Языки, ориентированные на данные
(по Бен-Ари)
Традиционные языки (Fortran, Pascal, C, C++ и т. д.) создавались для описания процессовых явлений. Их синтаксис и семантика ориентировались на обеспечение возможности описания сложного программного обеспечения (ПО) и его эффективную реализацию. Но для решения задач обработки списков и символьной информации ИИ (искусственного интеллекта) они были мало пригодны. В подобных случаях широко использовались языки: Lisp, Prolog, Snobol, SmallTalk, Forth и др. Их объединяла одна общая черта: каждый язык имел предпочтительную структуру данных и обширный набор команд для нее.
LISP
Lisp, разработанный в 1956 году, был предназначен для исследований в теории вычислений, необходимых при создании искусственного интеллекта. Одна из проблем языка состояла в обилии «диалектов» для его реализации на различных компьютерах. Позже, с целью переноса программ с одного компьютера на другой, был разработан стандарт языка Lisp. В настоящее время популярен «диалект» языка Lisp – CLOS, поддерживающий объектно-ориентированное программирование.
Основная структура данных в языке Lisp – связанный список. Три основные команды языка Lisp – это car (L), cdr (L), которые извлекают начало и конец списка L, и cons (E,L), которая создает новый список из элемента Е из существующего списка L. Используя эти команды, можно определить функции обработки списков, содержащих нечисловые данные. Подобные функции было бы довольно трудно запрограммировать на процедурных языках типа Fortran.
APL
Язык APL используется для описания вычислений. Основные структуры данных в нем – векторы и матрицы, операции над которыми выполняются без циклов. Предположим, что задан вектор:
V = 1_5_10_15_20_25
Работа некоторых операторов языка APL:
+V/ = 76 - сумма элементов;
фV = 25_20_15_10_5_1 - обращение вектора;
2_3pV = 1_5_10 - переопределяет вектор V
15_20_25 как матрицу 2х3
Программы на языке APL очень короткие по сравнению с аналогичными программами на традиционных языках. Применение APL осложнено тем, что в нем имеется большой набор математических символов. Это требует специальных дорогостоящих аппаратных средств.
SNOBOL и ICON
Язык Snobol и его преемник Icon идеально подходят для обработки естественных языков, поскольку их базовой структурой данных является строка. Основные операции в Snobol – сравнение образца со строкой и разложение строки на подстроки. В языке Icon – вычисление выражения, состоящего из строк.
Рассмотрим функцию find (s1,s2) языка Icon, которая ищет вхождения строки s1 в s2, на примере следующей программы:
line:= 0 - инициализировать счетчик строк
while s:= read () { - читать до конца файла
every col:= find (“the”,s) do - генерировать позиции столбца
write (line, “_”, col) - write (line, col) для “the”
}
Эта программа записывает номера строк и столбцов всех вхождений строки “the” в файл. Если команда find не находит ни одного вхождения, то вычисление выражения завершается. Ключевое слово every вызывает повторение вычисления функции до тех пор, пока оно завершается успешно.
Icon предлагает высокий уровень абстрагирования от большей части явных индексных вычислений. Программы оказываются очень короткими по сравнению с обычными языками для числового и системного программирования. Кроме того, в Icon имеется встроенный механизм генерации и отката, который предлагает более развитый уровень абстракций управления.
SETL
SETL предназначен для создания программ высокой степени общности и абстрактности. Основная структура данных в SETL – множество, с помощью которого определяются все другие математические структуры.
Программы на SETL имеют сходство с логическими программами, в которых математические описания могут быть непосредственно исполняемыми. Например, множество простых чисел в нотации { x| p(x) } , где логическое выражение p(x) является истиной на множестве x, может быть записано как:
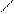



 { n| lm[(2<= m<= n-1) (n mod m = 0)]}
{ n| lm[(2<= m<= n-1) (n mod m = 0)]}
Эта формула читается так: множество натуральных чисел n таких, что не существует натурального m от 2 до n-1, на которое n делится без остатка.
Чтобы вывести все простые числа в диапазоне от 2 до 100, достаточно на SETL написать однострочную программу:
print ({n in{2..100}| not exists m in{2..n-1}| (n mod m) = 0});
Все подобные языки объединяет то, что при их разработке учитывали больше потребности математики, чем других наук. Зачастую главной задачей становилось – моделирование известной математической теории, а не реализация команд для процессора и памяти. Такие продвинутые языки полезны для трудно программируемых задач, где важно сосредоточиться на проблеме, а не на деталях реализации.
Языки, ориентированные на данные, сейчас несколько менее популярны, чем раньше потому, что объектно-ориентированные методы сейчас уже внедрены в обычные языки типа C++ и Ada, а также из-за конкуренции более новых языковых концепций, таких как функциональное и логическое программирование.
Дата добавления: 2016-08-08; просмотров: 1439;