СТА: Лабораторная работа №2 - Алгоритмы поиска и сортировки
Версия 2.0, 27 сентября 2013г.
(С) 2012-2013, Зайченко Сергей Александрович, к.т.н, ХНУРЭ, доцент кафедры АПВТ
Правила выполнения лабораторной работы
- Лабораторная работа выполняется либо бригадой из 2 человек, либо индивидуально. Если студент претендует на оценку “отлично”, работа должна выполняться полностью индивидуально.
2. В работе на выбор студента предлагаются варианты трех уровней сложности:
- Базовый уровень - оценка в интервале 15-20 баллов.
- Углубленный уровень - оценка в интервале 21-25 баллов.
- Амбициозный уровень - оценка не менее 25 баллов + бонусные баллы на усмотрение преподавателя.
3. Реализовывать задачи необходимо исключительно на языке программирования С++.
4. Работа оценивается не только по корректности функционирования решений задач, но и по культуре оформления исходного кода в читабельном виде, адекватности разбиения решения на модули и функции.
5. Поскольку одной из основных целей данного курса является изучение способов построения классических структур данных, при реализации задач запрещается использовать готовые библиотечные реализации этих структур.
6. Защита работы:
- устная и короткая без отчета в случае защиты в день лабораторной работы;
- с полноценным печатным отчетом и ответами на теоретические вопросы в случае защиты в другие дни.
7. Неприемлемым нарушением считается копирование исходного кода программ у другой бригады или из любых других источников тем или иным способом. В случае подозрения на плагиат, преподаватель оставляет за собой право не засчитывать решение полностью или частично, в зависимости от уровня понимания бригадой написанного кода. Уровень понимания может устанавливаться дополнительными вопросами к каждому из участников бригады по коду конкретной программы, по использованным в ней конструкциям языка программирования. В качестве проверки на понимание могут быть запрошены некоторые изменения поведения программы, отклоняющиеся от оригинальных условий задачи.
8. Пропуск лабораторной работы, независимо от уважительности причин, не освобождает от сдачи работы. В случае пропуска следует самостоятельно найти методические указания у сокурсников или преподавателя, согласовать с преподавателем вариант задания, в домашних условиях либо с другой группой выполнить лабораторную работу, подготовить отчет и пройти защиту.
Литература к лабораторной работе
- Р. Седжвик “Алгоритмы на С++”:
- Глава 6 “Элементарные методы сортировки”.
- Глава 7 “Быстрая сортировка”.
- Глава 8 “Слияние и сортировка слиянием”.
- Глава 12 “Таблицы символов и деревья бинарного поиска” (подразделы 12.1-12.4)
- Т. Кормен, Ч. Лейзерсон, Р. Ривест, К. Штайн “Алгоритмы. Построение и анализ”, 2 издание:
- Глава 7 “Быстрая сортировка”.
- Глава 10 “Элементарные структуры данных” (подразделы 10.1-10.3)
- А. Ахо, Д. Хопкрофт, Д. Ульман “Структуры данных и алгоритмы”:
- Глава 2 “Основные абстрактные типы данных” (подраздел 2.5).
- Глава 4 “Основные операторы множеств” (подразделы 4.1-4.6).
- Глава 8 “Сортировка”.
- Д. Кнут “Искусство программирования”:
- Том 3, глава 5, раздел 5.2 “Внутренняя сортировка”.
- Том 3, глава 6, раздел 6.1 “Последовательный поиск”.
- Том 3, глава 6, раздел 6.2 “Поиск путем сравнения ключей”.
Исходные данные
При решении задач лабораторной работы по желанию можно использовать готовые реализации изложенные в материалах лекций. Перечисленные ниже файлы прилагаются к данным методическим указаниям:
- Отображение ( integer_map.hpp, integer_map_vector_impl.cpp ).
- Множество ( integer_set.hpp, integer_set_list_impl.cpp, integer_set_sorted_list_impl.cpp ).
Эти реализации можно использовать непосредственно как готовую библиотеку, либо использовать как начальную точку для собственного решения.
Выдавать данные файлы за собственные решения настоятельно не рекомендуется :)
Решения на основе примитивных массивов и других идеях, не относящиеся к динамическим структурам данных, не будут засчитаны.
Варианты базового уровня
Вариант №1:
- Реализуйте все операции АТД “отображение” для ключей и значений, являющихся целыми числами, на основе единственного объекта-вектора. Вектор должен хранить и ключи, и значения в внутренних ячейках в одном блоке в виде вложенной структуры:
structIntegerMap
{
intm_nUsed;
intm_nAllocated;
structCell
{
intm_key;
intm_value;
};
Cell * m_pData;
};
Набор пар ключ-значение {1 ->10, 2 -> 20, 3 -> 30} будет иметь следующий вид:
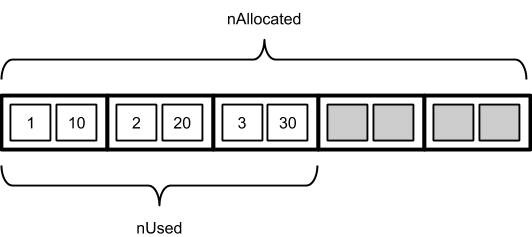
Убедитесь в работоспособности реализации при помощи тестовой программы.
