Обробка та аналіз соціальної інформації
Опис інформації та обчислення узагальнюючих параметрів
В емпіричній соціології нагромаджено немало статистичних процедур, за допомогою яких розрізнені дані, що містяться в окремих анкетах чи інших матеріалах соціологічних досліджень, адаптують для узагальнення, опису, аналізу, наукової інтерпретації. За результатами узагальнень складають певні висновки, вирішуючи завдання, поставлені у дослідженні. Внаслідок цих процедур з'являється реальна змога з'ясувати тенденції у досліджуваних процесах, явищах, виробити прогнози і практичні рекомендації, що відкривають вихід соціальної інформації у соціальну практику. Найчастіше статистичні методи аналізу соціальної інформації використовують для:
— опису інформації та обчислення узагальнюючих параметрів (одновимірна статистика);
— виміру зв'язку між окремими ознаками, отриманими у відповідях на різні запитання анкети, якщо як метод збору даних застосовувалося опитування, або контент-аналіз текстів ЗМІ, якщо використовувався метод аналізу документів (двовимірна статистика);
— проведення складних математичних процедур, які дають змогу проаналізувати водночас кілька взаємопов'язаних ознак (багатовимірна статистика).
Застосування методів математичної статистики забезпечує:
— стислий опис первинної соціологічної інформації, обчислення одновимірних розподілів, наочне уявлення її у вигляді таблиць, графіків, діаграм;
— обчислення зв'язків між ознаками досліджуваного суспільного явища, оцінку їх за допомогою статистичних коефіцієнтів зв'язку, застосування кореляційного, регресійного аналізу тощо;
— встановлення латентних (прихованих) факторів, які визначають взаємозв'язки всередині групи, ознак досліджуваного явища (факторний, латентно-структурний аналіз);
— класифікацію ознак та об'єктів, побудову типологій (кластерний аналіз, дискримінантний аналіз, факторний аналіз);
— перевірку (підтвердження чи спростування) вихідних гіпотез дослідження, формулювання нових проблем;
— вироблення коротко- і довгострокових прогнозів щодо функціонування та розвитку певного суспільного явища.
Використання методів математичної статистики передбачає певний набір попередніх процедур, до яких належать: підготовка анкети, іншого первинного матеріалу до обробки, яка може здійснюватися вручну чи автоматизовано; вибір рівня майбутнього аналізу (описовий чи пояснювальний); вибір конкретних статистичних процедур для обробки інформації.
В емпіричному дослідженні соціолог вивчає певну множину об'єктів, наприклад, колектив працівників підприємства. Кожному елементу множини притаманні певні властивості (ознаки), скажімо, стать, вік, задоволеність умовами праці. Кожний об'єкт має певне значення за кожною ознакою. Так, працівник має одне з двох можливих значень ознаки «стать» (чоловіча або жіноча), одне з трьох можливих значень ознаки «задоволеність умовами праці» (задоволений, не зовсім задоволений, зовсім незадоволений), певне значення ознаки «вік» (число повних років від 18 до 80) та ін.
Як правило, для спрощення обробки всі значення ознак кодують числами, тому дані для обробки становлять прямокутну таблицю (матрицю) чисел. Кожний рядок цієї таблиці відповідає одному об'єкту, а кожний стовпчик — певній ознаці. На перетині певного рядка та стовпчика цієї таблиці знаходиться значення певної ознаки певного об'єкта.
Ознаки поділяють на якісні та кількісні. Якісні ознаки не мають кількісного виразу («стать», «задоволеність умовами праці»). Кількісні ознаки мають одиниці вимірювання. Наприклад, одиницею вимірювання кількісної ознаки «вік» є рік, «заробітна плата» — гривня. Ці ознаки ще називають ознаками, заданими у метричній шкалі.
