Повышение производительности процессоров
Конвейеризация
Выполнение команды состоит из нескольких этапов (цикл команды):
- выборка команды (ВК);
- декодирование кода операции (ДК);
- формирование адресов операндов и выборка операндов из памяти (ВО);
- исполнение команды (ИК);
- запись результата (ЗР).
Поручив реализацию каждого этапа отдельному устройству и соединив их последовательно, получим конвейер команд.

Рис. 4.8. Конвейер команд с пятью ступенями
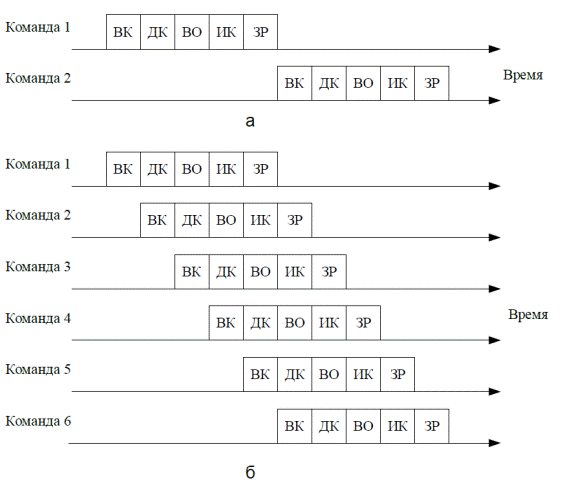
Рис. 4.9. Временные диаграммы:
а – без конвейера команд; б – с конвейером команд
В случае конвейера с пятью ступенями скорость выполнения команд увеличивается теоретически в 3 раза (пример – Intel 486).
Предсказание ветвлений
Полученное в примере рис. 4.9 увеличение скорости выполнения в три раза характеризует лишь потенциальную производительность конвейера команд. На практике в силу возникающих в конвейере конфликтных ситуаций достичь такой производительности не удается. Конфликтные ситуации в конвейере принято обозначать термином риск (hazard), а обусловлены они могут быть тремя причинами:
· попыткой нескольких команд одновременно обратиться к одному и тому же ресурсу ВМ (структурный риск);
· взаимосвязью команд по данным (риск по данным);
· неоднозначностью при выборке следующей команды в случае команд перехода (риск по управлению).

Рис. 4.10. Влияние условного перехода на работу конвейера команд
Пусть команда 3 – это условный переход к команде 7 при выполнении некоторого условия, иначе переход на команду 4. До завершения этапа исполнения команды 3 невозможно определить, какая из команд (4-я или 7-я) должна выполняться следующей, поэтому конвейер просто загружает следующую команду в последовательности (команду 4) и продолжает свою работу. В варианте, показанном на рис. 4.9, условных переходов не происходит и получена максимально возможная производительность. На рис. 4.10 переход имеет место, о чем неизвестно до 6-го такта. В этой точке конвейер должен быть очищен от ненужных команд, выполнявшихся до дан- ного момента. Лишь на 7-м такте на конвейер поступает нужная команда 7, из-за чего в течение тактов от 4 до 6 не будут выполняться нужные команды. Это и есть издержки из-за невозможности предвидения исхода команды условного перехода.
Предсказание ветвлений позволяет продолжать выборку и декодирование потока инструкций после выборки инструкции ветвления (условного перехода), не дожидаясь проверки самого условия. Предсказание ветвлений направляет поток выборки и декодирования по одной из ветвей. Статический метод предсказания работает по схеме, заложенной в процессор, считая, что переходы по одним условиям, вероятнее всего, произойдут, а по другим – нет. Динамическое предсказание опирается на предысторию вычислительного процесса – для каждого конкретного случая перехода накапливается статистика поведения, и переход предсказывается, основываясь именно на ней.
В современных процессорах обеспечивается точность предсказания 90–97%.
Суперскалярные процессоры
Суперскалярный процессор – это процессор, содержащий несколько операционных устройств.
