Методы выявления и оценки корреляционной связи
Для выявления наличия и характера корреляционной связи между двумя признаками в статистике используется ряд методов.
1. Рассмотрение параллельных данных (значений x и y в каждой из n единиц). Единицы наблюдения необходимо расположить по возрастанию значений факторного признака х (как в таблице справа) и затем сравнить с ним (визуально) поведение результативного признака у.
В нашей задаче в 6 случаях по мере увеличения значений x увеличиваются и значения y, а в 5 случаях этого не происходит, поэтому затруднительно говорить о прямой связи между х и у.
2. Графический метод – это графическое изображение корреляционной зависимости. Для этого, имея n взаимосвязанных пар значений x и y и пользуясь прямоугольной системой координат, каждую такую пару изображают в виде точки на плоскости с координатами x и y. Совокупность полученных точек представляет собой корреляционное поле (рис. 20), а соединяя последовательно нанесенные точки отрезками, получают ломаную линию, именуемую эмпирической линией регрессии (рис. 21).
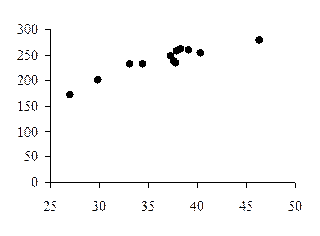
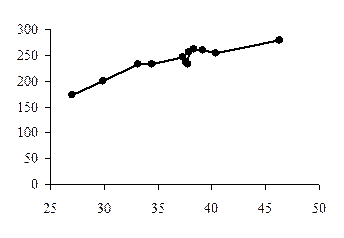 Рис. 20. Корреляционное поле Рис. 21. Эмпирическая линия регрессии
Рис. 20. Корреляционное поле Рис. 21. Эмпирическая линия регрессии
Визуально анализируя график, можно предположить характер зависимости между признаками x и y. В нашей задаче эмпирическая линия регрессии (рис.21) похожа на восходящую прямую, что позволяет выдвинуть гипотезу о наличии прямой зависимости между величиной стоимостного внешнеторгового товарооборота и величиной таможенных платежей в федеральный бюджет.
3. Метод аналитических группировокиспользуется при большом числе наблюдений для выявления корреляционной связи между двумя количественными признаками. Чтобы выявить наличие корреляционной связи между двумя признаками, проводится группировка единиц совокупности по факторному признаку х и для каждой выделенной группы рассчитывается среднее значение результативного признака 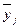 . Если результативный признак у зависит от факторного х, то в изменении среднего значения будет прослеживаться определенная закономерность. Примером такой группировки могут служить данные об издержках обращения предприятий оптовой торговли с различным товарооборотом (см. табл. 40).
. Если результативный признак у зависит от факторного х, то в изменении среднего значения будет прослеживаться определенная закономерность. Примером такой группировки могут служить данные об издержках обращения предприятий оптовой торговли с различным товарооборотом (см. табл. 40).
Таблица 40. Условные пример аналитической группировки
| Оптовый товарооборот, млн.руб. | Количество предприятий | Издержки обращения, % к оптовому товарообороту |
| менее 25 26-50 51-100 101-200 201-500 более 501 | 46,0 26,5 24,4 23,0 17,6 16,9 |
В последнем столбце табл. 40 приведены средние величины, рассчитанные на основе индивидуальных данных об издержках отдельных предприятий каждой группы. Данные таблицы 40 свидетельствуют, что чем крупнее товарооборот, тем меньше издержки обращения. Таким образом, с помощью простой аналитической группировки можно выявить наличие зависимости между рассматриваемыми показателями: объемом товарооборота как показателем размера предприятий и средним уровнем издержек обращения.
4. Метод корреляционных таблиц предполагает комбинационное распределение единиц совокупности по двум количественным признакам. Такая таблица строится по типу «шахматной», т.е. в подлежащем (строках) таблицы выделяются группы по факторному признаку х, а в сказуемом (столбцах) – по результативному у (или наоборот), а в клетках таблицы на пересечении х и у показано число случаев совпадения каждого значения х с соответствующим значением у. Общий вид такой таблицы показан на условном распределении 40 единиц по признакам х и у, где х – стаж работы, у – производительность труда (число изделий, вырабатываемых в час одним рабочим) – таблица 41. Среднее значение по группам определяется по средней арифметической взвешенной по серединам группировочных интервалов.
