Многомерные массивы.
Элементами массива могут являться также массивы. Такой массив называется двухмерным. Если элементами 2-хмерного массива являются массивы то получим 3-х мерный массив и т. д.
Многомерные массивызадаются указанием каждого измерения в квадратных скобках
тип_элементов имя_массива[размерность1][размерность2]…[ размерностьn];
Hапример, оператор
int matr [6][8]:
задает описание двумерного массива из 6 строк и 8 столбцов. В памяти такой массив располагается в последовательных ячейках построчно. Многомерные массивы размещаются так, что при переходе к следующему элементу быстрее всего изменяется последний индекс. Для доступа к элементу многомерного массива указываются все его индексы, например, matr[i][j]..или более экзотическим способом: *(matr[i ]+j) пли *(*(matr+i )*j). Это возможно, поскольку rnatr[i] является адресом начала i-й строки массива.
При инициализации многомерного массива он представляется либо как массив из массивов, при этом каждый массив заключается в свои фигурные скобки (в этом случае размерности при описании можно не указывать), либо задается общий список элементов в том порядке, в котором элементы располагаются в памяти:
int mass2 [][]={ {1, 1}, (0, 2}, (1, 0} };
int mass2 [3][2]={1, 1, 0, 2, 1, 0};
Пример. Программа определяет в целочисленной матрице номер строки, которая содержит наибольшее количество элементов, равных нулю.
#include <stdio.h>
int main()
{
const int nstr = 4, nstb = 5; // размерности массива int b[nstr][nstb]; // описание массива
int i, j;
for (i = 0; i<nstr; i++) //BBOD массива
for (j = 0; j<nstb; j++)
scanf(“%d", &b[i][j]);
int istr = -1, MaxKol = 0;
for (i = 0;-i<nstr; i++)
{ // просмотр массива по строкам
int Коl = 0;
for (j = 0; j<nstb; j++)
if (b[i][j] == 0) Kol++;
if (Kol > MaxKol)
{istr = i;
MaxKol = Kol;
}
}
printf(" Исходный массив:\n");
for (i = 0; i<nstr; i++){
for (j = 0; j<nstb; j++)printf("%d ", b[i][j]); printf("\n");}
If (istr == -1) printf(“Отрицат. элементов нет");
else printf("Номер строки: %d", istr);
return 0;
}
Номер искомой строки хранится в переменной istr, количество нулевых элементов в текущей (i-й) строке - в переменной Kol, максимальное количество нулевых элементов - в переменной MaxKol. Массив просматривается по строкам, в каждой из них подсчитывается количество нулевых элементов (обратите внимание, что переменная Kol обнуляется перед просмотром каждой строки). Наибольшее количество и номер соответствующей строки запоминаются.
Для создания динамического многомерного массива необходимо указать в операции new все его размерности (самая левая размерность может быть переменной), например:
int nstr = 5;
int ** m = (int **) new int [nstr][10]:
Более универсальный и безопасный способ выделения памяти под двумерный массив" когда обе его размерности задаются на этапе выполнения программы, приведен ниже:
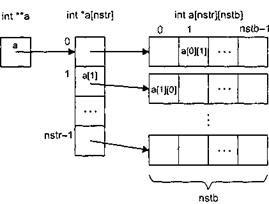
int nstr, nstb;
cout <<" Введите количество строк и столбцов :"; cin >>nstr>> nstb; int **a = new int *[nstr]; // 1 for(int i = 0; i<nstn; i++) // 2 a[i] = new int [nstb]; // 3
В операторе 1 объявляется переменная типа «указатель на указатель на int» и выделяется память под массив указателей на строки массива (количество строк -nstr) В операторе 2 организуется цикл для выделения памяти под каждую строку массива. В операторе 3 каждому элементу массива указателей на строки присваивается адрес начала участка памяти, выделенного под строку двумерного массива. Каждая строка состоит из nstb элементов типа Int (рис. 1.10).
