Древообразная структура HTML
Прежде чем мы начнем детально, кирпичик за кирпичиком, разбирать тонкости HTML, я позволю себе немного отклониться в сторону, и рассмотреть базовые концепции не менее известного языка разметки – XML. Причина этого проста. XML появился позже и, стало быть, он больше соответствует требованиям современного мира. Нам будет проще понять тенденцию развития HTML, который, между прочим, сейчас от XML практически неотличим. HTML даже имеет свое новое имя, чтобы подчеркнуть степень своего родства с XML – это XHTML.
Основная идея, которую хотелось бы рассмотреть, это то, что XML, как и HTML – это дерево. Они имеют древообразную структуру с одним корневым элементом и множеством других, ответвляющихся от него. Точно так же как дерево имеет корень, ствол и листья – веб-документ имеет свои различные типы узлов – элементы, текстовые узлы, узлы комментариев и другие. Рассмотрим их более детально.
Ниже приведен список типов узлов XML.
1. Document – Документ
2. DocumentFragment – Фрагмент Документа
3. DocumentType – Тип Документа
4. ProcessingInstruction – Исполняемая Инструкция
5. EntityReference – Ссылка на сущность
6. Element – Элемент
7. Attr – Атрибут
8. Text – Текст
9. CDATASection – Необрабатываемая Секция
10. Comment – Комментарий
11. Entity – Сущность
12. Notation – Нотация
Всего существует 12 типов узлов. Мы не будем рассматривать их все, а ограничимся только лишь самыми значимыми из них – это Document, DocumentType, Element, Attr, Text, Comment и EntityReference. Рассмотрим примеры этих узлов.
Document – это узел, который объединяет в себе все остальные узлы XML-дерева. Он является корневым узлом документа. Узел Document не может содержать внутри себя другой узел Document, и он никак не выражается символьным представлением в XML и HTML, в отличие от остальных узлов. Другими словами, не смотря на то, что этот узел вполне реален, и является основой всех остальных узлов, проявляет он себя неявно, в виде логической группы других узлов, о которых мы сейчас и поговорим.
Рассмотрим пример самого простого узла типа Element.
Узел типа Element
<div />
div – это имя элемента. Обратите внимание, что, например, div и DIV – это разные элементы, точно также как Div, DiV и т.д. Согласно спецификации XML, имя элемента чувствительно к регистру символов. Как показано в примере, XML элемент может быть представлен в виде его имени, выделенного угловыми скобками. Косая черта перед закрывающей скобкой означает, что это одиночный элемент, который не содержит дочерние узлы. Этот же элемент может быть представлен в следующем виде:
Узел типа Element
<div></div>
Такая запись элемента означает то же самое, что и предыдущий пример, с той лишь разницей, что здесь явно присутствует как открывающая составляющая элемента <div> так и закрывающая – </div>. Согласно спецификации XML все элементы документа должны быть закрыты, в то время как спецификация HTML (но не XHTML!) допускает существование незакрытых элементов.
Открывающая и закрывающая составные части элемента называются тегами. Различают открывающий тег и закрывающий тег. Таким образом, понятие тега неразрывно связано с понятием элемента. Имена открывающего и закрывающего тегов должны точно совпадать. Приведенный ниже пример считается неправильным, потому, открывающий и закрывающий теги не совпадают.
Неправильный элемент
<div></DIV>
Элемент может содержать внутри себя другие узлы, как например текст или другие элементы. Пример элемента, внутри которого содержится текст, приведен ниже.
Узел типа Text внутри элемента div
<div>Lorem ipsum</div>
Здесь «Lorem ipsum*» это текст, а точнее текстовый узел, или узел типа Text. Текстовый узел в XML и HTML выражается в виде самой обычной строки текста.
Рассмотрим следующий пример:
Элемент и атрибут
<div class=”box”>Lorem ipsum</div>
В этом примере, помимо дочернего текстового узла, элемент div также имеет атрибут.
class – это имя атрибута, а «box» – его значение.
По аналогии с именем элемента, имя атрибута также чувствительно к регистру символов. Значение атрибута всегда приводится в кавычках после знака равенства. Таковы требования XML. В HTML знаки кавычек были необязательны. Однако это правило не относится к XHTML документам, где символы кавычек обязательны, как и в XML.
Напомню, что XHTML полностью подчиняется правилам XML. Следующий пример считается неправильным, потому, что в нем значение атрибута не взято в кавычки:
Неправильный атрибут
<div class=box>Lorem ipsum</div>
Любое дерево – это иерархия узлов. В дереве одни узлы входят в состав других узлов, и так бесконечное количество раз. Иерархия узлов легко может быть представлена с помощью открывающихся и закрывающихся тегов.