Таблица 41. Условные корреляционной таблицы
| Значение признака xj | Значение признака уi | Итого | Среднее
значение
по группам
| |||
| менее 7,5 | 7,5-12,5 | 12,5-17,5 | более 17,5 | |||
| менее 2 2 – 4 4 – 6 6 – 8 | – – | – | – | – – | 8,75 12,08 15,31 16,87 | |
| Итого | 14,00 |
Как видно из таблицы 41, по мере увеличения значений х итоговые групповые средние тоже увеличиваются от группы к группе, что свидетельствует о том, что между х и у существует корреляционная связь. О наличии и направлении связи можно судить и по «внешнему виду» таблицы, т.е. по расположению в ней частот: если частоты расположены в клетках таблицы беспорядочно, то это чаще всего свидетельствует об отсутствии связи между группировочными признаками (или о незначительной зависимости); если частоты сконцентрированы ближе к одной из диагоналей и центру таблицы, образуя своего рода эллипс, то это почти всегда свидетельствует о наличии зависимости между х и у, близкой к линейной. Расположение по диагонали из верхнего левого угла в нижний правый свидетельствует о прямой линейной связи, а из нижнего левого угла в верхний правый – об обратной.
На основе аналитических группировок и корреляционных таблиц можно не только выявить наличие зависимости между двумя коррелируемыми показателями, но и измерить тесноту этой связи, в частности, с помощью эмпирического корреляционного отношения.
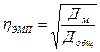 , ,
| (118) |
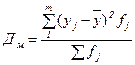 , ,
| (119) |
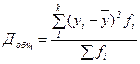 . .
| (120) |
где m – число групп по факторному признаку х;
k – число групп по результативному признаку у;
– средние значения результативного признака по группам;
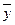 – общее среднее значение результативного признака;
– общее среднее значение результативного признака;
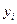 – индивидуальные значения результативного признака;
– индивидуальные значения результативного признака;
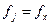 – частота в j-й группе х;
– частота в j-й группе х;
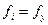 – частота в i-й группе у.
– частота в i-й группе у.
Рассчитаем это отношение для нашего примера (таблица 41):
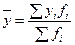 =(5*3+10*9+15*21+20*7)/40=14
=(5*3+10*9+15*21+20*7)/40=14
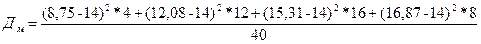 =6,19599;
=6,19599;
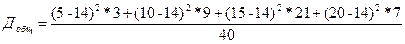 =16,5;
=16,5; 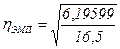 =0,613.
=0,613.
Полученное значение 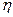 =0,613 позволяет утверждать, что существует заметная связь между стажем работы и производительностью труда.
=0,613 позволяет утверждать, что существует заметная связь между стажем работы и производительностью труда.
5. Коэффициент корреляции знаков (Фехнера) – простейший показатель тесноты связи, основанный на сравнении поведения отклонений индивидуальных значений каждого признака (x и y) от своей средней величины. При этом во внимание принимаются не величины отклонений ( 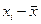 ) и (
) и ( 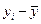 ), а их знаки («+» или «–»). Определив знаки отклонений от средней величины в каждом ряду, рассматривают все пары знаков и подсчитывают число их совпадений (С) и несовпадений (Н). Тогда коэффициент Фехнера рассчитывается как отношение разности чисел пар совпадений и несовпадений знаков к их сумме, т.е. к общему числу наблюдаемых единиц:
), а их знаки («+» или «–»). Определив знаки отклонений от средней величины в каждом ряду, рассматривают все пары знаков и подсчитывают число их совпадений (С) и несовпадений (Н). Тогда коэффициент Фехнера рассчитывается как отношение разности чисел пар совпадений и несовпадений знаков к их сумме, т.е. к общему числу наблюдаемых единиц:
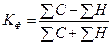 . (121)
. (121)
Очевидно, что если знаки всех отклонений по каждому признаку совпадут, то КФ=1, что характеризует наличие прямой связи. Если все знаки не совпадут, то КФ=–1(обратная связь). Если же åС=åН, то КФ=0. Итак, как и любой показатель тесноты связи, коэффициент Фехнера может принимать значения от 0 до  1. Однако, если КФ=1, то это ни в коей мере нельзя воспринимать как свидетельство функциональной зависимости между х и у.
1. Однако, если КФ=1, то это ни в коей мере нельзя воспринимать как свидетельство функциональной зависимости между х и у.
Средние значения факторного и результативного признаков определяем по формуле средней арифметической простой (10):
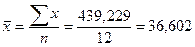 ;
; 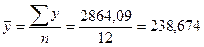 .