2. Модифицируйте алгоритм быстрой сортировки массива целых чисел таким образом, что опорный элемент (pivot) выбирался из трех элементов сортируемого интервала - первого, серединного и последнего. Необходимо сравнить элементы между собой и выбрать из них средний по значению. Этот прием должен уменьшать вероятность неудачных разбиений по опорному элементу. Замеряйте время выполнения алгоритма быстрой сортировки до и после модификации для различных наборов данных, поместите результаты в отчет в табличной форме.
Вариант №2:
- Реализуйте все операции АТД “отображение”, у которого в качестве ключей используются строки, а в качестве значений - действительные числа (double). Реализация должна основываться на двух отдельных векторах для ключей и значений. Вносимые в отображение строки следует копировать при вставке, а при удалении данных строки следует корректно освобождать. Убедитесь в работоспособности реализации при помощи тестовой программы.
2. Реализуйте алгоритм сортировки слиянием для массива строк, при этом строки должны сравниваться без учета регистра (т.е., “hello” и “HELLO” следует считать одинаковыми строками). Убедитесь в работоспособности реализации на любом достаточно большом текстовом файле.
Вариант №3:
- Реализуйте все операции АТД “отображение”, для ключей и значений, являющихся целыми числами, где допускается дупликация ключей. Иными словами, одному ключу может соответствовать несколько значений (такая структура называется “мультиотображением”). В основе реализации можно использовать отдельные векторы для ключей и значений. К стандартному набору операций АТД “отображение” следует добавить операцию, возвращающую количество значений, соответствующих указанному ключу:
COUNT_KEY( map, key ) : int
В операциях поиска и удаления по ключу следует использовать первую попадающуюся при обходе пару с указанным ключом. Если ключу соответствует N значений, то для полного его удаления из отображений следует вызывать операцию REMOVE_KEY ровно N раз. Убедитесь в работоспособности реализации при помощи тестовой программы.
2. Реализуйте алгоритм быстрой сортировки для массива строк, при этом строки должны сравниваться без учета регистра (т.е., “hello” и “HELLO” следует считать одинаковыми строками). В качестве опорного элемента используйте случайную позицию. Убедитесь в работоспособности реализации на любом достаточно большом текстовом файле.
Вариант №4:
- В программе имеются в явном виде заданные данные о численности населения всех областей Украины (используйте любые данные, не обязательно вспоминать названия всех областей и вводить реальные данные о численности населения). Пользователь вводит в программу через консоль строку с названием области, а программа печатает данные о численности населения этой области. Если введенной области в памяти нет, программа печатает на экране соответствующее сообщение об ошибке.
2. Имеется структура, описывающая фамилии и инициалы людей:
structPersonName
{
char* m_lastName;
charm_initials[ 2 ];
};
Реализуйте один из простейших алгоритмов сортировки на ваш вкус (пузырьковая, выбором, вставками) для массива элементов, являющихся объектами данной структуры. При этом, первоочередным критерием для сравнения двух объектов должна являться фамилия, а при равенстве фамилии - разница в инициалах.
Вариант №5:
- В программе имеются заданные в явном виде данные о ежемесячной выручке предприятия “Рога и Копыта” за предыдущий год деятельности. Пользователь вводит в программу порядковый номер месяца в году (январь-1, февраль-2,..., декабрь-12). Программа печатает данное о выручке в соответствующем введенному номеру месяцу. Если вводится неправильный номер, программа печатает соответствующее сообщение об ошибке.
2. Программа генерирует массив из N случайных целых чисел. Необходимо замерять и сравнить производительность двух фрагментов программы для различных N:
- большое количество M вызовов линейного поиска случайного числа в этом массиве;
- запуск быстрой сортировки массива + такое же большое количество M вызовов бинарного поиска случайного числа в этом же массиве.
Результаты измерений поместите в отчет в виде таблицы. Обязательно измерить время работы алгоритмов как для небольших N (5-10), так и для достаточно больших N (10-100 тысяч).
