Построение реляционных баз данных. Таблицы
Структура таблиц
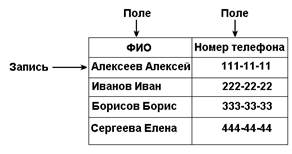
Типы данных в таблицах
| Текстовый | Алфавитно-цифровые данные |
| Memo | Алфавитно-цифровые данные - предложения, абзацы, тексты |
| Числовой | Числовые данные |
| Дата/Время | Даты и время |
| Денежный | Данные о денежных суммах, хранящиеся с 4 знаками после запятой |
| Счетчик | Уникальное длинное целое, генерируемое при создании каждой новой записи |
| Логический | Логические данные |
| Поле объекта OLE | Картинки, диаграммы или другие OLE-объекты |
| Гиперссылка | Гиперссылки, которые представляют собой путь у файлу на жестком диске либо адрес в сетях Internet |
В отличие от плоских, реляционные базы данных состоят из нескольких таблиц, связь между которыми устанавливается с помощью совпадающих значений одноименных полей.
Проблемы списков – если всё загнать в одну таблицу, то изменить номер телефона заказчика или заменить станок в цехе на другой инвентарный номер очень проблематично. Нужно заменять во всех строках, что может привести к ошибкам.
Другая проблема состоит в несовместимости данных. Мы можем сделать простую опечатку в наименовании станка и случайно написать 16К20 (К - латиницей) вместо 16К20 (К – кириллицей). Пользователи этого списка не поймут, то ли у нас появился новый станок, то ли это ошибка.
Проблемы совместно используемых локальных данных Другие проблемы использования списка всплывают, когда мы рассматриваем данные, которые совместно используются многими людьми. Компания хочет дать каждому доступ к именам подрядчиков и к телефонным номерам из общего источника данных. Таким образом, если кто-нибудь изменит телефонный номер, то это изменение нужно сделать в общем источнике данных компании. В противном случае сотрудникам придется изменить эти данные на каждом компьютере компании.
Проблемы совместно используемых данных в сети Однако если данные о подрядчике используются совместно, возникают другие проблемы. Бухгалтерия хочет вести учет счетов подрядчиков и платежей. Сотрудники отдела проката хотят отслеживать координаты подрядчиков, встречи и заказы. Отдел по работе с клиентами хочет знать, какие проблемы возникали с определенными подрядчиками и как они решались. Все эти отделы не обязательно хотят использовать данные совместно с другими отделами. Бухгалтерия, например, не хочет, чтобы кто-то другой имел доступ к данным о счетах и платежах. Отдел по работе с клиентами не хочет, чтобы кто-то в компании знал списки предполагаемых клиентов. Таким образом, отделы готовы совместно использовать только некоторые данные, но не все.
Решение – создание базы данных как группы связанных таблиц с серверным хранением данных. Это называется нормализацией.
Нормализация баз данных – процесс уменьшения избыточности информации в базе данных посредством разделения ее на несколько связанных друг с другом таблиц и называется нормализацией данных.
Естественно, необходимы связи между полями разных таблиц (отношения между таблицами).
Отношения между таблицами устанавливают связь между данными находящимися в разных таблицах базы данных. Отношения между таблицами определяются отношением между группами объектов соответствующего типа.
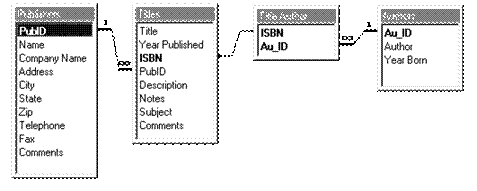
Рис.1.9. Отношения между таблицами базы данных BIBLIO.MDB
Отношение один-к-одному - это означает, что каждая запись в одной таблице соответствует только одной записи в другой таблице. Например, в одной таблице хранятся названия станка, его темплета, фото, чертежи узлов для проведения профилактики и ремонта, а в другой название станка и его характеристики для выбора в технологии. Тем самым отдел технологов и отдел эксплуатации оборудования не грузят к себе по сети ненужные сведения.
Отношение один-ко-многим - например отношение существует между станком и набором операций на нём.
Отношение много-к-одному – например отношение аналогично отношение один-ко-многим
Отношение много-ко-многим. Для удобства работы с таблицами, имеющими отношение много-ко-многим, обычно в базу данных добавляют еще одну таблицу, которая находится в отношении один-ко-многим и много-к-одному к соответствующим таблицам.
Ключипри описании отношений между таблицами, в реляционных базах данных таблицы связываются друг с другом посредством совпадающих значений ключевых полей. Ключевым полем может быть практически любое поле в таблице. Ключ может быть первичным (primary) или внешним (foreign).
Первичный ключ однозначно определяет запись в таблице, в то время как внешний ключ используется для связи с первичным ключом другой таблицы.