Освобождение памяти из-под массива с любым количеством измерений выполняется с помощью операции delete []. Указатель на константу удалить нельзя.
ПРИМЕЧАНИЕ ————————————————————————————————————————
Для правильной интерпретации объявлений полезно запомнить мнемоническое правило: «суффикс прежде префикса». Если при описании переменной используются одновременно префикс * (указатель) и суффикс [] (массив), то переменная интерпретируется как массив указателей, а не указатель на массив: int *р[10]; — массив из 10 указателей на int.
Тема 5. Язык программирования С/С++. Определяемые пользователем типы, структуры, объединения и поля.
Типы данных, определяемые пользователем
В реальных задачах информация, которую требуется обрабатывать, может иметь достаточно сложную структуру. Для ее адекватного представления используются типы данных, построенные на основе простых типов данных, массивов и указателей. Язык C++ позволяет программисту определять свои типы данных и правила работы с ними. Исторически для таких типов сложилось наименование, ** вынесенное в название главы, хотя правильнее было бы назвать их типами, определяемыми программистом.
Переименование типов (typedef)
Для того чтобы сделать программу более ясной, можно задать типу новое имя с помощью ключевого слова typedef:
typedef тип новое_имя [ размерность ];
В данном случае квадратные скобки являются элементом синтаксиса. Размерность может отсутствовать. Примеры:
typedef unsigned int UINT;
typedef char Msg[lOO]:
typedef struct{
char fio[30];
int date, code;
double salary:} Worker:
Введенное таким образом имя можно использовать таким же образом, как и имена стандартных типов:
UINT 1. j, // две переменных типа unsigned
int Msg str[10]; // массив из 10 строк по 100 символов Morker
stuff[100]; // массив из 100 структур
Кроме задания типам с длинными описаниями более коротких псевдонимов, typedef используется для облегчения переносимости программ: если машинно-зависимые типы объявить с помощью операторов typedef, при переносе программы потребуется внести изменения только в эти операторы.
Перечисления
Перечисления – это набор именованных целочисленных констант, определяющий все допустимые значения, которые может принимать переменная. Перечисления можно встретить в повседневной жизни. Например, в качестве перечислений можно использовать дни недели:
понедельник, вторник, среда, четверг, пятница, суббота, воскресенье
Объявление перечисления начинается с ключевого слова enum, которое указывает на начало перечисления. Стандартный формат перечисления следующий:
enum [имя_типа_перечисления] {список_перечислений}
[список_переменных];
Как имя_типа_перечисления, так и список_переменных необязательны, но один из них обязательно должен присутствовать. Список_перечислений – это разделенный запятыми список идентификаторов. Имя_типа_перечисления используется для объявления переменных данного типа. Следующий фрагмент определяет перечисление week и объявляет переменную day этого типа:
enum week{monday, tuesday, wedday, thursday,
friday, saturday, sunday};
enum day week;
Имея данное объявление и определение, следующий операторы совершенно корректны:
day = wedday;
if(day == Friday) printf(“Это пятница”);
Важно понять, что в перечислениях каждому символу ставится в соответствие целочисленное значение и поэтому перечисления можно использовать в любых выражениях. Например:
printf(“Переменная friday имеет значение - %d”, friday);
Если явно не проводить инициализацию, значение первого символа перечисления будет 0, второго – 1 и так далее.
Можно определить значения одного или нескольких символов, используя инициализатор. Это делается путем помещения за символом знака равенства целочисленного значения. При использовании инициализатора, символы, следующие за инициализационным значением, получают значение большее, чем указанное перед этим. Например, в следующем объявлении
enum week{monday, tuesday, wedday, thursday=100,
friday, saturday, sunday};
символы получат следующие значения:
monday 0
tuesday 1
wedday 2
thursday 100
friday 101
saturday 102
sunday 103
Использование элементов перечисления должно подчиняться следующим правилам:
1. Переменная может содержать повторяющиеся значения.