При кодуванні значень якісної ознаки числами можливі два суттєво відмінні варіанти. У першому значення якісної ознаки можна впорядковувати, тобто для будь-якої пари значень можна зазначити, яке з них відповідає сильнішому виявленню ознаки. Наприклад, значення «задоволений» відповідає інтенсивні-шому виявленню ознаки «задоволеність умовами праці», ніж значення «не зовсім задоволений». У такому разі доцільно і числові коди добирати так, щоб сильнішому виявленню ознаки відповідало більше число. Так, для ознаки «задоволеність умовами праці» можна обрати такі числові коди значень: 3 — «задоволений»; 2 — «не зовсім задоволений»; 1 — «зовсім незадоволений». Такі якісні шкали ще називають порядковими шкалами, або шкалами рангів. У другому випадку значення якісної ознаки не піддаються жодному змістовному впорядкуванню. Наприклад, ознака «стать» містить два значення — «чоловіча» та «жіноча». Для значень ознак такого типу можна добирати будь-які числові коди. Головне — щоб різні значення мали різні коди (тобто не можна кодувати два різні значення ознаки одним числом). Такі якісні шкали ще називають номінальними шкалами. Як правило, для кодування значень ознак у номінальних шкалах використовують цілі додатні числа — 1, 2, 3 і т. д.
Соціологові постійно доводиться при складанні програми дослідження обирати (або навіть самостійно конструювати) шкали. Від того, наскільки вдало це буде зроблено, значною мірою залежить результат опрацювання отриманих даних. Крім того, вибір математичного методу аналізу даних тісно пов'язаний зі шкалами відповідних ознак. Якщо такий метод не відповідає даним, це дуже суттєва методична помилка, що може звести нанівець роботу зі збору даних та обчислення результатів.
Щоб первинні дані можна було використовувати для змістового аналізу і висновків, вони повинні бути незалежно упорядковані та опрацьовані. З цією метою застосовують спеціальні статистичні методи — групування, обчислення узагальнюючих параметрів та коефіцієнтів, кореляційний, кластерний, факторний аналізи та ін. Незалежно від методу аналізу, опрацювання даних починають з попереднього впорядкування інформації, здебільшого за допомогою статистичного групування та побудови статистичних таблиць.
Структуру сукупності об'єктів з точки зору однієї виокремленої ознаки доцільно вивчати за таблицею, в якій для кожного з можливих значень ознаки зафіксовано, скільки разів зустрічаються в сукупності об'єкти, що мають відповідне значення. Таку таблицю називають таблицею одновимірного розподілу, однови-мірною таблицею, варіаційним рядом. Наприклад, для ознаки «задоволеність умовами праці» одновимірна таблиця може мати такий вигляд:
Таблиця 7
Ознака: «Задоволеність умовами праці»
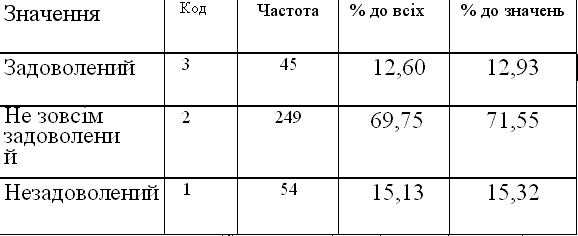
Кількість об'єктів — 357. Для 348 об'єктів (що становить 97,48% від загальної сукупності) відоме значення ознаки «задоволеність умовами праці». Для інших об'єктів сукупності (в даному разі їх 9) значення цієї ознаки невідоме (наприклад, інформація зібрана методом опитування, і деякі працівники підприємства не захотіли відповідати на поставлене питання). Аналіз таблиці свідчить, що задоволених умовами праці — 45 (12,60% від загальної сукупності та 12,93% від кількості працівників, які відповіли на поставлене запитання). Переважна більшість працівників повністю або частково не задоволена умовами праці.
В одновимірній таблиці часто перший або другий стовпчики відсутні (тобто в таблиці зазначають або самі значення, або їх коди);
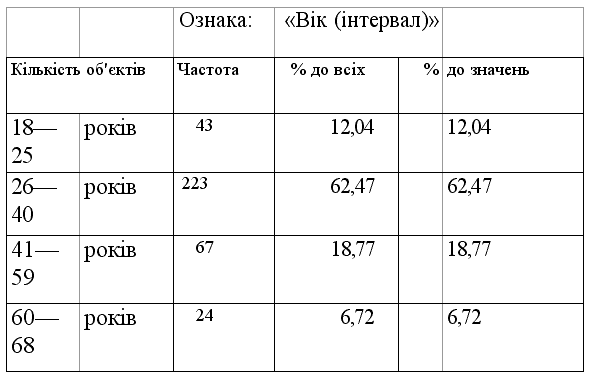
Неможливо перелічити всі можливі значення ознак, заданих у метричних шкалах. Отже, неможливо і безпосередньо побудувати одновимірну таблицю. За таких обставин усі можливі значення ознаки розбивають на інтервали, а потім будують таблицю. Так, для сукупності працівників даного підприємства всі значення ознаки «вік» перебувають між віком наймолодшого робітника (припустимо, 18 років) та віком найстаршого робітника (припустимо, 68). Розіб'ємо їх на 4 інтервали: від 18 до 25 років, від 26 до 40 років, від 41 до 59 років та від 60 до 68 років. Тоді одновимірна таблиця, що демонструє структуру сукупності працівників за віком, матиме такий вигляд:
Таблиця 8
казники варіації ознак. Для кількісних ознак — це дисперсія, середнє квадратичне відхилення, коефіцієнт варіації. Для якісних ознак розроблені спеціальні індекси якісної варіації. Чим більше значення відповідного показника варіації, тим розсіяніші навколо середнього значення реальні значення ознаки, а отже, тим з більшою обережністю потрібно оперувати із середнім значенням при побудові змістових висновків.