Индекс Данные запоминаются в таблице в том порядке, в котором они вводятся пользователем. Это, так называемый, физический порядок следования записей. Однако, часто требуется представить данные в другом, отличном от физического, порядке. Например может потребоваться просмотреть данные об станках, упорядоченные по размеру рабочей зоны. Кроме того, часто необходимо найти в большом объеме информации запись, удовлетворяющую определенному критерию. Простой перебор записей при поиске в большой таблице может потребовать достаточно много времени и поэтому будет неэффективным. Эффективным средством решения этих задач является использование индексов.
Индекс представляет собой таблицу, которая содержит ключевые значения для каждой записи в таблице данных и записанные в порядке, требуемом для пользователя. Ключевые значения определяются на основе одного или нескольких полей таблицы.
Каждая таблица может иметь несколько различных индексов, каждый из которых определяет свой собственный порядок следования записей.
При разработке приложений, работающих с базами данных, наиболее широко используются простые индексы. Простые индексы используют значения одного поля таблицы.
SQL-запросы
SQL (англ. Structured Query Language — «язык структурированных запросов») – универсальный компьютерный язык, применяемый для создания, модификации и управления данными в реляционных базах данных.
Поскольку к началу 1980-х годов существовало несколько вариантов СУБД от разных производителей, причём каждый из них обладал собственной реализацией языка запросов, было принято решение разработать стандарт языка, который будет гарантировать переносимость ПО с одной СУБД на другую (при условии, что они будут поддерживать этот стандарт).
Операторы SQL делятся на:
- операторы определения данных
-- CREATE создает объект БД (саму базу, таблицу, представление, пользователя и т. д.)
-- ALTER изменяет объект
-- DROP удаляет объект
- операторы манипуляции данными
-- SELECT считывает данные, удовлетворяющие заданным условиям
-- INSERT добавляет новые данные
-- UPDATE изменяет существующие данные
-- DELETE удаляет данные
- операторы определения доступа к данным
-- GRANT предоставляет пользователю (группе) разрешения на определенные операции с объектом
-- REVOKE отзывает ранее выданные разрешения
-- DENY задает запрет, имеющий приоритет над разрешением
- операторы управления транзакциями (Транза́кция (англ. transaction) — группа последовательных операций с базой данных, которая представляет собой логическую единицу работы с данными. Транзакция может быть выполнена либо целиком и успешно, соблюдая целостность данных и независимо от параллельно идущих других транзакций, либо не выполнена вообще и тогда она не должна произвести никакого эффекта.)
-- COMMIT применяет транзакцию.
-- ROLLBACK откатывает все изменения, сделанные в контексте текущей транзакции.
-- SAVEPOINT делит транзакцию на более мелкие участки.
Преимущества
- Независимость от конкретной СУБД
- Наличие стандартов
- Декларативность - с помощью SQL программист описывает только то, какие данные нужно извлечь или модифицировать. То, каким образом это сделать, решает СУБД непосредственно при обработке SQL-запроса.
Недостатки
- Несоответствие реляционной модели данных – язык допускает такие фаты, как повторяющиеся строки, неопределённые значения (nulls), колонки без имени и дублирующиеся имена колонок
- Сложность - хотя SQL и задумывался как средство работы конечного пользователя, в конце концов он стал настолько сложным, что превратился в инструмент программиста.
- Отступления от стандартов
- Сложность работы с иерархическими структурами - ранее диалекты SQL большинства СУБД не предлагали способа манипуляции древовидными структурами. Некоторые поставщики СУБД предлагали свои решения (например, Oracle использует выражение CONNECT BY).
Поскольку SQL не является привычным процедурным языком программирования (то есть не предоставляет средств для построения циклов, ветвлений и т. д.), вводимые разными производителями расширения касались в первую очередь процедурных расширений. Поэтому появились диалекты языка: InterBase, IBM DB2, MS SQL, MySQL, Oracle, PostgreSQL.
Запросы
Запросы. В базах данных начального уровня SQL-запросы недоступны пользователю. Вместо них применятся построители запросов и скриптов.
Бывают запросы
- на добавление,
- на удаление,
- на обновление,
- на создание таблицы (выборка).
Практически все запросы параметрические.То есть имеют Условие отбора запроса.
Перекрестные запросы — это запросы, в которых происходит статистическая обработка данных, результаты которой выводятся в виде таблицы, очень похожей на сводную таблицу Excel. Перекрестные запросы обладают следующими достоинствами:
- возможностью обработки значительного объема данных и вывода их в формате, который очень хорошо подходит для автоматического создания графиков и диаграмм;
- простотой и скоростью разработки сложных запросов с несколькими уровнями детализации.
В качестве примера сформируем два перекрестных запроса к базе данных "Инструмент режущий" для вывода ежемесячных потребностей в различных видах инструмента.
Интерфейс
Обычно не входит в саму систему управления базами данных. Он пишется отдельно под каждую конкретную задачу. Это можно сравнить, что на одной и той же системе управления сайтами, создаются различные сайты с различным дизайном.
Дата добавления: 2017-09-19; просмотров: 356;