2. Идентификаторы в списке перечисления должны быть отличны от всех других идентификаторов в той же области видимости, включая имена обычных переменных и идентификаторы из других списков перечислений.
3. Имена типов перечислений должны быть отличны от других имен типов перечислений, структур и смесей в этой же области видимости.
4. Значение может следовать за последним элементом списка перечисления.
Невозможен прямой ввод или вывод символов перечислений. Следующий фрагмент кода не работает.
day = sunday;
printf(“%s”, day);
Надо помнить, что символ sunday – это просто имя для целого числа, а не строка. Следовательно, невозможно с помощью printf() вывести строку «sunday», используя значение в day. Аналогично нельзя сообщить значение переменной перечисления, используя строковый эквивалент. Таким образом следующий код не работает:
day = “wedday”;
На самом деле, создание кода для ввода и вывода символов перечислений – это довольно скучное занятие. Например, следующий код необходим для вывода состояния day с помощью слов:
switch (day) {
case Monday: printf(“Monday”);
break;
case Tuesday: printf(“Tuesday”);
break;
case wedday: printf(“wedday”);
break;
case Thursday: printf(“Thursday”);
break;
case Friday: printf(“Friday”);
break;
case Saturday: printf(“Saturday”);
break;
case Sunday: printf(“Sunday”);
}
Поскольку значения перечислений должны преобразовываться вручную к строкам, которые могут читать люди, они наиболее полезны в подпрограммах, не выполняющих такие преобразования.
Структуры (struct)
Cтруктуры - это составной объект, в который входят элементы любых типов, за исключением функций. В отличие от массива, все элементы которого однотипны, структура может содержать элементы разных типов. В языке C++ структура является видом класса и обладает всеми его свойствами, но во многих случаях достаточно использовать структуры так, как они определены в языке С:
struct [ имя_типа ]
{ тип_1 элемент_1;
тип_2 элемент_2;
тип_п элемент_п;
} [ список_описателей ];
Элементы структуры называются полями структуры и могут иметь любой тип, кроме типа этой же структуры, но могут быть указателями на него. Если отсутствует имя типа, должен быть указан список описателей переменных, указателей или массивов. В этом случае описание структуры служит определением элементов этого списка:
// Определение массива структур и указателя на структуру:
struct { int year;
char moth;
int day; } date, date2
;Если список отсутствует, описание структуры определяет новый тип, имя которого можно использовать в дальнейшем наряду со стандартными типами, например:
struct student{ // описание нового типа Worker
char fio[30];
long int num_zac;
double sr_bal;
}; // описание заканчивается точкой с запятой
// определение массива типа student и указателя на тип student.
student gr[30], *p:
Для инициализации структуры значения ее элементов перечисляют в фигурных скобках в порядке их описания:
struct {
char fio[30];
long int num_zac;
double sr_bal;
}student1 = {"Necto", 011999,3.66}:
При инициализации массивов структур следует заключать в фигурные скобки каждый элемент массива (учитывая, что многомерный массив — это массив массивов):
struct complех{ float real, im;
} compl [2][3] = {
{{1. 1}, {1, 1), {1. 1}},// строка 1, то есть массив comp1[0]
{{2, 2}, {2. 2}, {2, 2}} // строка 2, то есть массив compi[1]
};
Для переменных одного и того же структурного типа определена операция присваивания, при этом происходит поэлементное копирование. Структуру можно передавать в функцию и возвращать в качестве значения функции. Размер структуры не обязательно равен сумме размеров ее элементов, поскольку они могут быть выровнены по границам слова.
