ПРИМЕЧАНИЕ------------------------------------------------------------------------------------------------------
Для того чтобы понять, как сильно нагревается микропроцессор даже в простом персональном компьютере, не надо быть специалистом: достаточно жарким летним днем попытаться поработать, положив ноутбук на колени. Через 15-20 минут вы в полной мере поймете, насколько близко к технологическим пределам подошла микропроцессорная техника.
Таблицы 12.3 и 12.4. достаточно точно характеризуют современное положение на рынке микропроцессорных устройств. Естественно, в эти таблицы попали только фирмы-лидеры и только лучшие образцы современных микропроцессоров. Несмотря на неполноту этих данных, по ним можно отметить как уровень, на котором находится микропроцессорная техника, так и направления, в которых она развивается.
Таблица 12.3. Микропроцессоры для персональных компьютеров и рабочих станций
|
Таблица 12.4. Микропроцессоры для серверов
|
Сведения, содержащиеся в этих двух таблицах, достаточно ясно намечают ближайшие перспективы развития микропроцессоров, на основе которых создаются как персональные компьютеры, так и мощные серверы, или суперкомпьютеры. Все эти перспективы разворачиваются в первую очередь в сторону попыток обойти физические и технологические ограничения, сдерживающие рост производительности процессоров.
□ Повышение количества ядер. На одном кремниевом кристалле создается не один процессор, а несколько. При этом, в зависимости от выбранной разработчиком архитектуры процессора, эти несколько процессоров могут совместно, зависимо использовать общие, расположенные на одном кристалле ресурсы (таким образом повторяя в каких-то чертах структуру построения суперкомпьютеров) для повышения производительности, или могут быть настолько независимы друг от друга, чтобы на каждом из них одновременно можно было запустить свою операционную систему. Такая схема используется в процессорах Intel, что делает возможным эффективное применение технологии виртуализации.
□ Увеличение разрядности. Постепенно происходит переход от 32-разрядных процессоров к процессорам с 64-разрядной шиной. Для серверных процессоров это уже де-факто стандарт, для процессоров персональных компьютеров это реализованная на уровне процессора возможность. Надо заметить, что повышение разрядности вдвое не означает повышения вдвое производительности компьютера в целом. Однако для решения некоторых задач, требующих массированной обработки данных, это именно так.
□ Автонастройка. Все больше процессоров оснащаются встроенными механизмами регулирования производительности, контроля температурного режима, энергопотребления и производительности в зависимости от загруженности процессора.
□ Многопоточность ядра. Ядра процессоров получают возможность образовывать внутри себя несколько независимых потоков команд и выбирать тот, который в данный момент будет выполняться.
□ System-On-Chip. Целый комплекс задач, который раньше решался сочетанием аппаратных средств и средств операционной системы, теперь решается непосредственно в мультипроцессорном кристалле. Это на порядок повышает скорость выполнения многих функций за счет сокращения числа обращений к системной шине и облегчает программирование многих приложений (например, если шифрование данных является встроенным).
□ Встроенные механизмы интеграции и масштабирования. Этим отличаются в основном серверные микропроцессоры; в их конструкцию изначально закладываются средства работы в «больших микропроцессорных коллективах», из которых собираются мощные серверы и суперкомпьютеры.
Суперкомпьютеры
Микропроцессорные устройства довольно близко подошли к технологическому пределу как своей миниатюризации, так и увеличения тактовой частоты. Самые производительные на сегодняшний день процессоры обеспечивают вычислительную мощность меньше одной четырехтысячной самого производительного суперкомпьютера. Каким же образом достигается эта невероятная скорость обработки информации? Механизм, при помощи которого удается создавать суперкомпьютеры, этих титанов компьютерного мира, один: параллельные вычисления.
