Сеть с топологией кольцо
В отличие от ограниченного конвейерного функционирования векторного процессора, матричный процессор (синоним для большинства SIMD-машин) может быть значительно более гибким. Обрабатывающие элементы таких процессоров - это универсальные программируемые ЭВМ, так что задача, решаемая параллельно, может быть достаточно сложной и содержать ветвления. Обычное проявление этой вычислительной модели в исходной программе примерно такое же, как и в случае векторных операций: циклы на элементах массива, в которых значения, вырабатываемые на одной итерации цикла, не используются на другой итерации цикла.
Модели вычислений на векторных и матричных ЭВМ настолько схожи, что эти ЭВМ часто обсуждаются как эквивалентные.
3) Машины типа MIMD.
MIMD компьютер имеет N процессоров, независимо исполняющих N потоков команд и обрабатывающих N потоков данных. Каждый процессор функционирует под управлением собственного потока команд, то есть MIMD компьютер может параллельно выполнять совершенно разные программы.

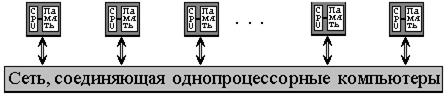
MIMD архитектуры далее классифицируются в зависимости от физической организации памяти, то есть имеет ли процессор свою собственную локальную память и обращается к другим блокам памяти, используя коммутирующую сеть, или коммутирующая сеть подсоединяет все процессоры к общедоступной памяти. Исходя из организации памяти, различают следующие типы параллельных архитектур:
• Компьютеры с распределенной памятью (Distributed memory)
Процессор может обращаться к локальной памяти, может посылать и получать сообщения, передаваемые по сети, соединяющей процессоры. Сообщения используются для осуществления связи между процессорами или, что эквивалентно, для чтения и записи удаленных блоков памяти. В идеализированной сети стоимость посылки сообщения между двумя узлами сети не зависит как от расположения обоих узлов, так и от трафика сети, но зависит от длины сообщения.
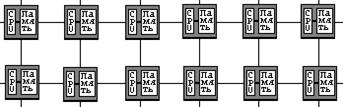
• Компьютеры с общей (разделяемой) памятью (True shared memory)
Все процессоры совместно обращаются к общей памяти, обычно, через шину или иерархию шин. В идеализированной PRAM (Parallel Random Access Machine - параллельная машина с произвольным доступом) модели, часто используемой в теоретических исследованиях параллельных алгоритмов, любой процессор может обращаться к любой ячейке памяти за одно и то же время. На практике масштабируемость этой архитектуры обычно приводит к некоторой форме иерархии памяти. Частота обращений к общей памяти может быть уменьшена за счет сохранения копий часто используемых данных в кэш-памяти, связанной с каждым процессором. Доступ к этому кэш-памяти намного быстрее, чем непосредственно доступ к общей памяти.
• Компьютеры с виртуальной общей (разделяемой) памятью (Virtual shared memory)
Общая память как таковая отсутствует. Каждый процессор имеет собственную локальную память и может обращаться к локальной памяти других процессоров, используя "глобальный адрес". Если "глобальный адрес" указывает не на локальную память, то доступ к памяти реализуется с помощью сообщений, пересылаемых по коммуникационной сети.
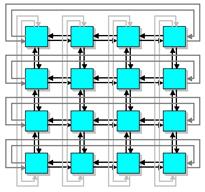
MIMD архитектуры с распределенной памятью можно так же классифицировать по пропускной способности коммутирующей сети. Например, в архитектуре, в которой пары из процессора и модуля памяти (процессорный элемент) соединены сетью с топологий решетка, каждый процессор имеет одно и то же число подключений к сети вне зависимости от числа процессоров компьютера. Общая пропускная способность такой сети растет линейно относительно числа процессоров. В топологии клика каждый процессор должен быть соединен со всеми другими процессорами. С другой стороны в архитектуре, имеющей сеть с топологий гиперкуб, число соединений процессора с сетью является логарифмической функцией от числа процессоров, а пропускная способность сети растет быстрее, чем линейно по отношению к числу процессоров.
Дата добавления: 2016-12-26; просмотров: 895;