Вторая задача математической статистики. Критерии согласия.
Выравнивание статистических рядов
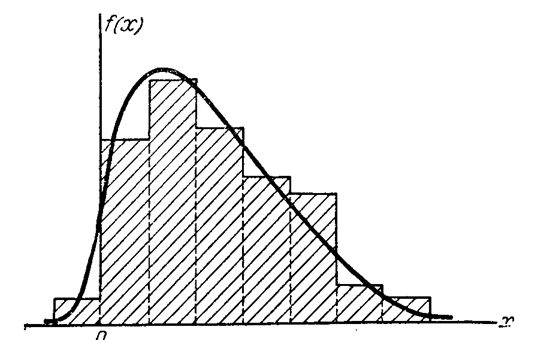
Во всяком статистическом распределении неизбежно присутствуют элементы случайности, связанные с тем, что число наблюдений ограничено, что произведены именно те, а не другие опыты, давшие именно те, а не другие результаты. Только при очень большом числе наблюдений эти элементы случайности сглаживаются, и случайное явление обнаруживает в полной мере присущую ему закономерность. На практике мы почти никогда не имеем дела с таким большим числом наблюдений и вынуждены считаться с тем, что любому статистическому распределению свойственны в большей или меньшей мере черты случайности. Поэтому при обработке статистического материала часто приходится решать вопрос о том, как подобрать для данного статистического ряда теоретическую кривую распределения, выражающую лишь существенные черты статистического материала, но не случайности, связанные с недостаточным объемом экспериментальных данных. Такая задача называется задачей выравнивания (сглаживания) статистических рядов.
Задача выравнивания заключается в том, чтобы подобрать теоретическую плавную кривую распределения, с той или иной точки зрения наилучшим образом описывающую данное статистическое распределение.
Задача о наилучшем выравнивании статистических рядов, как и вообще задача о наилучшем аналитическом представлении эмпирических функций, есть задача в значительной мере неопределенная, и решение ее зависит от того, что условиться считать «наилучшим». Например, при сглаживании эмпирических зависимостей очень часто исходят из так называемого принципа или метода наименьших квадратов считая, что наилучшим приближением к эмпирической зависимости в данном классе функций является такое, при котором сумма квадратов отклонений обращается в минимум. При этом вопрос о том, в каком именно классе функций следует искать наилучшее приближение, решается уже не из математических соображении, а из соображений, связанных с физикой решаемой задачи, с учетом характера полученной эмпирической кривой и степени точности произведенных наблюдений. Часто принципиальный характер функции, выражающей исследуемую зависимость, известен заранее из теоретических соображений, из опыта же требуется получить лишь некоторые численные параметры, входящие в выражение функции; именно эти параметры подбираются с помощью метода наименьших квадратов.
Аналогично обстоит дело и с задачей выравнивания статистических рядов. Как правило, принципиальный вид теоретической кривой выбирается заранее из соображений, связанных с существом задачи, а в некоторых случаях просто с внешним видом статистического распределения. Аналитическое выражение выбранной кривой распределения зависит от некоторых параметров; задача выравнивания статистического ряда переходит в задачу рационального выбора тех значений параметров, при которых соответствие между статистическим и теоретическим распределениями оказывается наилучшим.
Предположим, например, что исследуемая величина Х есть ошибка измерения, возникающая в результате суммирования воздействий множества независимых элементарных ошибок; тогда из теоретических соображений можно считать, что величина Х подчиняется нормальному закону:

 f(x) = e -(x-m)2
f(x) = e -(x-m)2
σ√2π σ2
и задача выравнивания переходит в задачу о рациональном выборе параметров m и σ в выражении
Критерии согласия
Рассмотрим один из вопросов, связанных с проверкой правдоподобия гипотез, а именно—вопрос о согласованности теоретического и статистического распределения.
Допустим, что данное статистическое распределение выравнено с помощью некоторой теоретической кривой f(х)
 f(х)
f(х)
 |
 |  |
 x
x
Как бы хорошо ни была подобрана теоретическая кривая, между нею и статистическим распределением неизбежны некоторые расхождения. Естественно возникает вопрос: объясняются ли эти расхождения только случайными обстоятельствами, связанными с ограниченным числом наблюдений, или они являются существенными и связаны с тем, что подобранная нами кривая плохо выравнивает данное статистическое распределение. Для ответа на такой вопрос служат так называемые «критерии согласия».