.
В двух последних столбцах таблицы 42 приведены знаки отклонений каждого х и у от своей средней величины. Число совпадений знаков – 10, а несовпадений – 2, тогда определяем коэффициент корреляции знаков (Фехнера) по формуле (121):
КФ= 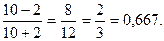
Таблица 42. Вспомогательная таблица для расчета коэффициента Фехнера
| № п/п | x | y | x – 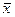
| y – 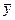
|
| 27,068 | 172,17 | – | – | |
| 29,889 | 200,90 | – | – | |
| 33,158 | 232,10 | – | – | |
| 34,444 | 231,83 | – | – | |
| 37,299 | 246,53 | + | + | |
| 37,554 | 236,99 | + | – | |
| 37,755 | 233,40 | + | – | |
| 37,909 | 256,43 | + | + | |
| 38,348 | 261,89 | + | + | |
| 39,137 | 259,36 | + | + | |
| 40,370 | 253,62 | + | + | |
| 46,298 | 278,87 | + | + | |
| Итого | 439,229 | 2864,09 |
Обычно такое значение показателя тесноты связи характеризует заметную прямую зависимость между x и y, однако, следует иметь в виду, что поскольку КФ зависит только от знаков и не учитывает величину самих отклонений х и у от их средних величин, то он практически характеризует не столько тесноту связи, сколько ее наличие и направление.
6. Линейный коэффициент корреляции – самый популярный измеритель тесноты линейной связи между двумя количественными признаками x и y. Он основан на предположении, что при полной независимости[43] признаков x и у отклонения значений факторного признака от средней ( 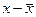 ) носят случайный характер и должны случайно сочетаться с различными отклонениями (
) носят случайный характер и должны случайно сочетаться с различными отклонениями ( 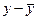 ). При наличии значительного перевеса совпадений или несовпадений таких отклонений делается предположение о наличии связи между x и y.
). При наличии значительного перевеса совпадений или несовпадений таких отклонений делается предположение о наличии связи между x и y.
В отличие от КФ в линейном коэффициенте корреляции учитываются не только знаки отклонений от средних величин, но и значения самих отклонений, выраженные для сопоставимости в единицах среднего квадратического отклонения t:
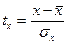 и
и 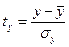 .
.
Линейный коэффициент корреляции r представляет собой среднюю величину из произведений нормированных отклонений для x и у:
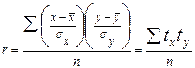 , (122) или
, (122) или 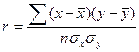 . (123)
. (123)
Числитель формулы (123), деленный на n, представляющий собой среднее произведение отклонений значений двух признаков от их средних значений, называется коэффициентом ковариации – это мера совместной вариации факторного x и результативного y признаков:
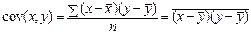 (124)
(124)
Недостатком коэффициента ковариации является то, что он не нормирован, в отличие от линейного коэффициента корреляции. Очевидно, что линейный коэффициент корреляции представляет собой частное от деления ковариации между х и у на произведение их средних квадратических отклонений:
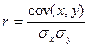 . (125)
. (125)
Путем несложных математических преобразований[44] можно получить и другие модификации формулы линейного коэффициента корреляции, например:
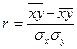 , (126)
, (126) 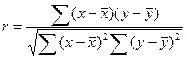 , (127)
, (127)
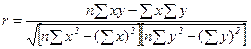 , (128)
, (128) 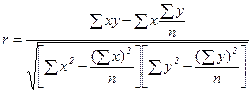 . (129)
. (129)
Линейный коэффициент корреляции может принимать значения от –1 до +1, причем знак определяется в ходе решения. Например, если 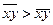 , то r по формуле (126) будет положительным, что характеризует прямую зависимость между х и у, в противном случае (r<0) – обратную связь. Если
, то r по формуле (126) будет положительным, что характеризует прямую зависимость между х и у, в противном случае (r<0) – обратную связь. Если 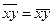 , то r=0, что означает отсутствие линейной зависимости между х и у, а при r=1 – функциональная зависимость между х и у. Следовательно, всякое промежуточное значение r от 0 до 1 характеризует степень приближения корреляционной связи между х и у к функциональной. Существует эмпирическое правило (шкала Чэддока) для оценки тесноты связи, представленное в таблице 43.