Если между двумя точками пути, AwB, расстояние 100 км и на это расстояние нужно переместить некий пакет с сообщением, то нет никакой разницы, один человек будет его проходить, сотня или тысяча — результат будет одинаков, ускорения не произойдет. Однако если нужно почистить тысячу картофелин, то тысяча человек сработает в тысячу раз быстрее, чем один. То есть существуют такие задачи, которые можно решать параллельно (чистка картошки), и такие, которые решаются только последовательно (преодоление расстояния). К счастью, подавляющее большинство задач в компьютерном мире носят параллельный характер — будь то прием информации от метеорологических спутников, анализ состояния от сотен тысяч детекторов частиц адронного коллайдера или обработка запросов пользователей корпоративной информационной системы. Большинство научных расчетных задач и процессов моделирования также может быть разбито на параллельно выполняемые потоки. Каждая параллельная задача может обрабатываться одним микропроцессором. Таким образом, создание суперкомпьютера может быть сведено к решению следующей задачи: как соединить между собой множество микропроцессоров, чтобы каждый из них выполнял отдельное задание и в то же время они представляли собой единое целое, один микроэлектронный супермозг.
Существуют несколько способов заставить микропроцессоры выполнять параллельные вычисления и множество вариантов классификации этих конфигураций. Наиболее информативной и часто используемой (а также наиболее простой) является классификация Флинна (рис. 12.8).
| Одиночный поток команд (Single Instruction) | Множество потоков команд (Multiple Instruction) | |
| Одиночный поток команд (Single Data) | SISD | MISD |
| Множество потоков данных (Multiple Data) | SIMD | MIMD |
| Рис. 12.8. Классификация Флинна |
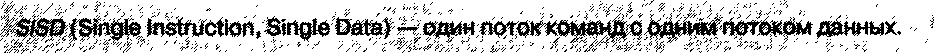
|
К этому классу можно отнести все настольные компьютеры с одним процессором. В этом случае мы имеем одну последовательность инструкций, которую выполняет процессор в одном потоке данных.
В этом классе один поток инструкций выполняется сразу над множеством наборов данных. Такое поведение свойственно векторным процессорам, или векторным машинам. Одна инструкция обрабатывается сразу множеством процессоров, каждым в своей памяти, или одним процессором, но сразу во множестве регистров. Это дает возможность за один такт обработать большой массив данных. Массив однотипных данных составляет вектор, отсюда и название подобного рода процессоров (архитектур).
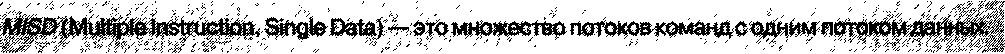
|
Этот класс является пустым, поскольку есть только теоретические предположения о том, как могла бы выглядеть подобная архитектура, но практической реализации ни одной нет.
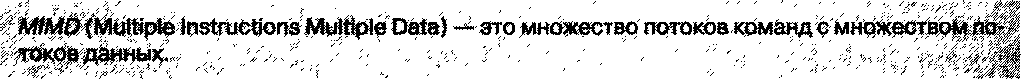
|
В этом классе множество потоков команд выполняется над множеством потоков данных. К данному классу можно отнести практически все современные суперкомпьютеры, оснащенные большим числом микропроцессоров.
Кроме этой классификации есть еще множество других вариантов классикации компьютеров, выполняющих параллельные вычисления и уточняющих диаграмму Флинна. К примеру, очень важным показателем является то, как процессоры, входящие в состав суперкомпьютера, взаимодействуют с памятью.
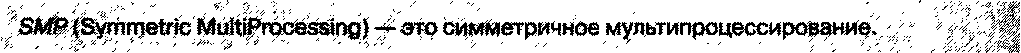
|
Все микропроцессоры, входящие в состав суперкомпьютера, подключены к одному адресному пространству, к одной памяти при помощи специальной высокоскоростной шины памяти. При этом все эти процессоры абсолютно равноправны с точки зрения доступа к любому адресу этой памяти. Эта архитектура дает наибольший выигрыш по производительности, но плохо масштабируется (расширяется) и не может содержать большого количества процессоров, поскольку увеличение количества процессоров приводит к резкому возрастанию вероятности конфликтов при доступе к одним и тем же адресам памяти. Кроме того, сама высокоскоростная шина имеет физические ограничения, не позволяющие наращивать ее объем.