Вариант №6:
- Пользователь вводит в программу текст произвольной длины, завершая ввод нажатием комбинации клавиш <Ctrl+Z>. Программа вычисляет длину каждой введенной строки и собирает статистику длины различных строк в объекте-отображении. Ключом в отображении является длина строки, а значением - количество строк с такой длиной. После завершения ввода программа печатает на экране собранную статистику. Например, пользователь ввел 4 строки:
aaa
bbbb
cc
ddd
Программа должна выдать следующий отчет (порядок не имеет значения):
2 line(s) with length 3
1 line(s) with length 2
1 line(s) with length 4
2. Реализуйте простейший алгоритм сортировки на ваш вкус (пузырьковая, выбором, вставками) для массива, содержащего указатели на объекты-множества целых чисел. При сравнении множеств следует, в первую очередь, руководствоваться минимальным значением, находящимся во множестве. При равенстве таких минимальных значений для двух множеств, первым по порядку должно идти множество с меньшим количеством элементов.
Вариант №7:
- В программе имеются заданные в явном виде данные о товарах из магазина. Каждый товар имеет свой уникальный код в диапазоне от 1 до 100. Номера не обязательно идут подряд, также нет никакого требования о каком-либо порядке. Пользователь вводит в программу целое положительное число, означающее код, а программа печатает название соответствующего товара, если такой найден. Если товара с таким кодом нет, программа печатает сообщение об ошибке. Процесс повторяется циклически. Если введен код 0, программа завершается.
2. Модифицируйте алгоритм сортировки слиянием для массива целых чисел таким образом, чтобы можно было контролировать извне способ сортировки малого количества элементов. Общий алгоритм сортировки слиянием должен принимать дочерний алгоритм, такой как пузырьковая сортировка, вставками или выбором, в виде указателя на функцию. Если передан нулевой указатель на функцию, разбиение должно продолжиться до элементарных случаев с N=1 или N=2, где никакой алгоритм не потребуется. Сравните производительность 4 режимов слияния (на нижнем уровне базовый алгоритм, пузырьковая сортировка, сортировка выбором или вставками) на одном и том же достаточно большом наборе случайных чисел (например, 500 000 элементов). Поместите результаты измерений в отчет.
Вариант №8:
- Представьте небольшую гостиницу, в которой имеется 20 номеров. Некоторые могут быть свободны, некоторые заняты постояльцами. Напишите программу, имитирующую учет информации о постояльцах номеров. Изначально гостиница пуста. Если пользователь вводит число 1, за ним следует число, означающее номер, и программа печатает занят ли данный номер. Если пользователь вводит число 2, за ним также следует число, означающее номер, и программа делает свободный номер занятым. Если номер был уже занят, программа печатает сообщение об ошибке. Если пользователь вводит число 3, за ним также следует число, означающее номер, и программа освобождает занятый номер. Если номер не был занят, программа печатает сообщение об ошибке. Процесс повторяется циклически до ввода числа 4, после которого программа завершается. В командах 1-3, если введен неправильный номер, программа печатает сообщение об ошибке.
2. Пользователь вводит в программу последовательность положительных целых чисел в произвольном порядке, завершая ввод нулем либо отрицательным числом. Программа отвечает на вопрос существует ли такая перестановка введенных чисел, чтобы из исходного набора получилась арифметическая прогрессия.
Вариант №9:
- Реализуйте все операции АТД “множество” для строковых ключей на основе упорядоченных по алфавиту односвязных списков. Помещаемые во множество строки следует копировать при вставке, корректно освобождать при удалении. Убедитесь в работоспособности реализации при помощи тестовой программы.
2. Имеется массив элементов-точек в трехмерном пространстве:
structPoint3D
{
doublem_x, m_y, m_z;
};
Взяв за основу любой из полюбившихся алгоритмов сортировки, напишите программу, которая упорядочивает массив точек по возрастанию расстояния точки до начала координат и выводит его на экран.
Вариант №10:
- Дополните реализацию АТД “множество” для целых чисел на основе односвязных списков следующими операциями:
IS_SUBSET ( set1, set2 ) : bool - возвращает true, если первое множество является подмножеством второго множества.
EQUAL ( set1, set2 ) : bool - возвращает true, если два множества состоят из одних и тех же элементов.
MIN_KEY ( set ) : value - возвращает ключ с минимальным значением.
MAX_KEY ( set ) : value - возвращает ключ с максимальным значением.
Убедитесь в работоспособности функций при помощи тестовой программы.
2. В программе имеется заданное в явном виде множество из 20 фамилий, упорядоченных по алфавиту. Фамилии могут повторяться. Пользователь вводит строку, означающую фамилию. Программа ищет введенную фамилию во множестве и печатает количество записей с такой фамилией. Если записей не обнаружено, программа печатает число 0. Обязательное условие - программа в худшем случае должна сделать не более 5 сравнений фамилий!
Варианты углубленного уровня
Вариант №11:
Реализуйте структуру и набор стандартных операций АТД “множество” на основе характеристических векторов, однако без ограничения на максимум 32 элемента. Тщательно покройте реализацию тестами. Подсказка: храните установленные флаги в массиве чисел.