, то r=0, что означает отсутствие линейной зависимости между х и у, а при r=1 – функциональная зависимость между х и у. Следовательно, всякое промежуточное значение r от 0 до 1 характеризует степень приближения корреляционной связи между х и у к функциональной. Существует эмпирическое правило (шкала Чэддока) для оценки тесноты связи, представленное в таблице 43.
Таблица 43. Шкала Чэддока
| | r | | Теснота связи |
| менее 0,1 | отсутствует линейная связь |
| 0,1 ÷ 0,3 | слабая |
| 0,3 ÷ 0,5 | умеренная |
| 0,5 ÷ 0,7 | заметная |
| более 0,7 | сильная (тесная) |
Таким образом, коэффициент корреляции при линейной зависимости служит как мерой тесноты связи, так и показателем, характеризующим степень приближения корреляционной зависимости между х и у к линейной. Поэтому близость значения r к 0 в одних случаях может означать отсутствие связи между х и у, а в других свидетельствовать о том, что зависимость не линейная.
В нашей задаче для расчета r построим вспомогательную таблицу 44.
Таблица 44. Вспомогательные расчеты линейного коэффициента корреляции
| № п/п | x | y | 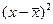
| 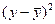
| tx | ty | tx ty | 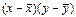
| xy |
| 27,068 | 172,17 | 90,905 | 4422,804 | -1,993 | -2,408 | 4,799 | 634,078 | 4660,298 | |
| 29,889 | 200,90 | 45,070 | 1426,888 | -1,403 | -1,368 | 1,919 | 253,594 | 6004,700 | |
| 33,158 | 232,10 | 11,864 | 43,220 | -0,720 | -0,238 | 0,171 | 22,644 | 7695,972 | |
| 34,444 | 231,83 | 4,659 | 46,843 | -0,451 | -0,248 | 0,112 | 14,773 | 7985,153 | |
| 37,299 | 246,53 | 0,485 | 61,714 | 0,146 | 0,284 | 0,041 | 5,472 | 9195,322 | |
| 37,554 | 236,99 | 0,906 | 2,836 | 0,199 | -0,061 | -0,012 | -1,603 | 8899,922 | |
| 37,755 | 233,40 | 1,328 | 27,817 | 0,241 | -0,191 | -0,046 | -6,079 | 8812,017 | |
| 37,909 | 256,43 | 1,707 | 315,270 | 0,273 | 0,643 | 0,176 | 23,199 | 9721,005 | |
| 38,348 | 261,89 | 3,047 | 538,975 | 0,365 | 0,841 | 0,307 | 40,525 | 10042,958 | |
| 39,137 | 259,36 | 6,424 | 427,904 | 0,530 | 0,749 | 0,397 | 52,430 | 10150,572 | |
| 40,37 | 253,62 | 14,195 | 223,378 | 0,788 | 0,541 | 0,426 | 56,310 | 10238,639 | |
| 46,298 | 278,87 | 94,004 | 1615,705 | 2,027 | 1,455 | 2,950 | 389,722 | 12911,123 | |
| Итого | 439,229 | 2864,09 | 274,594 | 9153,353 | 11,241 | 1485,066 | 106317,681 |
В нашей задаче: 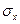 =
= 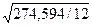 = 4,784;
= 4,784; 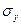 =
= 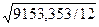 = 27,618.
= 27,618.
Тогда линейный коэффициент корреляции по формуле (122): r = 11,241/12 = 0,937.
Аналогичный результат получаем по формуле (123): r = 1485,066/(12*4,784*27,618) = 0,937
Или по формуле (126): r = (106317,681/12 – 36,602*238,674) / (4,784*27,618) = 0,937,
Найденное значение свидетельствует о том, что связь между величиной стоимостного внешнеторгового товарооборота и величиной таможенных платежей в федеральный бюджет очень близка к функциональной (сильная по шкале Чэддока).
Проверка коэффициента корреляции на значимость (существенность). Интерпретируя значение коэффициента корреляции, следует иметь в виду, что он рассчитан для ограниченного числа наблюдений и подвержен случайным колебаниям, как и сами значения x и y, на основе которых он рассчитан. Другими словами, как любой выборочный показатель, он содержит случайную ошибку и не всегда однозначно отражает действительно реальную связь между изучаемыми показателями. Для того, чтобы оценить существенность (значимость) самого r и, соответственно, реальность измеряемой связи между х и у, необходимо рассчитать среднюю квадратическую ошибку коэффициента корреляции σr. Оценка существенности (значимости) r основана на сопоставлении значения r с его средней квадратической ошибкой: 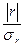 .