|
В этом случае общей памяти нет. Каждый процессор или модуль с несколькими процессорами является владельцем своего банка памяти, а между процессорами (модулями) устанавливаются соединения, образующие топологию вычислительной системы. Соединения могут быть выполнены как при помощи обыкновенных сетевых устройств, так и посредством специальных вспомогательных компьютеров, предназначенных для высокоскоростной передачи данных (транспьютеров).
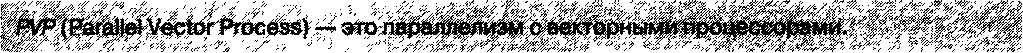
|
Обычно это одна из перечисленных архитектур (SMP, MPP или NUMA), в которой задействованы не обычные скалярные процессоры, а специальные процессоры векторно-конвейрного типа. Это дает возможность эффективным образом организовывать параллельные вычисления любого типа. Недостатком такой архитектуры является большая стоимость как самих процессоров, так и программного обеспечения для организации вычислений.

|
В состав кластера могут входить как специализированные компьютеры, то есть изготовленные специально для организации кластера, так и обыкновенные рабочие станции. Физически кластеры могут быть организованы в одной локальной сети (гомогенная организация) или объединяться через разного рода сетевые соединения, включая Интернет (так называемая гетерогенная структура). Кластерная организация суперкомпьютеров на сегодняшний день является суперпопулярной. Достаточно сказать, что из 500 самых мощных суперЭВМ в мире 400 созданы на основе кластерной архитектуры. И еще несколько важных понятий:
□ Суперскалярный процессор — процессор, который способен выполнить несколько операций за один такт. Естественно, для того чтобы это стало возможным, у суперскалярного процессора должны быть «в подчинении» независимые устройства, которым можно разослать этот пакет команд для обработки.
□ Конвейерная обработка — при такой обработке повторяющаяся последовательность операций делится на ряд подопераций и каждая подоперация выполняется отдельным процессором. В результате получается, что за один такт выполняется не одна, а множество команд.
□ RISC (Reduced Instruction Set Computer) — компьютер с сокращенным набором команд. В результате сокращения в наборе команд процессора остаются только инструкции, которые можно выполнить за 1-2 такта (в то время как в полном наборе команд могут быть инструкции, требующие 4-6 тактов).
| При такой архитектуре несколько процессоров объединяются между собой в SMP-узел, а SMP-узлы, в свою очередь, образуют МРР-архитектуру. |
Одним из важнейших показателей, при помощи которых оценивают суперкомпьютеры, является производительность. Производительность измеряется в количестве операций с плавающей точкой в секунду (Float Point Operation Per Second, FLOPS). Рост этого показателя для суперкомпьютеров сравним с тенденцией роста плотности транзисторов для микропроцессоров. В 2000 г. еще только ставилась задача преодоления барьера в 1 TFLOPS (терафлопс, миллиард флопсов), а в 2008 г. уже был преодолен рубеж в 1 PFLOPS (петафлопс, триллион флопсов).
Современные достижения в суперкомпьютерной технике отслеживает специальный рейтинг пяти сотен самых производительных суперкомпьютеров в мире. В настоящее время 5 первых строчек этого рейтинга занимают американские компьютеры (табл. 12.5).
Таблица 12.5. Первые пять мест рейтинга самых мощных суперкомпьютеров
|
Из этих пяти пунктов видно, что всемирно известный производитель суперкомпьютеров корпорация Cray находится только на пятом месте. Новейший микропроцессор IBM CELL PowerXCell 8i с его гибкой архитектурой, в которой кроме 2 базовых ядер есть еще 8 вспомогательных, работающих как в режиме векторных сопроцессоров, так и в режиме независимых ядер, позволил не только выйти на первое место в рейтинге, но и преодолеть петафлопсный барьер.
| Назначение современных серверов самое широкое: серверы Интернета, серверы телекоммуникационных систем, серверы информационных систем, серверы баз данных. |
В рейтинге top500, благодаря выдвинутым в нашей стране приоритетам на оснащение суперкомпьютерами университетов и научных центров, присутствие России увеличивается каждый месяц. На сегодняшний день в рейтинге уже 9 российских суперкомпьютеров, причем лучший из них занимает 36-е место (СКИФ МГУ).
Дата добавления: 2016-04-14; просмотров: 862;