Идея применения критериев согласия заключается в следующем. На основании данного статистического материала нам предстоит проверить гипотезу Н, состоящую в том, что случайная величина Х подчиняется некоторому определенному закону распределения. Этот закон может быть задан в той или иной форме: например, в виде функции распределения F(x) или в виде плотности распределения f(x), или же в виде совокупности вероятностей рi где pi -вероятность того, что величина Х попадет в пределы i-го разряда.
Так как из этих форм функция распределения F (х) является наиболее общей и определяет собой любую другую, будем формулировать гипотезу Н, как состоящую в том, что величина Х имеет функцию распределения F(x).
Для того чтобы принять или опровергнуть гипотезу Н, рассмотрим некоторую величину U, характеризующую степень расхождения теоретического и статистического распределений. Величина U может быть выбрана различными способами; например, в качестве U можно взять сумму квадратов отклонений теоретических вероятностей Рi от соответствующих частот р*i или же сумму тех же квадратов с некоторыми коэффициентами («весами»), или же максимальное отклонение статистической функции распределения F*(x) от теоретической F(x) и т. д. Допустим, что величина U выбрана тем или иным способом. Очевидно, это есть некоторая случайная величина. Закон распределения этой случайной величины зависит от закона распределения случайной величины X, над которой производились опыты, и от числа опытов n. Если гипотеза Н верна, то закон распределения величины U определяется законом распределения величины Х (функцией F(x)) и числом n.
Допустим, что этот закон распределения нам известен. В ре-зультате данной серии опытов обнаружено, что выбранная нами мера расхождения U приняла некоторое значение u. Чем обусловлено это расхождение, случайными причинами или же это расхождение слишком велико и указывает на наличие существенной разницы между теоретическим и статистическим распределениями и, следовательно, на непригодность гипотезы H?.
Предположим, что гипотеза верна, и вычислим в этом предположении вероятность того, что за счет случайных причин, связанных с недостаточным объемом опытного материала, мера расхождения U ока- жется не меньше, чем наблюденное нами в опыте значение u, т. е вычислим вероятность события:
U ≥u.
Если эта вероятность весьма мала, то гипотезу H следует отверг- нуть как мало правдоподобную; если же эта вероятность значительна, следует признать, что экспериментальные данные не противоречат гипотезе Н.
Возникает вопрос о том, каким же способом следует выбирать меру расхождения U? Оказывается, что при некоторых способах ее выбора закон распределения величины U обладает весьма простыми свойствами и при достаточно большом n практически не зависит oт функции F(x). Именно такими мерами расхождения и пользуются в математической статистике в качестве критериев согласия.
Одним из наиболее часто применяемых критериев согласия - является «критерий χ2» Пирсона.
Предположим, что произведено n независимых опытов, в каждом из которых случайная величина Х приняла определенное значение. Результаты опытов сведены в k разрядов и оформлены в виде статистического ряда:
| Ii | Xi', Х2 | Х2 X3 | . . . | Xk, Xk+l |
| P*i | P1 | * P2 | . . . | Pk |
Требуется проверить, согласуются ли экспериментальные данные с гипотезой о том, что случайная величина Х имеет данный закон распределения (заданный функцией распределения F (х) или плотностью f(x)). Назовем этот закон распределения «теоретическим».
Зная теоретический закон распределения, можно найти теоретические вероятности попадания случайной величины в каждый из разрядов:
P1 P2 ••• Pk-
Проверяя согласованность теоретического и статистического распределений, мы будем исходить из расхождений между теоретическими вероятностями рi и наблюденными частотами р*i. Естественно выбрать в качестве меры расхождения между теоретическим и статистическим распределениями сумму квадратов отклонений (р*i,—рi), взятых с некоторыми «весами» ci:.
k
U=Σ ci (p*i-pi)2.
i=1
Коэффициенты сi («веса» разрядов) вводятся потому, что в общем случае отклонения, относящиеся к различным разрядам, нельзя считать равноправными по значимости. Действительно, одно и то же по абсолютной величине отклонение р*i-рi, может быть мало значительным, если сама вероятность рi велика, и очень заметным, если она мала. Поэтому естественно «веса» сi, взять обратно пропорциональными вероятностям разрядов Рi.