Рассмотрим следующий пример и постараемся понять смысл тегов в отображении иерархической структуры документа.
Иерархия узлов
<div class=”box”><strong>Lorem ipsum</strong></div>
В этом примере четко отображена зависимость элементов между собой. Элемент div имеет атрибут class и содержит внутри себя элемент strong, который в свою очередь имеет в своем составе текстовый узел со значением «Lorem ipsum».
Следующий пример не отображает строгую иерархию узлов документа, а стало быть, считается неправильным:
Неправильная структура узлов
<div class=”box”><strong>Lorem ipsum</div></strong>
Этот код неправильный потому, что после открывающегося элемента strong следует закрывающая составляющая элемента div, а это нарушает обычный порядок их вложенности.
Элементы, атрибуты и текст – самые часто встречаемые узлы в XML и XHTML документах. Теперь давайте рассмотрим вспомогательные типы узлов: DocumentType, Comment и EntityReference. Самый простой из них – это комментарий (Comment). Его предназначение очевидно. Это узел, который несет дополнительную информацию о документе и его содержимом. Пример узла комментария приведен ниже:
Узел типа Comment
<!-- Это узел типа Comment -->
Узел комментария начинается с символов «<!--» и заканчивается «-->». Все, что находится внутри этой комбинации символов, является значением этого узла.
Узел EntityReference мы не будем рассматривать во всех его подробностях, а остановимся лишь на тех аспектах, которые непосредственно связаны с XHTML. Все такие узлы начинаются со знака «&» и заканчиваются символом «;». Примеры таких узлов приведены ниже:
Узлы типа EntityReference
&
<
©
 

Для простоты такие узлы следует рассматривать исключительно с точки зрения заменяемых объектов. С их помощью, например, выводятся различные специальные символы, вроде знака авторского права «©» – © или амперсанда «&» – &. Спецификация XML определяет пять значений EntityReference – &,<, >, " и ', которые соответствуют символам «&», «<», «>», «”» и «’». В свою очередь, спецификация XHTML дополняет этот список такими значениями как (неразрываемый символ пробела), © (знак авторского права) и множеством других. Узлы EntityReference тесно связаны с текстовыми узлами. Ниже приведен пример использования такого узла в фрагменте XHTML-кода:
Фрагмент XHTML
<p>© 2007 Company Name</p>
В браузере подобный фрагмент будет отображен следующим образом:
Пример отображения узла EntityReference с текстовым узлом
© 2007 Company Name
Вернемся к древообразной структуре документа. Как мы уже знаем, корневым узлом XML-дерева является Document. Согласно спецификации XML, его дочерними элементами могут быть такие узлы как DocumentType, Comment, ProcessingInstruction и Element. При этом, Element в данном случае, может быть только один, и называется он корневым элементом документа. Другими словами, может существовать только один дочерний узел типа Element у узла типа Document. Именно с корневого элемента удобнее всего рассматривать древообразную структуру документа, а не с узла Document. Рассмотрим пример простейшего XML-документа:
Простейший XML-документ
<root />
Здесь мы имеем один элемент root в документе, что не противоречит правилам XML.
Для того чтобы было понятно, что это именно XML-документ, а не произвольный текстовый файл, в начале такого документа принято добавлять заголовок следующего вида:
XML-документ с заголовком
<?xml version=”1.0”?>
<root />
Странная запись перед элементом root является ни чем иным как узлом типа ProcessingInstruction, который говорит о том, что мы имеем дело с XML-документом, отвечающим спецификации XML версии 1.0. Подробное рассмотрение узлов ProcessingInstruction выходит за рамки данной книги, поэтому мы не будем на этом останавливаться. Достаточно сказать, что такие узлы начинаются с комбинации символов «<?» и заканчиваются «?>».