Вариант №12:
В ресторане в течение рабочего дня для всех посетителей регистрируется время прихода и ухода в виде пары моментов времени. Некоторые посетители проводят в ресторане больше времени, некоторые меньше. В результате сбора информации, имеется массив из переменных простейшей структуры:
structCustomerVisitTime
{
shortm_startHour, m_startMinute;
shortm_finishHour, m_finishMinute;
};
Требуется вычислить в течение какого из 30-минутных отрезков в сутках в ресторане находилось наибольшее количество одновременных посетителей.
Вариант №13:
В текстовом файле, имя которого передается первым аргументом командной строки, имеются данные о среднем курсе доллара на межбанковской валютной бирже по дням, заданные в следующем формате:
12/11/2012 8.195
16/11/2012 8.218
14/11/2012 8.203
Даты могут идти не подряд и не упорядочены по датам. Затем пользователь вводит интересующую его дату, и программа выдает курс доллара в этот день. Если в файле имеется запись о такой дате, программа выдает найденное данное непосредственно. Если в файле записи о такой дате не имеется, программа находит два ближайших к этой дате значения - одна раньше и одна позже, и выдает курс как среднее арифметическое между двумя ближайшими датами. Если введена дата, которая раньше и позже всех имеющихся дат, программа пишет сообщение об ошибке.
Вариант №14:
Реализуйте базовые операции АТД “множество”, не включая теоретико-множественные операции, на основе самоорганизующихся списков. Такой список не является упорядоченным, изначально данные в нем хранятся в соответствии с порядком вставки. Однако при успешном поиске ключа в дальнейшем его следует перемещать в начало списка. Таким образом, после N перестановок будет получен порядок, приблизительно соответствующий типичной частоте поиска ключей, что может существенно улучшить базовый алгоритм линейного поиска. Продемонстрируйте работоспособность решения при помощи тестовой программы. Измерьте выигрыш производительности при частом поиске некоторых ключей по сравнению с базовым алгоритмом линейного поиска.
Вариант №15:
Реализуйте алгоритм сортировки слиянием для упорядочивания последовательности целых чисел, хранящихся в виде односвязного списка (IntegerList).
Варианты амбициозного уровня
Вариант №16:
Имеется текстовый файл, называющийся “references_stats.txt”, содержащий статистику обработанных ссылок на веб-сайты в указанном ниже формате:
www.microsoft.com 5402
www.oracle.com 3715
На вход программы подается файл в формате HTML, имя которого указывается первым аргументом командной строки. Программа находит все ссылки на странице (тег <a>, атрибут “href”), извлекает из ссылок множество уникальных сайтов (не страниц или аргументов запроса!) и обновляет статистический файл. Если файла не существовало, программа создает его. Если файл ранее не содержал такого сайта, запись о сайте и его первой ссылке добавляется. Если сайт уже ранее присутствовал в файле, счетчик ссылок на сайт увеличивается. При анализе HTML-кода следует обработать максимум синтаксически возможных в HTML вариантов записи тега <a> - в теге могут быть другие атрибуты, не только href, между названием атрибута и его значением может быть сколь угодно большое число пробелов, и т.п. небольшие синтаксические нюансы.
Вариант №17:
Реализуйте АТД “множество” для целых чисел на основе компактного хранения отрезков для идущих подряд значений. Например, если некоторые из элементов множества образуют ряд:
{1, 3, 5, 6, 7, 8, 12, 14, 15, 16, 20 }
представляется возможным хранить эти данные в виде отрезков, задающих интервалы:
{1, 3, 5-8, 12, 14-16, 20 }
Если во множество вставляется ключ, который соединяет два соседних отрезка либо отрезок и число в один более длинный отрезок, следует сделать такое преобразование. Например, добавление в приведенное выше множество ключа 13 приведет к следующему изменению:
{1, 3, 5-8, 12-16, 20 }
Аналогично, при удалении отрезки могут быть разорваны. Например, удалив ключ 6, получим:
{1, 3, 5, 7-8, 12-16, 20 }
Принцип хранения не должен оказывать никакого влияния на интерфейс множества, в то же время максимально использовать преимущества такого компактного хранения при реализации операций.
Контрольные вопросы
- АТД “отображение” - основные операции, простейшие способы реализации.
- АТД “отображение” - использование индексов массивов как ключей особого вида.
- АТД “множество” - основные операции, простейшие способы реализации.
- АТД “множество” - повышение быстродействия за счет упорядочивания ключей.
- Реализация АТД “множество” на основе характеристических векторов.
- Понятие вычислительной сложности. Основные функции оценки вычислительной сложности.
- Алгоритм бинарного поиска.
- Простейшие алгоритмы сортировки - пузырьковая, вставками, выбором.
- Алгоритм сортировки слиянием.
- Алгоритм быстрой сортировки.
Дата добавления: 2016-01-29; просмотров: 2019;