К. Пирсон показал, что если положить
ci=n/pi
то при больших n закон распределения величины U обладает весьма простыми свойствами: он практически не зависит от функции распределения F(х) и от числа опытов n, а зависит только от числа разрядов k, а именно, этот закон при увеличении n приближается к так называемому «распределению χ2» .
При таком выборе коэффициентов Сi мера расхождения обычно обозначается χ2
k
χ2=n Σ (p*i-pi)2/pi
i=1
Для удобства вычислений (чтобы не иметь дела с дробными величинами с большим числом нулей) можно ввести n под знак суммы.
Распределение χ2 зависит от параметра r, называемого числом «степеней свободы» распределения. Число «степеней свободы» r равно числу разрядов k минус число независимых условий («связей»), наложенных на частоты р*i,. Примерами таких условий могут быть
k
Σ p*i =1
i=1
если мы требуем только того. чтобы сумма частот была равна единице (это требование накладывается во всех случаях);
k ˜
Σ xi p*i = mx
i=1
если мы подбираем теоретическое распределение с тем условием, чтобы совпадали теоретическое и статистическое средние значения;
k
Σ (xi-m*x)2 p*i = Dx
i=1
если мы требуем, кроме того, совпадения теоретической и статистической дисперсий и т. д.
Для распределения χ2 составлены специальные таблицы. Пользуясь этими таблицами, можно для каждого значения χ2 и числа степеней свободы r найти вероятность р того, что величина, распределенная по закону χ2 превзойдет это значение. В табл. входами являются: значения вероятности р и число степеней свободы r. Числа, стоящие в таблице, представляют собой соответствующие значения χ2.
Распределение χ2 дает возможность оценить степень согласованности теоретического и статистического распределений. Будем исходить из того, что величина Х действительно распределена по закону F(X). Тогда вероятность р, определенная по таблице, есть вероятность того, что за счет чисто случайных причин мера расхождения теоретического и статистического распределений будет не меньше, чем фактически наблюденное в данной серии опытов значение χ2. Если эта вероятность р весьма мала (настолько мала, что событие с такой вероятностью можно считать практически невозможным), то результат опыта следует считать противоречащим гипотезе Н о том, что закон распределения величины Х есть F(x). Эту гипотезу следует отбросить как неправдоподобную. Напротив, если вероятность р сравнительно велика, можно признать расхождения между теоретическим и статистическим распределениями несущественными и отнести их за счет случайных причин. Гипотезу Н о том, что величина Х распределена по закону F(x), можно считать правдоподобной или, по крайней мере, не противоречащей опытным данным.
Таким образом, схема применения критерия χ2 к оценке согласованности теоретического и статистического распределений сводится к следующему:
1) Определяется мера расхождения χ2 по формуле
2) Определяется число степеней свободы r как число разрядов k минус число наложенных связей s:
r=k - s.
3) По г и χ2 с помощью табл. определяется вероятность того, что величина, имеющая распределение χ2 с r степенями свободы, превзойдет данное значение χ2. Если эта вероятность весьма мала, гипотеза отбрасывается как неправдоподобная. Если эта вероятность относительно велика, гипотезу можно признать не противоречащей опытным данным.
Насколько мала должна быть вероятность р для того, чтобы отбросить или пересмотреть гипотезу, - вопрос неопределенный; он не может быть решен из математических соображений, так же как и вопрос о том, насколько мала должна быть вероятность события для того, чтобы считать его практически невозможным. На практике, если р оказывается меньшим чем 0.1, рекомендуется проверить эксперимент, если возможно - повторить его и в случае, если заметные расхождения снова появятся, пытаться искать более подходящий для описания статистических данных закон распределения.