.
Существуют некоторые особенности расчета σr в зависимости от числа наблюдений (объема выборки) – n.
1. Если число наблюдений достаточно велико (n>30), то σr рассчитывается по формуле (130):
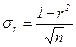 . (130)
. (130)
Обычно, если >3, то r считается значимым (существенным), а связь – реальной. Задавшись определенной вероятностью, можно определить доверительные пределы (границы) r = ( 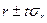 ), где t – коэффициент доверия, рассчитываемый по интегралу Лапласа (см. Приложение 1).
), где t – коэффициент доверия, рассчитываемый по интегралу Лапласа (см. Приложение 1).
2. Если число наблюдений небольшое (n<30), то σr рассчитывается по формуле (131):
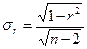 , (131)
, (131)
а значимость r проверяется на основе t-критерия Стьюдента, для чего определяется расчетное значение критерия по формуле (132) и сопоставляется c tТАБЛ.
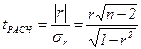 . (132)
. (132)
Табличное значение tТАБЛ находится по таблице распределения t-критерия Стьюдента (см. Приложение 2) при уровне значимости α=1-β и числе степеней свободы ν=n–2. Если tРАСЧ> tТАБЛ ,то r считается значимым, а связь между х и у – реальной. В противном случае (tРАСЧ< tТАБЛ) считается, что связь между х и у отсутствует, и значение r, отличное от нуля, получено случайно.
В нашей задаче число наблюдений небольшое, значит, оценивать существенность (значимость) линейного коэффициента корреляции будем по формулам (131) и (132):
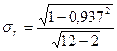 = 0,349/3,162 = 0,110;
= 0,349/3,162 = 0,110;
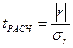 = 0,937/0,110 = 8,482.
= 0,937/0,110 = 8,482.
Из приложения 2 видно, что при числе степеней свободы ν = 12 – 2 = 10 (в 10-й строке) и вероятности β = 95% (уровень значимости α =1 – β = 0,05) tтабл=2,2281, а при вероятности 99% (α=0,01) tтабл=3,169, значит, tРАСЧ > tТАБЛ, что дает возможность считать линейный коэффициент корреляции r = 0,937 значимым.
7. Подбор уравнения регрессии[45] представляет собой математическое описание изменения взаимно коррелируемых величин по эмпирическим (фактическим) данным. Уравнение регрессии должно определить, каким будет среднее значение результативного признака у при том или ином значении факторного признака х, если остальные факторы, влияющие на у и не связанные с х, не учитывать, т.е. абстрагироваться от них. Другими словами, уравнение регрессии можно рассматривать как вероятностную гипотетическую функциональную связь величины результативного признака у со значениями факторного признака х.
Уравнение регрессии можно также назвать теоретической линией регрессии. Рассчитанные по уравнению регрессии значения результативного признака называются теоретическими.Они обычно обозначаются 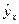 или
или 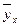 (читается: «игрек, выравненный по х») и рассматриваются как функция от х, т.е. = f(x).
(читается: «игрек, выравненный по х») и рассматриваются как функция от х, т.е. = f(x).
Найти в каждом конкретном случае тип функции, с помощью которой можно наиболее адекватно отразить ту или иную зависимость между признаками х и у, — одна из основных задач регрессионного анализа. Выбор теоретической линии регрессии часто обусловлен формой эмпирической линии регрессии; теоретическая линия как бы сглаживает изломы эмпирической линии регрессии. Кроме того, необходимо учитывать природу изучаемых показателей и специфику их взаимосвязей.
Для аналитической связи между х и у могут использоваться виды уравнений, приведенные в таблице 30 (при условии замены t на x). Обычно зависимость, выражаемую уравнением прямой, называют линейной (или прямолинейной), а все остальные — криволинейными зависимостями.
Выбрав тип функции (таблица 30), по эмпирическим данным определяют параметры уравнения. При этом отыскиваемые параметры должны быть такими, при которых рассчитанные по уравнению теоретические значения результативного признака были бы максимально близки к эмпирическим данным.
Существует несколько методов нахождения параметров уравнения регрессии. Наиболее часто используется метод наименьших квадратов (МНК). Его суть заключается в следующем требовании: искомые теоретические значения результативного признака должны быть такими, при которых бы обеспечивалась минимальная сумма квадратов их отклонений от эмпирических значений, т.е.
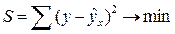 .
.
