Представление текстовой информации
Вы уже знаете, как можно кодировать числа. Не возникает никаких проблем и при кодировании любой другой информации, представимой с помощью ограниченного набора символов - алфавита. Для этого достаточно пронумеровать все знаки этого алфавита и затем записывать в память компьютера (и, естественно, обрабатывать) соответствующие номера.
Текст - линейная последовательность символов. Промежутки между отдельными словами, строками, абзацами - тоже некие специальные символы. Каждому символу ставится в соответствие конкретный двоичный код. Соответствие между символом и его кодом, вообще говоря, может быть выбрано совершенно произвольно. Однако на практике необходимо иметь возможность прочесть на одном компьютере текст, созданный на другом. Поэтому таблицы кодировок стараются стандартизовать.
Кодовые таблицы - списки всех возможных при записи текстов символов и соответствующих им двоичных кодов.
Практически все использующиеся сейчас таблицы основаны на "американском стандартном коде обмена информацией" ASCII. Этот стандарт определяет значения для нижней половины кодовой таблицы - первых 127 кодов (32 управляющих кода, основные знаки препинания и арифметические символы, цифры и латинские буквы). В результате, эти символы отображаются верно, какая бы кодировка не использовалась на конкретном компьютере. Хуже обстоит дело с "национальными" символами и "типографскими" знаками препинания. А особенно не повезло языкам, использующим кириллический алфавит (русскому, украинскому, белорусскому, болгарскому и т.д.). Например, для русского языка сейчас широко используются пять таблиц кодировок:
· CP866 (DOS-альтернативная) - на PC-совместимых компьютерах при работе с операционными системами DOS и OS/2, а также в любительской международной сети Фидо (Fidonet).
· CP1251 (Windows-кодировка) - на PC-совместимых при работе под Windows
· KOI-8r - самая старая из использующихся до сих пор кодировок. Применяется на компьютерах, работающих под UNIX, является фактическим стандартом для русских текстов в сети Internet.
· Macintosh Cyrillic - как видно из названия, предназначена для работы со всеми кириллическими языками на Макинтошах.
· ISO-8859. Эта кодировка задумывалась как международный стандарт для кириллических текстов, однако на территории России практически не применяется.
Если мы знаем, как представлен исходный текст и какая таблица используется нашим компьютером, преобразование выполнить очень легко - нужно просто поменять одни коды на другие (по таблице перекодировки). Для этого служат специальные программы - текстовые конверторы. В последнее время появляются конверторы, способные самостоятельно определять исходную кодировку текста и даже умеющие "расшифровывать" текст после нескольких неправильных перекодировок.
В последнее время широкое распространение получила таблица UNICODE (UNIversal CODE), в которой для кодирования 1 символа выделяется 2 байта. Текст занимает в два раза больше места, но можно представить 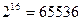 различных символов, включая не только буквы европейских алфавитов (латинского, кириллического, греческого), но и буквы арабского, грузинского и многих других языков и даже большую часть японских и китайских иероглифов.
различных символов, включая не только буквы европейских алфавитов (латинского, кириллического, греческого), но и буквы арабского, грузинского и многих других языков и даже большую часть японских и китайских иероглифов.
В любом печатном тексте можно встретить элементы оформления – особое начертание символов (например, подчеркивание), номера страниц и проч. Эти и другие элементы оформления также нуждаются в кодировке.
Дата добавления: 2016-10-17; просмотров: 1163;