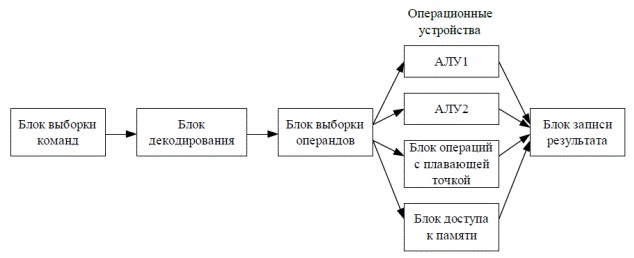
Рис. 4.11. Суперскалярный процессор с четырьмя ОУ
В суперскалярных процессорах блок выборки команд, в отличие от простого конвейера, считывает более одной команды.
Каждый блок суперскалярного процессора может являться конвейером. Например, сумма ступеней всех блоков процессора Intel Pentium 4 равна 20.
Архитектуры CISC и RISC
По составу системы команд микропроцессоры делятся на две группы:
· CISC (Complex Instruction Set Computer – компьютер с полным набором команд).
· RISC (Reduced Instruction Set Computer – компьютер с сокращенным набором команд).
До 80-х годов все компьютеры имели архитектуру CISC. Для нее характерно:
- большое число разнообразных команд (несколько сотен);
- неодинаковая длина команд;
- сложное устройство управления;
- малое число регистров (несколько десятков);
- медленный конвейер.
В начале 80-х годов начали разрабатываться первые компьютеры класса RISC. Их особенности:
- небольшое число команд (около 100);
- одинаковая длина команд, равная слову;
- простое устройство управления;
- большое число регистров (до 500);
- быстрый конвейер.
В компьютерах RISC сложные действия, для которых в CISC имелись специальные команды, разбивались на несколько простых быстрых команд.
Пример RISC-процессоров: Ultra SPARC (Sun Microsystems), Alpha (DEC, c 1998 года – Compaq, затем Hewlett-Packard), PowerPC (IBM).
В общем случае, архитектура RISC является более производительной, чем CISC. Однако повсеместного перехода на архитектуру RISC не произошло по двум причинам. Во-первых, было уже вложено много денег в архитектуру CISC и в программное обеспечение для нее (первые процессоры Intel). Во-вторых, в процессорах CISC (начиная с AMD-K5, а затем и в процессорах Intel) стали применять RISC-технологии.
Кэш-память
В качестве основной памяти в большинстве ВМ служат микросхемы динамических ОЗУ, на порядок уступающие по быстродействию центральному процессору. В результате процессор вынужден простаивать несколько тактов, пока информация из памяти установится на шине данных ВМ. Если основную память выполнить на быстрых микросхемах статической памяти, стоимость ВМ возрастет весьма существенно. Экономически приемлемое решение этой проблемы было предложено М. Уилксом в 1965 году. Между основной памятью и процессором размещается небольшая, но быстродействующая буферная память. В процессе работы такой системы в буферную память копируются те участки основной памяти, к которым производится обращение со стороны процессора. Выигрыш достигается за счет принципа локальности.
Принцип заключается в том, что при выполнении программы с высокой вероятностью адрес следующей команды либо следует непосредственно за адресом текущей команды, либо находится вблизи него. Принцип локальности часто облекают в численную форму и представляют в виде так называемого правила «90/10»: 90% времени работы программы связано с доступом к 10% адресного пространства этой программы.
Термин кэш произошел от английского слова cache – тайник, поскольку такая память обычно скрыта от программиста в том смысле, что он не может ее адресовать. Впервые кэш-системы появились в машинах модели 85 семейства IBM 360.
Алгоритм работы с кэш-памятью
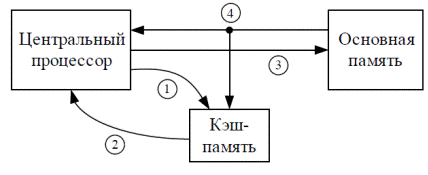
Рис. 4.12. Алгоритм работы с кэш-памятью
Когда процессор пытается прочитать слово из основной памяти, сначала осуществляется поиск копии этого слова в кэше (1). Если такая копия существует, обращение к основной памяти не производится, а в процессор передается слово, извлеченное из кэш-памяти (2). Данную ситуа- цию принято называть успешным обращением, или попаданием (hit). При отсутствии слова в кэше, то есть при неуспешном обращении – промахе (miss) – требуемое слово запрашивается в основной памяти (3). При передаче слова в процессор из основной памяти, одновременно из основной памяти в кэш-память пересылается блок данных, содержащий это слово (4).