Поставив данное условие, легко определить, при каких значениях a0, a1 и т.д. для каждой аналитической кривой эта сумма квадратов отклонений будет минимальной. Данный метод уже использовался нами в теме 6 «Статистическое изучение динамики ВЭД», поэтому, воспользуемся формулой (100) для нахождения параметров теоретической линии регрессии, заменив параметр t на x:
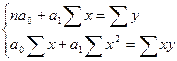 (133)
(133)
Выразив из первого уравнения системы (133) a0, получим[46]:
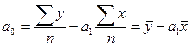 . (134)
. (134)
Подставив (134) во второе уравнение системы (133), затем разделив обе его части на n, получим:
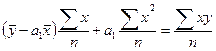 . (135)
. (135)
Применяя 3 раза формулу средней арифметической, получим:
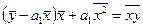 . (136)
. (136)
Раскрыв скобки и перенеся члены без a1 в правую часть уравнения, выразим a1:
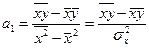 . (137)
. (137)
Параметр a1 в уравнении линейной регрессии называется коэффициентом регрессии, который показывает на сколько изменяется значение результативного признака y при изменении факторного признака x на единицу.
Исходные данные и расчеты для нашего примера представим в таблице 45.
Таблица 45. Вспомогательные расчеты для нахождения уравнения регрессии
| № п/п | x | y | x2 | xy |
| 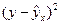
| 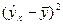
|
| 27,068 | 172,17 | 732,677 | 4660,298 | 187,124 | 223,612 | 2657,453 | |
| 29,889 | 200,90 | 893,352 | 6004,700 | 202,377 | 2,181 | 1317,497 | |
| 33,158 | 232,10 | 1099,453 | 7695,972 | 220,052 | 145,147 | 346,774 | |
| 34,444 | 231,83 | 1186,389 | 7985,153 | 227,006 | 23,274 | 136,153 | |
| 37,299 | 246,53 | 1391,215 | 9195,322 | 242,443 | 16,706 | 14,202 | |
| 37,554 | 236,99 | 1410,303 | 8899,922 | 243,821 | 46,669 | 26,495 | |
| 37,755 | 233,40 | 1425,440 | 8812,017 | 244,908 | 132,441 | 38,864 | |
| 37,909 | 256,43 | 1437,092 | 9721,005 | 245,741 | 114,256 | 49,940 | |
| 38,348 | 261,89 | 1470,569 | 10042,958 | 248,115 | 189,761 | 89,122 | |
| 39,137 | 259,36 | 1531,705 | 10150,572 | 252,381 | 48,710 | 187,871 | |
| 40,370 | 253,62 | 1629,737 | 10238,639 | 259,048 | 29,459 | 415,076 | |
| 46,298 | 278,87 | 2143,505 | 12911,123 | 291,100 | 149,580 | 2748,498 | |
| Итого | 439,229 | 2864,09 | 16351,437 | 106317,681 | 2864,115 | 1121,795 | 8027,945 |
По формуле (137): 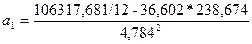 = 5,407.
= 5,407.
По формуле (134): a0 = 238,674 – 5,407*36,602 = 40,767.
Отсюда получаем уравнение регрессии: =40,767+5,407x, подставляя в которое вместо x эмпирические значения факторного признака (2-й столбец таблицы 45), получаем выравненные по прямой линии теоретические значения результативного признака (6-й столбец таблицы 45)[47]. Для иллюстрации различий между эмпирическими и теоретическими линиями регрессии построим график (рисунок Ошибка! Источник ссылки не найден.).
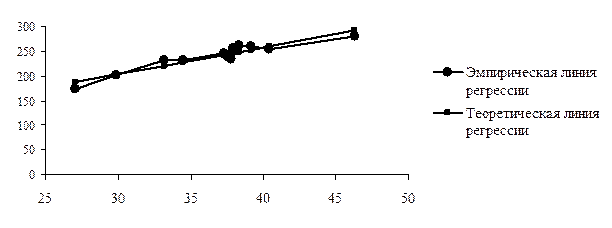
Рис. 22. График эмпирической и теоретической линий регрессии
Из рисунка 22 видно, что небольшие различия между эмпирической и теоретической линиями регрессии существуют, поэтому необходимо оценить существенность коэффициента регрессии и уравнения связи, для чего определяют среднюю ошибку параметров уравнения регрессии и сравнивают их с этой ошибкой.
