ПОПУЛЯЦИИ И СХЕМЫ ОТБОРА
Остается одна проблема перед тем, как мы будем готовы объяснить то, что мы видим в нашем путешествии. Теперь в нашем распоряжении есть пространственный язык, который дает нам знание о том, где и что искать, когда мы исследуем наше окружение.
И мы знаем об устройствах, которые позволяют нам собирать большие объемы данных с помощью спутников. Но сложность нашей планеты может часто становиться подавляющей просто потому, что существует так много объектов и так много факторов, которые могут быть подвергнуты исследованию. И хотя приборы дистанционного зондирования позволяют нам видеть большие территории одним взглядом, разрешение, при котором они снимают землю, часто ограничивает размеры объектов, которые мы можем увидеть. Некоторые объекты, например, норы животных в степи, находятся далеко за пределами видимости многих приборов. А поскольку такие объекты разбросаны по большой территории, получение детальных аэрофотоснимков оказывается чрезмерно дорогим. Поэтому нам придется выполнять наши наблюдения и оценки на земле. И это возможно, поскольку интересующие нас объекты достаточно многочисленны, чтобы визуально доминировать на ландшафте. Но их слишком много, чтобы мы могли учесть каждый и записать его координаты. Чтобы выяснить, почему эти объекты имеют определенное распределение, нужно прежде всего знать, что некоторое распределение существует, что в идеале выполняется поиском и записью местоположений объектов. Но поскольку мы не можем создать полную перепись всех нор, мы должны отобрать некоторую из них, то есть сделать выборку (sample), для того, чтобы получить выводы обо всей популяции на основе меньшего, представительного подмножества.
Выборки могут производиться разными путями; некоторые из них труднее других, некоторые дают лучшую возможность делать выводы о популяции в целом. Хотя выборки эффективны как для пространственных, так и для непространственных данных, мы ограничимся только пространственными, так как ГИС имеют дело с явно пространственной информацией. Мы выбираем данные двумя главными способами: направленным и ненаправленным отбором (directed and nondirected sampling). Каждый метод определяется как ограничениями на получение пространственных данных, так и выводами, которые мы хотим получить о популяции данных при использовании выборок.
Направленная выборка, как подразумевает название, требует принятия решений о том, какие объекты должны быть просмотрены и позднее внесены в список. Другими словами, мы направляем наш отбор на основе нашей возможности брать образцы изизучаемой совокупности объектов. Изучаемая совокупность занимает некоторуюобласть отбора, в пределах которой мы делаем выборку [McGrewand Monroe, 1993]. Вместе, изучаемая совокупность и область отбора составляютбазу выборки, которая включает типы интересующих нас объектов, ограниченных определенными
пространственными координатами. В рамках направленного выбора, иногда называемого целевым, мы используем совместно знание исследуемой области и ее изучаемой совокупности, доступности объектов, которые мы желаем исследовать, вероятности получения адекватной информации о каждом индивиде (например, используя только данные опросных форм от людей, которым они были посланы), и исследования конкретных ситуаций с целью демонстрации определенного феномена. Хотя этот метод выборок часто называют "ненаучным", он все же часто необходим. Рассмотрим следующие ситуации.
Вы планируете пространственное исследование типов растительности для территории, которая была расчищена от растительности, использована в сельском хозяйстве, а затем заброшена. Вам известен некоторый большой участок, который прошел через эти этапы, и поэтому вы планируете исследовать его вместо всех участков в вашем регионе или государстве, которые находятся в аналогичных условиях. Ваше исследование является более сосредоточенным, поскольку добраться до всех участков, подвергнутых очистке и забвению, было бы невозможно. Посетив один такой, вы обнаруживаете, что половина его окружена колючей проволокой, и владелец не желает, чтобы вы шатались по его собственности. Площадь вашего исследования еще более ограничивается. Вдобавок вы узнаете, что многие из имеющихся участков недоступны для транспорта. Теперь вам приходится сосредоточить исследование только на регионах в разумной удаленности от дорог. Таким образом, вам пришлось сосредоточиться на небольшом тестовом участке, прошедшем интересующий вас путь, и вам приходится ограничивать даже его из-за проблемы доступа. Такая ситуация типична и она ограничивает стратегию отбора (sampling strategy).
Другая ситуация уже упоминалась в связи с использованием исследований популяций. Если, например, вы желаете определить пространственную распространенность пользователей кабельного телевидения и узнать, какие программы они смотрят, вы применяете обычный метод исследования, состоящий из набора вопросов о том, какие программы смотрят респонденты. Вопросники рассылаются жителям вашего города (целевая область). Однако вам нужно помнить, что некоторые люди не имеют телевизора, а многие имеющие их не подписываются на кабельные программы. Вы же хотите опросить только тех, кто смотрит кабельные программы (ваша изучаемая совокупность), возможно связавшись с кабельными компаниями с целью получить списки их клиентов, желающих принять участие в опросе. Составив список респондентов, вы посылаете каждому опросный лист с просьбой ответить на вопросы и указанием, как вам его вернуть. Поскольку большинство из нас получали такие анкеты, нам известно, что многие потенциальные респонденты их не возвращают. Очень вероятно, что в вашем случае произойдет то же самое. Что вам осталось, так это направленная выборка, сосредоточенная только на тех пользователях кабельного телевидения, которые вернули вам анкеты.