Смешанная и разделенная кэш-память
Когда в микропроцессорах впервые стали применять внутреннюю кэш-память, ее обычно использовали как для команд, так и для данных. Такую кэш-память принято называть смешанной, а соответствующую архитектуру – Принстонской (Princeton architecture), по названию университета, где разрабатывались ВМ с единой памятью для команд и данных, то есть соответствующие классической архитектуре фон Неймана. Сравнительно недавно стало обычным разделять кэш-память на две – отдельно для команд и отдельно для данных. Подобная архитектура получила название Гарвардской (Harvard architecture), поскольку именно в Гарвардском университете был создан компьютер «Марк-1» (1950 год), имевший раздельные ЗУ для команд и данных.
Смешанная кэш-память обладает тем преимуществом, что при заданной емкости ей свойственна более высокая вероятность попаданий по сравнению с разделенной, поскольку в ней оптимальный баланс между командами и данными устанавливается автоматически. Так, если в выполняемом фрагменте программы обращения к памяти связаны в основном с выборкой команд, а доля обращений к данным относительно мала, кэш-память имеет тенденцию насыщаться командами, и наоборот.
С другой стороны, при раздельной кэш-памяти выборка команд и данных может производиться одновременно, при этом исключаются возможные конфликты. Последнее обстоятельство существенно в системах, использующих конвейеризацию команд, где процессор извлекает команды с опережением и заполняет ими буфер или конвейер.
Уровни кэш-памяти
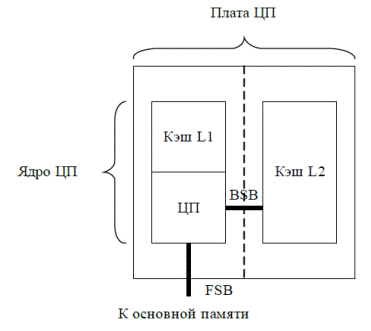
Рис. 4.13. Плата центрального процессора
· Кэш-память первого уровня (L1) – располагается на одном кристалле с МП (в ядре МП). Объем: 8–128 кб. Делится на кэш для инструкций и кэш для данных.
· Кэш-память второго уровня (L2) – располагается на плате МП (в одном корпусе с МП). Объем: 128–2048 кб.
· Кэш-память третьего уровня (L3) – при наличии кэш L2 располагается на системной плате (процессоры AMD, Pentium 4). Объем до 2 Мб.
При доступе к памяти МП сначала обращается к кэш-памяти первого уровня. В случае промаха производится обращение к кэш-памяти второго уровня. Если информация отсутствует и в L2, выполняется обращение к основной памяти и соответствующий блок заносится сначала в L2, а затем и в L1.
Для ускорения обмена информацией между МП и кэш-памятью L2 между ними часто вводят специальную шину – BSB, Back Side Bus, шину заднего плана, в отличие от FSB, Front Side Bus, шины переднего плана, связывающей МП с основной памятью.
В современных ПК часто используется кэш-память между внешними запоминающими устройствами и основной памятью. Эта кэш-память создается либо в основной памяти, либо на самом накопителе. Её объем 1–8 Мб.
Виртуальная память
Для большинства типичных применений ВМ характерна ситуация, когда размещение всей программы в ОЗУ невозможно из-за ее большого размера. В этом, однако, и нет принципиальной необходимости, поскольку в каждый момент времени «внимание» машины концентрируется на определенных сравнительно небольших участках программы. Таким образом, в ОЗУ достаточно хранить только используемые в данный период части программ, а остальные части могут располагаться на внешних ЗУ. Сложность подобного подхода в том, что процессы обращения к ОЗУ и ВЗУ существенно различаются, и это усложняет задачу программиста. Выходом из такой ситуации было появление в 1959 году идеи виртуализации памяти, под которой понимается метод автоматического управления памятью, при котором программисту кажется, что он имеет дело с единой памятью большой емкости и высокого быстродействия. Эту память называют виртуальной (кажущейся) памятью.