Расчет ошибок параметров уравнения регрессии основан на использовании остаточной дисперсии, характеризующей расхождение (отклонение) между эмпирическими и теоретическими значениями результативного признака. Для линейного уравнения регрессии ( 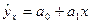 ) средние ошибки параметров a1 и a2 определяются по формулам (138) и (139) соответственно:
) средние ошибки параметров a1 и a2 определяются по формулам (138) и (139) соответственно:
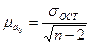 , (138)
, (138) 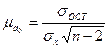 , (139)
, (139) 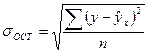 . (140)
. (140)
Значимость параметров проверяется путем сопоставления его значения со средней ошибкой. Обозначим это соотношение как t:
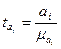 , (141)
, (141)
При большом числе наблюдений (n>30) параметр ai считается значимым, если 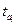 >3.
>3.
Если выборка малая (n<30), то значимость параметра ai проверяется путем сравнения с табличным значения t-критерия Стьюдента при числе степеней свободы ν=n-2 и заданном уровне значимости α (Приложение 2). Если рассчитанное по формуле (141) значение больше табличного, то параметр считается значимым.
В нашем примере по формуле (140): 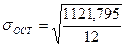 = 9,669.
= 9,669.
Находим среднюю ошибку параметра a0 по формуле (138): 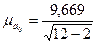 = 3,06.
= 3,06.
Теперь находим среднюю ошибку параметра a1 по формуле (139): 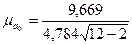 =0,639.
=0,639.
Теперь по формуле (141) для параметра a0: 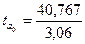 =13,3.
=13,3.
И по той же формуле для параметра a1: 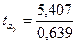 =8,46.
=8,46.
Так как выборка малая, то задавшись стандартной значимостью α=0,05 находим в 10-й строке Приложения 2 табличное значение tα=2,23, которое значительно меньше полученных значений 13,3 и 8,46, что свидетельствует о значимости обоих параметров уравнения регрессии.
Наряду с проверкой значимости отдельных параметров осуществляется проверка значимости уравнения регрессии в целом или, что то же самое, проверка адекватности модели с помощью критерия Фишера по Приложению 4. Данный метод уже использовался нами для проверки адекватности уравнения тренда в предыдущей теме, поэтому воспользовавшись формулой (102) в нашем примере получим[48]: 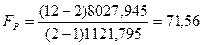
Сравнивая расчетное значение критерия Фишера Fр = 71,56 с табличным Fт = 4,96, определяемое по Приложению 4 при числе степеней свободы ν1 = k – 1 = 2 –1 = 1 и ν2 = n – k = 12 – 2 = 10 (т.е. 1-й столбец и 10-я строка) и стандартном уровне значимости α=0,05, можно сделать вывод, что уравнение регрессии значимо.
8. Коэффициент эластичности показывает, на сколько процентов изменяется в среднем результативный признак y при изменении факторного признака x на 1%. Он рассчитывается на основе уравнения регрессии:
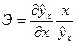 , (142)
, (142)
где 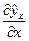 – первая производная уравнения регрессии y по x.
– первая производная уравнения регрессии y по x.
Коэффициент эластичности – величина переменная, т.е. изменяется с изменением значений фактора x. Так, для линейной зависимости :
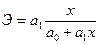 . (143)
. (143)
Применительно к рассмотренному уравнению регрессии, выражающему зависимость величины таможенных платежей в федеральный бюджет от величины стоимостного внешнеторгового оборота ( = 40,767 + 5,407x), коэффициент эластичности по формуле (143): 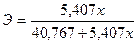 .
.
Подставляя в данное выражение разные значения x, получаем и разные значения Э. Так, например, при x = 40 коэффициент эластичности 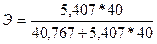 = 0,84, а при x = 50 соответственно
= 0,84, а при x = 50 соответственно 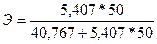 = 0,87 и т.д. Это значит, что при увеличении внешнеторгового товарооборота x с 40 до 40,4 млрд.долл. (т.е. на 1%), величина таможенных платежей возрастет в среднем на 0,84% прежнего уровня; при увеличении x с 50 до 50,5 млрд.долл. (т.е. на 1%) y возрастет на 0,87% и т.д.
= 0,87 и т.д. Это значит, что при увеличении внешнеторгового товарооборота x с 40 до 40,4 млрд.долл. (т.е. на 1%), величина таможенных платежей возрастет в среднем на 0,84% прежнего уровня; при увеличении x с 50 до 50,5 млрд.долл. (т.е. на 1%) y возрастет на 0,87% и т.д.