Межі варіації також дають змогу оцінити, наскільки однорідною за певною ознакою є сукупність. Якщо сукупність за певною ознакою неоднорідна, може постати потреба поділити цю сукупність на кілька однорідних за цією ознакою частин та аналізувати кожну з них окремо. Припустимо, що вивчається задоволеність умовами праці на певному підприємстві. З логічних міркувань або за результатів попередніх досліджень відомо, що заробітна плата працівника впливає на його задоволеність умовами праці. Нехай коефіцієнт варіації заробітної плати для всієї сукупності працівників дорівнює 0,7. Тоді необхідно поділити всю сукупність працівників на групи, приблизно однакові за рівнем заробітної платні (щоб у кожній групі коефіцієнт варіації зарплати був нижчим від 0,4), та аналізувати задоволеність умовами праці окремо у кожній з них.
У цій таблиці відсутній стовпчик, в якому зазначені коди інтервалів, а оскільки відомий вік усіх працівників (є відповідні значення для всіх об'єктів), тому третій і четвертий стовпчики збігаються. Метрична ознака розбита у даній таблиці на різні за розміром (нерівномірні) інтервали. А нерідко доцільно розбивати весь діапазон значень на інтервали однакової довжини (рівномірні інтервали).
Для полегшення аналізу великої кількості таблиць та забезпечення можливості порівняння кількох з них обчислюють узагальнюючі характеристики рядів розподілу. Найчастіше використовують характеристику «середнє значення ознаки». Для кількісної ознаки обчислюють її середнє арифметичне значення щодо всіх об'єктів сукупності. Для якісних ознак такою узагальнюючою характеристикою ряду є «мода» — значення, що найчастіше зустрічається в одновимір-ній таблиці.
Коефіцієнт зв'язку між двома ознаками. Кореляційний і регресійний аналіз
Одним з важливих завдань аналізу є встановлення та оцінка взаємозв'язків між окремими ознаками для певної сукупності об'єктів. Цю роботу починають з побудови кореляційних таблиць (таблиць спряженості двох ознак, двовимірними таблицями). Вони дають змогу впорядковувати інформацію про розподіл сукупності об'єктів за двома ознаками. Такі таблиці мають прямокутну форму. Кількість рядків у них дорівнює кількості можливих значень однієї ознаки, а кількість стовпчиків — кількості можливих значень другої ознаки. У таблиці 9 у клітинці на перетині другого рядка і третього стовпчика знаходиться число 42 (в центрі клітинки) — кількість робітниць (значення ознаки «стать» — «жіноча»), що незадоволені умовами праці (значення ознаки «задоволеність умовами праці» — «незадоволений»).
Таблиця 9
Двовимірна таблиця (ознаки «Стать» та «Задоволеність умовами праці»)
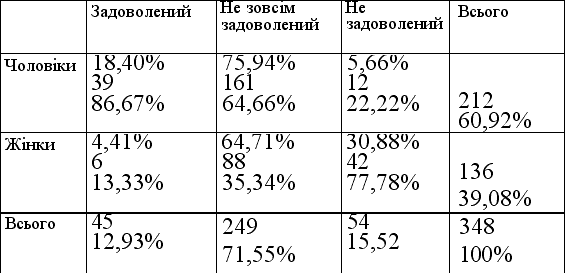
Крім того, двовимірна таблиця, як правило, містить ще один додатковий стовпчик і ще один додатковий рядок — так звані маргінальні стовпчик і рядок. У таблиці маргінали позначені словом «Всього». Кожна клітинка маргінального стовпчика містить суму чисел відповідного рядка, тобто кількість об'єктів, що мають відповідне значення першої ознаки (незалежно від того, якого значення для цих об'єктів набуває друга ознака), а також відсоток, який становить це число щодо загальної кількості об'єктів. Так, з маргінального стовпчика таблиці бачимо, що на підприємстві працює 136 жінок (39,08% загальної кількості працюючих). Маргінальний рядок містить відповідні суми стовпчиків таблиці.