Доступ к полям структуры выполняется с помощью операций выбора . (точка) при обращении к полю через имя структуры и -> при обращении через указатель, например:
student student 1, gr[30], *p;
student .fio = "Страусенке":
gr[8] .sr_bal=5;
p->num_zac = 012001;
Если элементом структуры является другая структура, то доступ к ее элементам выполняется через две операции выбора:
struct A {int a, double х;};
struct В {A a, double х,} х[2];
х[0] .а. а = 1;
х[1]. х = 0.1;
Как видно из примера, поля разных структур могут иметь одинаковые имена, поскольку у них разная область видимости. Более того, можно объявлять в одной области видимости структуру и другой объект (например, переменную или массив) с одинаковыми именами, если при определении структурной переменной использовать слово struct, но не советую это делать — запутать компилятор труднее, чем себя.
Описать структуру с именем AVTO, содержащую поля:
§ FAM – фамилия и инициалы владельца автомобиля;
§ MARKA – марка автомобиля;
§ NOMER – номер автомобиля.
Написать программу, выполняющую следующие действия:
§ ввод с клавиатуры данных в массив GAI, состоящий из шести элементов типа AVTO; записи должны быть упорядочены в алфавитном порядке по фамилиям и именам владельцев;
§ вывод на экран информации об владельцах автомобиля, марка которого вводится которого вводится с клавиатуры;
§ если таковых авторов нет, то на экран дисплея вывести соответствующее сообщение.
Программа решения задачи будет иметь вид:
#include <iostream.h>
#include <stdio.h>
#include <string.h>
#include <conio.h>
#include <windows.h>
char buf[256];
char *Rus(char *text)
{CharToOem(text,buf);
return buf;}
struct avto {
char fam[25];
char marka[20];
char nomer[10];};
void output_gai(avto *,int );
void main(void)
{ int i,n;
bool flag;
cout<<Rus("Введите количество записей: ");
cin>>n;
avto *gai = new avto[n], temp;
char m[20];
for(i=0;i<n;i++)
{ // Ввод данных
cout<<Rus("Введите фамилию владельца ")<<i+1;
cout<<Rus("-го автомобиля: ");
cin >> gai[i].fam;
cout<<Rus("Введите марку ")<<i+1;
cout<<Rus("-го автомобиля: ");
cin >> gai[i].marka;
cout<<Rus("Введите номер ")<<i+1;
cout<<Rus("-го автомобиля: ");
cin >> gai[i].nomer; }
cout << Rus("Исходные данные до сортировки") << endl;
output_gai(gai,n);
// Сортировка
flag = true;
while(flag)
{ flag = false;
for(i=0;i<n-1;i++)
if(strcmp(gai[i].fam,gai[i+1].fam)>0)
{temp=gai[i];
gai[i]=gai[i+1];
gai[i+1]=temp;
flag = true;
} }
cout << endl<<Rus("После сортировки")<<endl;
output_gai(gai,n);
cout << endl << Rus("Введите марку автомобиля: ");
cin >> m;
cout << endl << Rus("Искомые автомобили") << endl;
flag = true;
for(i=0;i<n;i++)
if(!strcmp(m,gai[i].marka))
{ output_gai(&gai[i],1);
flag = false; }
if(flag)
{cout<<Rus("\nМарки ")<<m;
cout<<Rus("нет в списках");}
delete [] gai;
}
void output_gai( avto *gai, int n)
{ int i;
for(i=0;i<n;i++)
{ cout.setf(ios::left);
cout.width(15);
cout<<gai[i].fam;// *(gai+i)->fam;
cout.width(15);
cout<<gai[i].marka;
cout.setf(ios::right);
cout.width(5);
cout<<gai[i].nomer<<endl;
} }
Объединение подобно структуре, однако в каждый момент времени может использоваться (или другими словами быть ответным) только один из элементов объединения. Тип объединения может задаваться в следующем виде:
union { описание элемента 1; ... описание элемента n; };Главной особенностью объединения является то, что для каждого из объявленных элементов выделяется одна и та же область памяти, т.е. они перекрываются. Хотя доступ к этой области памяти возможен с использованием любого из элементов, элемент для этой цели должен выбираться так, чтобы полученный результат не был бессмысленным.