Следует особо отметить, что с помощью критерия χ2 (или любого другого критерия согласия) можно только в некоторых случаях опровергнуть выбранную гипотезу Н и отбросить ее как явно несогласную с опытными данными; если же вероятность р велика, то этот факт сам по себе ни в коем случае не может считаться доказательством справедливости гипотезы H, а указывает только на то, что гипотеза не противоречит опытным данным.
С первого взгляда может показаться, что чем больше вероятность р, тем лучше согласованность теоретического и статистического распределений и тем более обоснованным следует считать выбор функции Р(х) в качестве закона распределения случайной величины. В действительности это не так. Допустим, например, что, оценивая согласие теоретического и статистического распределении по критерию χ2, мы получили р = 0.99. Это значит, что с вероятностью 0.99 за счет чисто случайных причин при данном числе опытов должны были получиться расхождения большие, чем наблюденные. Мы же получили относительно весьма малые расхождения, которые слишком малы для того, чтобы признать их правдоподобными. Разумнее признать, что столь близкое совпадение теоретического и статистического распределений не является случайным и может быть объяснено определенными причинами, связанными с регистрацией и обработкой опытных данных (в частности, с весьма распространенной на практике «подчисткой» опытных данных, когда некоторые результаты произвольно отбрасываются или несколько изменяются).
Разумеется, все эти соображения применимы только в тех случаях, когда количество опытов n достаточно велико (порядка нескольких сотен) и когда имеет смысл применять сам критерий, основанный на предельном распределении меры расхождения при n—>оо. Заметим, что при пользовании критерием χ2 достаточно большим должно быть не только общее число опытов n, но и числа наблюдений mi в отдельных разрядах. На практике рекомендуется иметь в каждом разряде не менее 5—10 наблюдений. Если числа наблюдений в отдельных разрядах очень малы (порядка 1—2), имеет смысл объединить некоторые разряды.
Кроме критерия χ2, для оценки степени согласованности теоретического и статистического распределений на практике применяется еще ряд других критериев. Рассмотрим критерий А. Н. Колмогорова.
В качестве меры расхождения между теоретическим и статистическим распределениями А. Н. Колмогоров рассматривает максимальное значение модуля разности между статистической функцией распределения F*(х) и соответствующей теоретической функцией распределения:
D=max│F*(x)-F(x) │.
Основанием для выбора » качестве меры расхождения величины D является простота ее вычисления. Вместе с тем ома имеет достаточно npocтой закон распределения. А. Н. Колмогоров доказал, что, какова бы ни была функция распределения F(X) непрерывной случайной величины X, при неограниченном возрастании числа независимых наблюдений n вероятность неравенства
D√n>λ
стремится к пределу
оо
P(λ)=1- Σ(-1)kе-2k2 λ2 .
k=-оо
Значения вероятности Р(λ), подсчитанные по формуле приведены в таблице
| λ | P(λ) | λ | P(λ) | λ | P(λ) |
| 0,0 0,1 0,2 0,3 0,4 0,5 0,6 | 1,000 1,000 1,000 1,000 0,997 0,964 0,864 | 0,7 0,8 0,9 1,0 1,1 1,2 1,3 | 0,711 0,544 0,393 0,270 0,178 0,112 0,068 | 1,4 1,5 1,6 1,7 1,8 1,9 2,0 | 0,040 0,022 0,012 0,006 0,003 0,002 0,001 |
Схема применения критерия А. Н. Колмогорова следующая: строятся статистическая функция распределения F* (х) и предполагаемая теоретическая функция распределения F(x), и определяется максимум D модуля разности между ними. Далее, определяется величина
λ = D√ n
и по таблице находится вероятность Р(λ). Это есть вероятность того, что (если величина X действительно распределена по закону F (х)) за счет чисто случайных причин максимальное расхождение между F* (х) и F (х) будет не меньше, чем фактически наблюденное. Если вероятность Р(Х) весьма мала, гипотезу следует отвергнуть как неправдоподобную; при сравнительно больших Р (X) ее можно считать совместимой с опытными данными.