Можно привести много других примеров, но каждому из вас придется принимать решения на основе собственной ситуации. Хотя ненаправленный, вероятностный отбор (nondirected, probability-based sampling) в общем случае более предпочтителен, поскольку он устраняет систематическую ошибку, смещение (bias) получаемых оценок, иногда этот подход будет невозможен. Перед тем как начать процедуру отбора, попытайтесь определить, возможен ли сбор данных средствами вероятностной процедуры отбора. Только в том случае, когда это невозможно, вы должны обращаться к направленному отбору.
Если у вас есть возможность использования вероятностного пространственного отбора, каждый объект, выбираемый из базы выборки, предполагается имеющим известную вероятность отбора для исследования. Эта вероятность используется для построения процедуры отбора. Иначе говоря, вы используете известную вероятность для установления метода отбора, который обеспечит всем объектам равную вероятность попадания в выборку.
Методы вероятностного отбора могут быть легко разбиты на четыре общие категории: случайный, систематический, стратифицированный и однородный отбор (random, systematic, stratified, homogeneous sampling) (Рисунок 2.12). Конечно, они могут быть скомбинированы для образования гибридного метода организации выборки, если это нужно, однако сейчас мы рассмотрим только простейшие виды, которые вы сможете модифицировать позже при подходящих условиях. Случайный отбор является самым основным методом. Его целью является обеспечение каждому отдельному точечному, линейному, площадному или поверхностному объекту такой же вероятности отбора, как и соседнему. Если пространственные данные, которые вы отбираете, дискретны, такие как деревья, озера, или люди, то вашей целью является наблюдение за некоторыми из них, выбранными случайно. В таких случаях каждый объект получает уникальный номер, скажем от 1 до 1000. С помощью генератора случайных чисел, имеющегося почти во всех компьютерах и многих карманных калькуляторах, или набора таблиц случайных чисел, достаточно легко выбрать часть из них, опять же случайно. Мы могли бы, например, отобрать 100 из 1000 номеров пространственно распределенных объектов для измерения.
Если же данные являются непрерывными, такими как в случае рельефа, атмосферного давления или температуры почвы, мы случайным образом выберем точки, в которых можно измерить эти величины и перенумеруем их, выбрав точки для исследования как и прежде. В обоих случаях возможен выбор случайных точек, случайных областей, называемых квадратами (они часто используются для определения количества надземной биомассы трав) или пересечений линиями для использования в отборе объектов изучения.
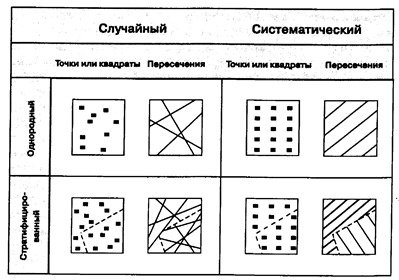
Рисунок 2.12. Методы пространственного отбора. Случайная, систематическая, послойная и однородная схемы отбора.
Систематические схемы действуют почти так же, как и случайные, но сейчас в качестве основы отбора мы используем повторяющийся шаблон вместо случайных чисел. Для точечных данных мы могли бы, например, выбрать каждое десятое дерево, или деревья, расположенные примерно в двадцати метрах друг от друга. Для исследования небольших делянок или квадратов мы выбирали бы их таким же образом — каждый энный или через каждые n метров. Аналогично, если мы используем пересечения линий для отбора, популярный метод для исследования растительных ассоциаций, мы могли бы по системе определить, где окажется каждое пересечение, и сделать перепись растительности вдоль каждой такой секущей линии. Или, если мы желаем полностью осмотреть отдельные делянки или квадраты, мы можем опять же выбрать их, используя систематический, повторяющийся шаблон отбора каждого квадрата для исследования.
Стратифицированный пространственный отбор вносит дополнительное измерение выбором малых областей, внутри которых отбираются отдельные ячейки или объекты. Стратифицирование упрощает процесс взятия проб через разделение всей задачи на малые области, которые могут, например, быть исследованы одним человеком или за один день взятия выборок (опробывания). Внутри каждого слоя мы можем решить, какой метод использовать - случайный или систематический. Есть модификация этого метода, в которой мы вначале определяем, сгруппированы объекты исследования, или они рассеяны по всей области исследования. Затем каждая из этих групп может быть выбрана в качестве подобласти исследования, наподобие того, как мы поступали при разбиении на слои всей нашей области исследования. Опять же, мы можем использовать подходы с точками, квадратами или секущими и выбирать систематический или случайный метод опробывания внутри каждой подобласти.
Этот подход имеет определенное преимущество в случаях, когда однородность объектов обусловлена неким процессом. Выбор подобластей для индивидуального изучения может дать нам более детальные сведения об этом процессе, нежели рассмотрение всей области исследования как целого, в случае чего мы подразумеваем, что на всем исследуемом пространстве в действующих процессах практически нет вариаций. Однако, этот подход имеет и трудность, состоящую в том, что нам приходится принимать решения о том, какие из областей более представительны для данного процесса, чем другие, что может оказаться ошибочным.
Дата добавления: 2016-02-24; просмотров: 1688;