9. Теоретическое корреляционное отношение как универсальный показатель тесноты связи. Измерить тесноту связи между коррелируемыми величинами – значит определить, насколько вариация результативного признака обусловлена вариацией факторного (факторных) признака. Ранее были рассмотрены показатели, с помощью которых можно выявить наличие корреляционной связи между двумя признаками x и y и измерить тесноту этой связи. Наряду с ними существует универсальный показатель – корреляционное отношение (или коэффициент корреляции по Пирсону), применимое ко всем случаям корреляционной зависимости независимо от формы этой связи. Следует различать эмпирическое и теоретическое корреляционное отношение. Эмпирическое корреляционное отношение рассчитывается на основе правила сложения дисперсий как корень квадратный из отношения межгрупповой дисперсии к общей дисперсии, т.е.
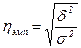 . (144)
. (144)
Теоретическое корреляционное отношение 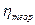 определяется на основе выравненных (теоретических) значений результативного признака
определяется на основе выравненных (теоретических) значений результативного признака 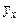 , рассчитанных по уравнению регрессии. представляет собой относительную величину, получаемую в результате сравнения среднего квадратического отклонения в ряду теоретических значений результативного признака со средним квадратическим отклонением в ряду эмпирических значений. Если обозначить дисперсию эмпирического ряда игреков через
, рассчитанных по уравнению регрессии. представляет собой относительную величину, получаемую в результате сравнения среднего квадратического отклонения в ряду теоретических значений результативного признака со средним квадратическим отклонением в ряду эмпирических значений. Если обозначить дисперсию эмпирического ряда игреков через 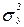 , а теоретического ряда –
, а теоретического ряда – 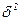 , то каждая из них выразится формулами
, то каждая из них выразится формулами
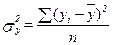 ,
, 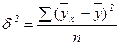 .
.
Сравнивая вторую дисперсию с первой, получим теоретический коэффициент детерминации:
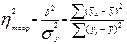 , (145)
, (145)
который показывает, какую долю в общей дисперсии результативного признака занимает дисперсия, выражающая влияние вариации фактора x на вариацию y. Извлекая корень квадратный из коэффициента детерминации, получаем теоретическое корреляционное отношение
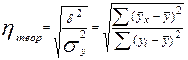 . (146)
. (146)
Оно может находиться в пределах от 0 до 1, чем ближе его значение к 1, тем теснее связь между вариацией y и x. Для оценки тесноты связи обычно применяется шкала Чэддока (таблица 43). Корреляционное отношение применимо как для парной, так и для множественной корреляции независимо от формы связи. В этом смысле его можно назвать универсальным показателем тесноты связи. При линейной зависимости 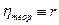 .
.
Покажем расчет 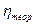 на условном примере. Исходные данные и расчет дополнительных показателей приведен в таблице 46.
на условном примере. Исходные данные и расчет дополнительных показателей приведен в таблице 46.
Таблица 46. Исходные данные и вспомогательные расчеты для нахождения теоретического корреляционного отношения
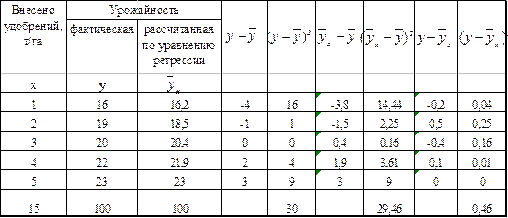
В данном примере общая средняя урожайность: 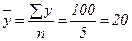 (ц/га).
(ц/га).
Общая дисперсия: 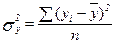 =30/5=6, факторная дисперсия: =29,46/5=5,892.
=30/5=6, факторная дисперсия: =29,46/5=5,892.
Отсюда теоретическое корреляционное отношение: 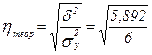 =0,99. Данное значение характеризует очень тесную зависимость изменения урожайности от изменения количества внесенных удобрений. В нашем примере незначительные расхождения (30
=0,99. Данное значение характеризует очень тесную зависимость изменения урожайности от изменения количества внесенных удобрений. В нашем примере незначительные расхождения (30  29,46+0,46 – это правило сложения дисперсий) объясняются округлением значений параметров уравнения регрессии и самих .
29,46+0,46 – это правило сложения дисперсий) объясняются округлением значений параметров уравнения регрессии и самих .
Дата добавления: 2016-02-16; просмотров: 1418;