У кожній клітинці таблиці, як правило, записують відсоток стосовно відповідного значення в маргінальному стовпчику (цей відсоток записують вище від самого числа) та відсоток стосовно відповідного значення в маргінальному рядку (записують нижче від числа). Якщо знову повернутися до клітинки в другому рядку третього стовпчика таблиці, побачимо, що кількість незадоволених умовами праці жінок (таких на підприємстві 42) становить 30,88 % від загальної кількості жінок (всього на підприємстві 136 жінок) та 77,78% від загальної кількості незадоволених умовами праці (всього умовами праці на підприємстві не задоволені 54 працівники).
Числа в таблиці свідчать, що серед жінок відсоток незадоволених умовами праці на підприємстві значно вищий, ніж серед чоловіків. Отже, є підстави для гіпотезіи, що стать працівника та його задоволеність умовами праці взаємопов'язані.
Вміння читати двовимірні таблиці приходить з досвідом. Нелегко знаходити закономірності в досить великих за розміром таблицях. Крім того, далеко не завжди зв'язок між ознаками простежується. Тому на практиці наявність зв'язку між двома ознаками встановлюють за допомогою так званого критерію %2, який базується на аналізі частот, записаних у клітинках таблиці. Це дає змогу дійти висновків про те, чи можна висувати та аналізувати гіпотезу про наявність зв'язку між двома ознаками.
Застосовуючи зазначений критерій, необхідно обчислити коефіцієнт хі-квадрат за формулою (формула залежить від частот у клітинках таблиці та маргінальних частот), а одержане значення порівняти з табличним (критичним). При цьому слід мати на увазі певний рівень значущості (ймовірність прийняття хибного рішення) — в соціології, як правило, 0,05 або 0,01. Крім того, табличне значення залежить від кількості ступенів свободи, що визначають за кількістю рядків і стовпчиків таблиці. Отже, для заданого рівня значущості та кількості ступенів свободи необхідно знайти в таблиці критичне значення і порівняти його з обчисленим. Якщо обчислене значення більше від критичного, то факт існування зв'язку можна вважати встановленим.
Силу зв'язку можна оцінити обчисленням та аналізом коефіцієнтів спряженості (Пірсона, Чупрова, Крамера). Значення цих коефіцієнтів перебувають в інтервалі від нуля до одиниці та мають такий зміст: чим ближче значення до одиниці, тим тісніший зв'язок. Якщо обидві ознаки, між якими вивчають зв'язок, мають лише по два значення (тобто фіксують наявність або відсутність даної ознаки в об'єкті), то для таких «чотириклітинкових» таблиць обчислюють коефіцієнти асоціації та контингенції.
Якщо певному значенню однієї величини відповідає сукупність значень другої, то між цими двома величинами існує кореляційний зв'язок. Він виявляється тоді, коли на досліджуване явище впливає не один, а багато чинників. Наприклад, стаж впливає на продуктивність праці, але не остаточно визначає її, бо залежить від рівня освіти, віку, кваліфікації працівника та інших факторів. Оскільки явища суспільного життя складні та багатофакторні, зв'язок між ознаками в соціології практично завжди кореляційний.
Якщо кожному значенню однієї ознаки відповідає сукупність значень другої ознаки, близько розміщених біля свого середнього значення (тобто всі значення сукупності не дуже відрізняються від свого середнього арифметичного), то такий кореляційний зв'язок вважають сильнішим. Кількісно силу кореляційного зв'язку оцінюють за допомогою коефіцієнтів кореляції.