Добавим комментарий и несколько вложенных узлов к нашему документу:
Пример XML-документа
<?xml version=”1.0”?>
<!-- Простейший XML-документ -->
<root>
<first-element>Первый текстовый фрагмент</first-element>
<second-element>Второй текстовый фрагмент</second-element>
</root>
Документ несколько преобразился. Теперь он имеет узел ProcessingInstruction, узел Comment, корневой элемент и несколько вложенных элементов и текстовых узлов. Согласно спецификации XML, количество вложенных внутри корневого элемента узлов можно увеличивать до бесконечности. А их последовательность также может быть произвольной. Но нужен ли кому-нибудь подобный беспорядок? Ведь любой документ, будь то веб-документ или любой другой документ, с которым нам обычно приходится иметь дело, всегда должен отвечать каким-то правилам. Например, после заголовка раздела книги не может идти ее аннотация, а после оглавления не может идти заключение. Сходным образом каждый веб-документ тоже подчиняется определенным правилам. Множество наборов таких правил определяет множество разных типов документов. Такой набор правил получил название DTD, что является аббревиатурой от Document Type Definition. Более подробно об этом термине мы поговорим в следующем разделе, который посвящен ознакомлению с языком описания схемы документа. Сейчас же рассмотрим следующий очень важный узел XML-дерева.
Для того чтобы отличать один тип документа от другого, существует специальный узел типа DocumentType. Его запись весьма специфична. Ниже приведены допустимые конструкции таких узлов:
Конструкции узлов DocumentType
<!DOCTYPE имя_корневого_элемента [DTD]>
<!DOCTYPE имя_корневого_элемента SYSTEM URL>
<!DOCTYPE имя_корневого_элемента SYSTEM URL [DTD]>
<!DOCTYPE имя_корневого_элемента PUBLIC идентификатор URL>
<!DOCTYPE имя_корневого_элемента PUBLIC идентификатор URL [DTD]>
Здесь URL – это путь на внешний файл DTD, а DTD – непосредственное описание правил для документа, выделенное квадратными скобками.
Давайте добавим узел DocumentType в наш XML-документ:
Пример XML-документа с объявлением DOCTYPE
<?xml version=”1.0”?>
<!-- Простейший XML-документ -->
<!DOCTYPE root SYSTEM ”example.dtd”>
<root>
<first-element>Первый текстовый фрагмент</first-element>
<second-element>Второй текстовый фрагмент</second-element>
</root>
Под такой записью следует понимать, что данный XML-документ, соответствует (или точнее должен соответствовать, но об этом позже) набору правил, описанных в некотором файле example.dtd.
XHTML является подмножеством XML. XHTML – это XML документ, который соответствует некоторому набору правил описанных при помощи DTD.
Корневым элементом XHTML всегда является элемент с именем html, потому, что это описано в его DTD. DTD определяет структуру этого документа. Это было также сделано по причине максимальной поддержки совместимости XHTML с HTML, у которого html также является корневым элементом. Дело в том, что XHTML это на самом деле HTML перекочевавший в сторону XML. Он содержит в себе практически все, чем обладал HTML, но делает это в соответствии с более строгими правилами XML, среди которых уже рассмотренные нами обязательное заключение значений атрибутов в кавычки, чувствительность имен к регистру символов и другие.
Спецификация XHTML версии 1.0 предусматривает три вида документов. Это Strict, Transitional и Frameset. Каждому из этих типов соответствует свой DTD и каждый из них имеет свои особенности и свое предназначение.
Strict обычно используется для получения наиболее «прозрачной» и понятной структуры документа, не загрязняя его лишними тегами и атрибутами, относящимися к отображению. Предполагается, что все нужные для страницы правила отображения и позиционирования элементов должны быть описаны в CSS (Cascading Style Sheet – каскадная таблица стилей), в то время как в документе фигурирует только его логическая структура. Об этом мы еще будем говорить более подробно.
Transitional – в настоящий момент наиболее часто встречаемый вид XHTML. Идея его создания была в сохранении многих свойств HTML, а также в поддержке старых браузеров, которые понимают не все свойства CSS. Это своего рода переходный вид старого типа HTML-документов в новый. Со временем этот вид документов наверняка будет вытеснен документами Strict, или более новыми версиями XHTML.
Что касается Frameset, то из названия должно быть понятно, что этот вид XHTML предназначен для описания документов, содержащих набор фреймов – элементов frameset и frame, которые разделяют страницу на некие прямоугольные области (фреймы), внутри каждой из которых живет отдельный документ любого типа. По умолчанию, окно браузера можно считать одним фреймом, поскольку в него может быть загружен один (и только один) документ.
Объявления DOCTYPE для вышеперечисленных типов XHTML-документов приведены ниже.
