загрузчик просто воспринимает текст программы на машинном языке и помещает его в память по адресу, указанному ассемблером.
Абсолютные загрузчики просты в реализации, но имеют ряд особенностей:
o задачу распределения ОП выполняет программист (с помощью директивы установки начального значения ОП);
o задачу перемещения программы выполняет компилятор;
o связывание модулей - решается программистом (call 600);
o загрузка программ в ОП и запуск на выполнение.
Достоинства:
o меньший объем загрузчика (по величине памяти);
o разделение фазы компиляции и загрузки, что сокращает время на обработку модулей;
o возможность использования нескольких языков программирования, т.к. структуры создаваемых объектных модулей идентичны.
Недостатки:
Большой объем работ ложится на программиста. Нужно постоянно отслеживать изменения начальных адресов при модификации модулей, т.к. изменяется их длина.
Дата добавления: 2018-11-25; просмотров: 553;