Для кількісних ознак часто використовують коефіцієнт Пірсона (г), який оцінює силу зв'язку за лінійної кореляції (тобто в припущенні, що значення однієї ознаки пов'язані з відповідними середніми другої ознаки лінійною залежністю). Всі значення коефіцієнта кореляції Пірсона належать інтервалу від -1 до 1. Знак коефіцієнта показує напрям зв'язку: додатне значення свідчить про «прямий» зв'язок (зростання однієї ознаки зумовлює зростання другої), від'ємне значення — про «зворотний» зв'язок, а значення «О» — про відсутність лінійного кореляційного зв'язку. Наприклад, зв'язок між заробітною платою робітника та кількістю виготовлених ним деталей — прямий, а між заробітною платою та кількістю бракованих деталей — зворотний. При г =1 або г = -1 маємо функціональний зв'язок між ознаками (тобто кожному значенню однієї ознаки відповідає одне значення другої ознаки і ці значення пов'язані лінійною залежністю). Отже, чим далі значення коефіцієнта Пірсона від нуля (чим більша його абсолютна величина), тим тісніший лінійний кореляційний зв'язок існує між ознаками. Але якщо г = 0, то це означає відсутність лише лінійного зв'язку, а не відсутність зв'язку між ознаками взагалі: зв'язок може існувати, але нелінійний. Для оцінювання сили нелінійного зв'язку використовують кореляційне відношення, що набуває значення між 0 та 1 (0 означає відсутність зв'язку, 1 — функціональний зв'язок).
Для ознак, заданих у порядкових шкалах, обчислюють рангові коефіцієнти кореляції (Спірмена та Кендела), які також набувають значення між -1 та 1 та інтерпретуються так само, як і коефіцієнт кореляції Пірсона.
Встановлення кореляції між двома ознаками ще не означає встановлення причинного зв'язку між ними. Це лише свідчення того, що одна з ознак частково спричинила іншу або обидві ознаки і є наслідком деяких спільних для них причин. Зауважимо, що кількісна оцінка кореляційних зв'язків не може замінити спеціальних знань, але може допомогти дослідникові відкинути несуттєві зв'язки, чіткіше окреслити напрям пошуків, порівняти вплив різних чинників тощо. Крім того, коефіцієнти часткової кореляції дають змогу оцінити зв'язок між двома ознаками, усуваючи вплив однієї або кількох інших ознак. Якщо після усунення впливу третьої ознаки коефіцієнт кореляції між двома ознаками збільшується, то третя ознака послаблює зв'язок, а якщо зменшується, то саме ця третя ознака певною мірою спричиняє наявність цього зв'язку (тобто зв'язок, можливо, є лише наслідком впливу цієї третьої ознаки). Обчислити коефіцієнти часткової кореляції досить складно через коефіцієнти кореляції Пірсона. Обсяг обчислень зростає з кількістю тих ознак, вплив яких бажають усунути. Силу спільного зв'язку сукупності ознак дає змогу оцінити коефіцієнт множинної кореляції.
Методи регресійного аналізу забезпечують не тільки оцінку сили зв'язку між двома ознаками, а й встановлення виду цього зв'язку у вигляді рівняння (рівняння регресії), що описує залежність між середнім значенням однієї ознаки (залежної, поведінку якої вивчають) та значеннями певної сукупності ознак (незалежних, вплив яких на залежну ознаку намагаються оцінити). У соціологічних дослідженнях, як правило, відбувається пошук такої залежності у лінійному вигляді (у вигляді лінійного рівняння), тому йдеться про рівняння багатовимірної (множинної) лінійної регресії.
Знання залежності у вигляді рівняння дає змогу не тільки пояснювати поведінку залежної ознаки, а й прогнозувати її значення за різних змін значень незалежних ознак. Наприклад, на основі аналізу факторів, що впливають на рівень заробітної плати на підприємстві, було побудовано рівняння лінійної регресії: у = 4,27 xt ■ 1,83 х -9,20. Воно описує зв'язок між заробітною платою у (залежна ознака, вимірюється в гривнях) і двома незалежними ознаками працівника: стаж Xj (вимірюється в роках) та освітній рівень х2 (вимірюється в роках). Аналіз цього рівняння наводить на думку, що зростання трудового стажу працівника на один рік зумовлює зростання його середньої заробітної плати на 4,27 грн., а зростання освітнього рівня на один рік — зростання середньої заробітної плати лише на 1,83 грн. Отже, на даному підприємстві трудовий стаж суттєвіше впливає на середню заробітну плату працівника, ніж його освітній рівень. Якість рівняння регресії (наскільки точно рівняння регресії описує зв'язок між ознаками) оцінюють коефіцієнтом множинної кореляції.