Доступ к элементам объединения осуществляется тем же способом, что и к структурам. Тег объединения может быть формализован точно так же, как и тег структуры.
Объединение применяется для следующих целей:
- инициализации используемого объекта памяти, если в каждый момент времени только один объект из многих является активным;
- интерпретации основного представления объекта одного типа, как если бы этому объекту был присвоен другой тип.
Память, которая соответствует переменной типа объединения, определяется величиной, необходимой для размещения наиболее длинного элемента объединения. Когда используется элемент меньшей длины, то переменная типа объединения может содержать неиспользуемую память. Все элементы объединения хранятся в одной и той же области памяти, начиная с одного адреса.
Пример:
union { char fio[30]; char adres[80]; int vozrast; int telefon; } inform; union { int ax; char al[2]; } ua;При использовании объекта infor типа union можно обрабатывать только тот элемент который получил значение, т.е. после присвоения значения элементу inform.fio, не имеет смысла обращаться к другим элементам. Объединение ua позволяет получить отдельный доступ к младшему ua.al[0] и к старшему ua.al[1] байтам двухбайтного числа ua.ax .
Битовые поля
Битовые поля — это особый вид полей структуры. Элементом структуры может быть битовое поле, обеспечивающее доступ к отдельным битам памяти. Вне структур битовые поля объявлять нельзя. Нельзя также организовывать массивы битовых полей и нельзя применять к полям операцию определения адреса. В общем случае тип структуры с битовым полем задается в следующем виде:
struct { unsigned идентификатор 1 : длина-поля 1; unsigned идентификатор 2 : длина-поля 2; }длинна - поля задается целым выражением или константой. Эта константа определяет число битов, отведенное соответствующему полю. Поле нулевой длинны обозначает выравнивание на границу следующего слова.
Пример:
struct { unsigned a1 : 1; unsigned a2 : 2; unsigned a3 : 5; unsigned a4 : 2; } prim;Структуры битовых полей могут содержать и знаковые компоненты. Такие компоненты автоматически размещаются на соответствующих границах слов, при этом некоторые биты слов могут оставаться неиспользованными.
Ссылки на поле битов выполняются точно так же, как и компоненты общих структур. Само же битовое поле рассматривается как целое число, максимальное значение которого определяется длиной поля.
Тема 6. Язык программирования С/С++. Функции.
Функции
При решении сложной задачи мы разбиваем ее на части. В C++ задача может быть разделена на более простые и обозримые подзадачи, которые оформляются в виде функций, после чего программу можно рассматривать в более укрупненном виде — на уровне взаимодействия функций. Использование функций является первым шагом к повышению степени абстракции программы и ведет к упрощению ее структуры.
Разделение программы на функции позволяет также избежать избыточности кода, поскольку функцию записывают один раз, а вызывать ее на выполнение можно многократно из разных точек программы. Процесс отладки программы, содержащей функции, можно лучше структурировать. Часто используемые функции можно помещать в библиотеки. Таким образом создаются более простые в отладке и сопровождении программы.
Следующим шагом в повышении уровня абстракции программы является группировка функций и связанных с ними данных в отдельные файлы (модули), компилируемые раздельно. Получившиеся в результате компиляции объектные модули объединяются в исполняемую программу с помощью компоновщика. Разбиение на модули уменьшает время перекомпиляции и облегчает процесс отладки, скрывая несущественные детали за интерфейсом модуля и позволяя отлаживать программу по частям (или разными программистами).
Модуль содержит данные и функции их обработки. Другим модулям нежелательно иметь собственные средства обработки этих данных, они должны пользоваться для этого функциями первого модуля. Чем более независимы модули, тем легче отлаживать программу
Дата добавления: 2017-01-13; просмотров: 1249;