Виртуальная память представляет собой единое адресное пространство, в котором физическая ограниченность емкости основной памяти скрыта от программиста. Реально существующую основную память называют физической, а ее адреса – физическими, логическую память – виртуальной, а ее адреса – виртуальными (логическими). Соответствие между физическими и виртуальными адресами устанавливается совместно аппаратными средствами ЭВМ и ее операционной системой. Обычно виртуальное адресное пространство размещается во внешней памяти, например на магнитных дисках. Часть этого пространства, необходимая для выполнения программ в данный момент, копируется в основной памяти.
Например, процессоры Pentium поддерживают 4 Гб физической памяти (разрядность шины адреса – 32 бита) и 64 Тб виртуальной памяти.
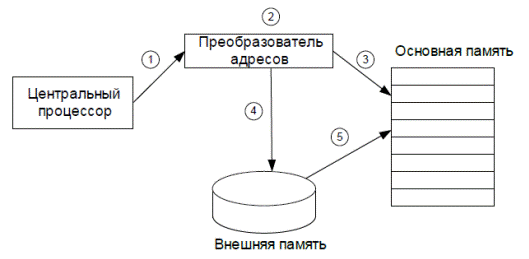
Рис. 4.14. Доступ к данным по виртуальному адресу
Центральный процессор обращается к ячейке памяти, указав ее виртуальный адрес (1). Этот адрес поступает в преобразователь адресов (2) с целью получения из него физического адреса ячейки в основной памяти (3). Если преобразователь обнаруживает, что ячейка памяти отсутствует в основной памяти (произошел промах), то нужная ячейка считывается из внешней памяти и заносится в основную память (4, 5).
4.5.Прерывания
Практически во всех ВМ предусмотрены средства, благодаря которым модули ввода/вывода (и не только они) могут прервать выполнение текущей программы для внеочередного выполнения другой программы с последующим возвратом к прерванной.
Прерывания изменяют нормальное выполнение программы для обработки внешних событий или ошибок.
Первоначально прерывания были введены для повышения эффективности вычислений при работе с медленными ПУ. Положим, что процессор пересылает данные на принтер, используя стандартный цикл команды. После каждой операции записи процессор будет вынужден сделать паузу, в ожидании подтверждения от принтера об обработке символа. Длительность этой паузы может составлять сотни и тысячи циклов команды. Ясно, что такое использование процессора очень неэффективно. В случае прерываний, пока протекает операция ввода/вывода, процессор способен выполнять другие команды.
В упрощенном виде процедуру прерывания можно описать следующим образом.
Объект, требующий внеочередного обслуживания, выставляет на соответствующем входе процессора сигнал запроса прерывания. Перед переходом к очередному циклу команды процессор проверяет этот вход на наличие запроса. Обнаружив запрос, процессор запоминает в стеке информацию, необходимую для продолжения нормальной работы после возврата из прерывания (содержимое счетчика команд, регистров, флаги), и переходит к выполнению программы обработки прерывания (обработчика прерывания). По завершении обработки прерывания процессор восстанавливает состояние прерванного процесса, используя запомненную информацию, и продолжает вычисления.
Описанный процесс иллюстрируется следующим рисунком.
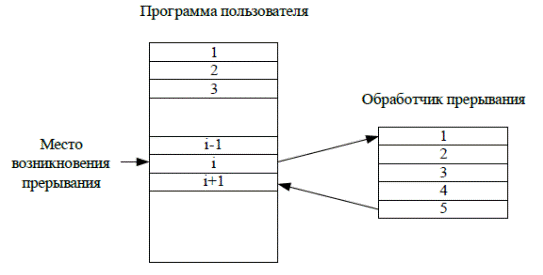
Рис. 4.15. Передача управления при прерывании
Различают четыре источника прерываний:
1. Внутренние прерывания (исключения) процессора – деление на ноль, переполнение, неопределенный код операции, ошибка стека, ошибка сопроцессора и др.
2. Немаскируемые внешние прерывания – фатальные аппаратные ошибки, ошибки памяти, шин, сбои питания.
3. Маскируемые внешние прерывания обрабатывают обмен информацией с внешними устройствами.
4. Программные прерывания – специфический вызов процедур BIOS и операционной системы.
Дата добавления: 2016-12-26; просмотров: 1416;