XHTML 1.0 Strict
<!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Strict//EN" "http://www.w3.org/TR/xhtml1/DTD/xhtml1-strict.dtd">
XHTML 1.0 Transitional
<!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Transitional//EN"
"http://www.w3.org/TR/xhtml1/DTD/xhtml1-transitional.dtd">
XHTML 1.0 Frameset
<!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Frameset//EN"
"http://www.w3.org/TR/xhtml1/DTD/xhtml1-frameset.dtd">
Если схематически представить древообразную структуру документа, точнее его часть, например для XHTML 1.0 Strict и XHTML 1.0 Frameset, то мы получим что-то наподобие таких вот рисунков, где пунктиром обозначены необязательные элементы:
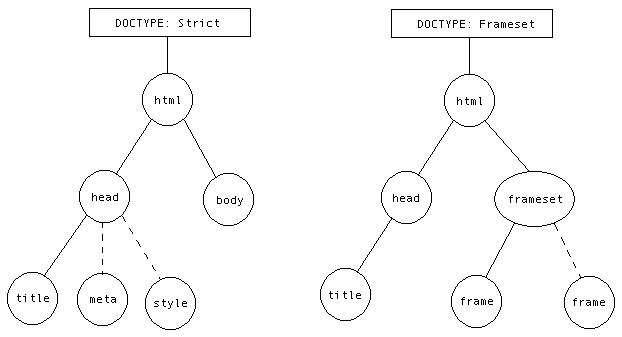
Как видно из схемы, XHTML документ имеет один корневой элемент – html. Далее, в зависимости от типа документа, этот элемент содержит либо элементы head и body, либо элементы head и frameset. В свою очередь, элемент head имеет обязательный элемент title и необязательные элементы meta, style, и т.д. Структура документа должна строго соответствовать его типу, объявленному при помощи DOCTYPE.
Как мы уже говорили, правила определяющие структуру документа, описаны в DTD.
Понятие DTD
DTD (аббревиатура от Document Type Definition) – это язык описания структуры XML-документа. По своей сути этот язык предельно прост. Он описывает то, какие элементы могут входить в состав данного документа, какие из них могут иметь дочерние узлы, а какие нет, какие атрибуты может иметь тот или иной элемент и т.д. Детальное изучение DTD на данном этапе обучения не имеет смысла, достаточно будет поверхностно ознакомиться с этим языком.
Рассмотрим некоторые фрагменты DTD из http://www.w3.org/TR/xhtml1/DTD/xhtml1-strict.dtd, который является сводом правил для документов XHTML 1.0 Strict.
Фрагмент DTD из xhtml1-strict.dtd
<!ELEMENT html (head, body)>
Этот фрагмент DTD говорит о том, что внутри элемента html должен быть один, и только один, элемент head и один элемент body, причем сначала должен идти head, а затем body.
Фрагмент DTD из xhtml1-strict.dtd
<!ELEMENT title (#PCDATA)>
Эта запись говорит, что внутри элемента title может быть только текст, и ничего больше. Никакие другие элементы внутри него не допускаются.
Фрагмент DTD из xhtml1-strict.dtd
<!ENTITY % heading "h1|h2|h3|h4|h5|h6">
<!ENTITY % lists "ul | ol | dl">
<!ENTITY % blocktext "pre | hr | blockquote | address">
<!ENTITY % block "p | %heading; | div | %lists; | %blocktext; | fieldset | table">
<!ENTITY % misc.inline "ins | del | script">
<!ENTITY % misc "noscript | %misc.inline;">
<!ENTITY % form.content "(%block; | %misc;)*">
<!ELEMENT form %form.content;>
А, например, этот фрагмент, или точнее несколько фрагментов, говорит о том, что элемент form не может иметь непосредственно дочерние элементы input, select, textarea и label*.
Необязательно понимать синтаксис DTD, важно понять его смысл. Думаю нетрудно оценить его роль и важность в создании веб-документов.
Наверняка сейчас у многих читателей возникает вопрос – а кто следит за соответствием того или иного документа его типу? Ответ вас не удивит – все тот же WWW-консорциум. Только он не следит, а помогает сделать документ правильным, предоставляя разработчикам средство проверки документов на соответствие их спецификации. Такое средство среди разработчиков называется «валидатором», от англ. valid, что означает «правильный», соответствующий своему типу. Наиболее известный онлайн-валидатор HTML-кода находится по адресу http://validator.w3.org
По некоторым причинам, в числе которых отсутствие типизации узлов и отличный от XML синтаксис, DTD постепенно уходит в прошлое, вытесняемый новым языком описания структуры документов. Его альтернативой с более широкими возможностями является XML Schema, который появился несколько позже и который имеет в своем арсенале более мощные средства определения типа документов. Его мы рассматривать не будем.
Дата добавления: 2016-07-09; просмотров: 830;