Критерий А. Н. Колмогорова своей простотой выгодно отличается от описанного ранее критерия χ2, поэтому его весьма охотно применяют на практике. Следует, однако, оговорить, что этот критерий можно применять только в случае, когда гипотетическое распределение F(x) полностью известно заранее из каких-либо теоретических соображений, т. е. когда известен не только вид функции распределения F (х), но и все входящие в нее параметры. Такой случай сравнительно редко встречается на практике. Обычно из теоретических соображений известен только общий вид функции F(x), а входящие в нее числовые параметры определяются по данному статистическому материалу. При применении критерия χ2 это обстоятельство учитывается соответствующим уменьшением числа степеней свободы распределения χ2. Критерий А. Н. Колмогорова такого согласования не предусматривает. Если все же применять этот критерий в тех случаях, когда параметры теоретического распределения выбираются по статистическим данным, критерий дает заведомо завышенные значения вероятности Р(λ), поэтому в ряде случаев существует риск принять как правдоподобную гипотезу, в действительности плохо согласующуюся с опытными данными.
4.Третья задача математической статистики.
Третья задача матстатистики заключается в нахождении неизвестных параметров распределения.
Мы уже знаем, что для того чтобы найти закон распределения необходимо располагать достаточно большим статистическим материалом, порядка нескольких сотен наблюдений.
На практике часто приходится иметь дело со статистическим материалом ограниченного объема - два-три десятка наблюдений. Причины мгут быть разными(недостаточность времени, высокая стоимость наблюдений и т.д.). Ограниченный объем материала недостаточен для того, чтобы найти заранее неизвестный закон распределения случайной величины, но все же данный материал может быть обработан и использован для получения сведений о случайной величине.
Так на основе ограниченного статистического материала можно определить важнейшие числовые характеристикии случайной величины: МОЖ, дисперсию, иногда другие моменты.
На практике часто заранее известен вид закона распределения и требуется найти только некоторые параметры от которых он зависит.
Если заранее известно, что случайная величина распределена по нормальному закону, то задача обработки сводится к определению параметров m и σ.
Если случайная величина распределена по закону Пуассона, то надо определить одну величину а - МОЖ.
Необходимо отметить, что любое значение искомого параметра, вычисленное на основе ограниченного числа опытов, будет содержать элемент случайности. Такое приближенное, случайное значение называется оценкой параметра.
Оценкой МОЖ является среднее арифметическое значение. Прибольшом числе опытов среднее арифметическое приближается к МОЖ.
Любая оценка случайна, а поэтому неизбежны ошибки. Следовательно надо выбрать такую оценку, чтобы ошибки были минимальны.
Рассмотрим следующую задачу. Имеется случайная величина X, закон распределения которой содержит неизвестный параметр а. Требуется по результатам n независимых опытов, в каждом их которых величина X приняла определенное значение, найти подходящую оценку для параметра а.
Обозначим полученные значения
X1, X2, X3, ….Xn
˜
Обозначим а оценку для параметра а. Эта оценка зависит от X, т.е. является функцией .
К оценке параметра предъявляются следующие требования.
Необходимо, чтобы оценка при увеличении числа параметров приближалась к параметру а (сходилась по вероятности). Оценка обладающая таким свойством называется состоятельной.
Необходимо, чтобы оценка не давала систематической ошибки в сторону завышение или занижения, т.е. должно выполняться условие
М[а]=а.
Оценка удовлетворяющая такому требованию, называется несмещенной.
Необходимо, чтобы выбранная несмещенная оценка обладала наименьшей дисперсией
D[a] = min.
Оценки МОЖ и дисперсии.
Пусть имеется случайная величина Х с МОЖ m и дисперсией D. Необходимо найти состоятельные и несмещенные оценки для m и D.
Оценкой для МОЖ является среднее арифметическое
ΣXi
 m*=
m*=
n
Дисперсия этой оценки равна:
D[m] = 1/n D
| <== предыдущая лекция | | | следующая лекция ==> |
| Статистической функцией распределения случайной величины Х называется частота события Х < х в данном статистическом материале. | | | Оценки для математического ожидания и дисперсии |
Дата добавления: 2016-02-20; просмотров: 1861;