Суттєвим для одержання надійних, статистично обґрунтованих результатів є оцінка значущості статистичних показників. Це — комплекс математичних процедур, що дають змогу відповісти на низку питань щодо розрахованих статистичних показників і параметрів вибіркової сукупності. Так, обчисливши коефіцієнт кореляції між двома ознаками та одержавши число, що не дорівнює нулю, цілком логічно постають запитання: чи справді цей коефіцієнт суттєво відрізняється від нуля (а отже, фіксує наявність лінійного кореляційного зв'язку), чи ця різниця випадкова і спричинена лише похибкою нашої вибірки? Відповідь на них можна дати, оцінивши значущість відмінності коефіцієнта кореляції від нуля і звернувши особливу увагу на обсяг вибірки та рівень значущості (ймовірність прийняття хибного рішення). Ця процедура така ж, як і процедура застосування критерію х2> і дає змогу обчислити за певною формулою критерій. Одержане ж значення порівнюється з табличним. На основі результатів порівняння і робиться висновок.
Крім оцінки значущості відмінності від нуля коефіцієнта кореляції між двома ознаками, часто застосовують і процедури оцінки значущості різниці між двома відсотками (наприклад, різниці між відсотками не-задоволених умовами праці на даному підприємстві серед жінок і чоловіків), різниці між двома середніми (між середньою заробітною платою на одному та іншому підприємствах), двох коефіцієнтів кореляції. Для кожної такої задачі існують формула обчислення критерію та статистичні таблиці, якими користуються для порівняння.
Методи багатовимірної статистики: факторний і кластерний аналіз
Якщо аналіз даних передбачає використання великої кількості взаємопов'язаних ознак, доцільно застосувати спеціальні методи та алгоритми багатовимірної статистики. Ці методи потребують значних обчислень, для ефективного застосування яких необхідно мати обчислювальну техніку та спеціальне програмне забезпечення. Серед методів багатовимірної статистики найуживанішими є факторний та кластерний аналіз.
Суть факторного аналізу полягає в тому, що групу сильно скорельованих ознак можна пояснити та описати невеликою кількістю прихованих (латентних) факторів, які безпосередньо не спостерігаються, але розкривають значення ознак цієї групи. Наприклад, за такими ознаками, як «кількість прочитаних книг», «кількість книг у домашній бібліотеці», «кількість відвідувань театрів і музеїв», приховано фактор, який можна було б назвати «рівень культурного розвитку особистості». Факторний аналіз дає змогу виявити ці латентні фактори, описати залежність між ними та первинними ознаками, обчислити значення всіх побудованих таким чином факторів для кожного об'єкта. В результаті виникає можливість без значних втрат інформації перейти від аналізу великої кількості первинних ознак до аналізу порівняно невеликої кількості факторів.
Алгоритми кластерного аналізу дають змогу поділити сукупність об'єктів на однорідні за певним формальним критерієм подібності групи (кластери). Основною властивістю цих груп є те, що об'єкти, які належать одному кластеру, подібніші між собою, ніж об'єкти з різних кластерів. Таку класифікацію можна виконувати одночасно за досить великою кількістю ознак. Наприклад, відомо чимало статистичних показників, які характеризують рівень соціально-економічного розвитку адміністративних районів країни: кількість населення, кількість безробітних, протяжність шосейних доріг, кількість квадратних метрів житла на одну людину тощо. Для організації опитування необхідно згрупувати райони у більші утворення (регіони), але варто зробити це так, щоб у кожному такому регіоні були райони, близькі за своїм соціально-економічним розвитком. Це дасть змогу вибрати в такому регіоні один типовий район і результати опитування в ньому узагальнити щодо всього регіону. Таке групування може бути ефективно проведене методом кластерного аналізу, оскільки у даному разі враховується та узагальнюється велика кількість показників.
Підсумок аналізу та інтерпретації соціологічних даних набуває форми документів: звіту за результатами дослідження, інформаційної чи аналітичної довідки. Вони містять відомості, висновки та рекомендації для прийняття практичних (управлінських) рішень. У науково-дослідному плані — це банк соціологічних даних наукового аналізу.
Дата добавления: 2016-04-11; просмотров: 685;