Алгоритм исчисления порядка (index-calculus algorithm).
Основные идеи алгоритма исчисления порядка были известны с 20-х годов XX века, но лишь в 1979 году Адлерман указал на этот алгоритм как на средство вычисления дискретного логарифма и исследовал его трудоемкость. В настоящее время алгоритм исчисления порядка и его улучшенные варианты дают наиболее быстрый способ вычисления дискретных логарифмов в некоторых конечных группах, в частности, в группе Zp*.
Этот алгоритм в отличие от алгоритмов прямого поиска и ро-метода подходит не для всех циклических групп.
Алгоритм состоит в следующем:
Алгоритм исчисления порядка
Вход: g – порождающий элемент циклической группы порядка n, a 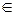 G, с≈10 – параметр надежности.
G, с≈10 – параметр надежности.
Ш.1. Выбирается факторная база S={p1, p2,…,pt}. (Если G=Zp*, то S состоит из t первых простых чисел.)
Ш.2. Выбрать случайное k: 0≤k<n и вычислить gk.
Ш.3. Попытаться разложить gk по факторной базе:
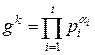 , αi≥0.
, αi≥0.
Если это не удалось, вернуться на Шаг 2.
Ш.4. Логарифмируя обе части получившегося выражения, получаем
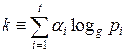 (mod n) *
(mod n) *
В этом выражении неизвестными являются логарифмы.
Это сравнение с t неизвестными следует запомнить.
Ш.5. Если сравнений вида (*), полученных на Шаге 4, меньше, чем t+c, то вернуться на Шаг 2.
Ш.6. Решить систему t+c сравнений с t неизвестными вида (*), составленную на Шагах 2-5.
Ш.7. Выбрать случайное k: 0≤k<n и вычислить agk.
Ш.8. Попытаться разложить agk по факторной базе:
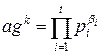 , βi≥0.
, βi≥0.
Если это не удалось, вернуться на Шаг 7.
Ш.9. Логарифмируя обе части последнего равенства, получаем
x= 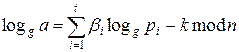 ,
,
где loggpi (1≤i≤t) вычислены на Шаге 6 как решение системы сравнений.
Выход. x = logga mod n.
В том случае, когда G=Zp*, в качестве факторной базы S берут t первых простых чисел. Такой выбор оправдан следующим наблюдением. Число, наугад выбранное из множества целых чисел, с вероятностью 1/2 делится на 2, с вероятностью 1/3 – на 3, с вероятностью 1/5 – на 5 и т.д. Поэтому можно ожидать, что в промежутке от 1 до p—1 найдется достаточно много чисел, в разложении которых участвуют только маленькие простые делители из множества S. Именно такие числа отыскиваются на шагах 2 и 7.
Параметр c вводится для того, чтобы система сравнений, решаемая на Шаге 6, имела единственное решение. Дело в том, что полученная система может содержать линейно зависимые сравнения. Считается, что при значении с порядка 10 и большом p система сравнений имеет единственное решение с высокой вероятностью.
Пример.
G=Z*71, g=7, a=17, n=φ(71)=70.
S={2, 3, 5, 7} (Шаг 1). (Можем сразу указать log77 mod 70=1).
Теперь будем перебирать k для составления системы сравнений вида * (Шаги 2—5).
k=2, 72 mod 71=49=7·7. (поскольку log77 уже вычислен, это сравнение нам не пригодится).
k=3, 73 mod 71=59.
k=4, 74 mod 71=58=2·29.
k=5, 75 mod 71=51=3·17.
k=6, 76 mod 71=2 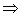 6≡log72(mod 70)
6≡log72(mod 70)
k=7, 77 mod 71=14=2·7 7≡log72+log77(mod 70)
k=8, 78 mod 71=27=33 8≡3log73(mod 70)
k=9, 79 mod 71=47.
k=10, 710 mod 71=45=32·5 10≡2log73+log75(mod 70)
Теперь имеем достаточно сравнений для того, чтобы определить логарифмы от элементов факторной базы. Вот эти сравнения:
6≡log72(mod 70)
7≡log72+log77(mod 70)
8≡3log73(mod 70)
10≡2log73+log75(mod 70)
Решая полученную систему, получаем (Шаг 6):
log72≡6(mod 70), log73≡26(mod 70),
log75≡28(mod 70), log77≡1(mod 70).
Перейдем к Шагам 7—9:
k=1, 26·7 mod 71=40=23·5 log726≡3log72+log75—1(mod 70)
log726≡3·6+28—1(mod 70)
log726≡45(mod 70)
Проверка: 745 mod 71 = 26. Верно.
Ответ: log726≡45(mod 70).
Замечание: Для случая G=Zp и для случая G=F2m составляет Lq[1/2,c], где q есть мощность G, с > 0 – константа. Алгоритм, имеющий наилучшую оценку сложности (по времени) для дискретного логарифмирования в Zp есть вариант алгоритма исчисления индексов под названием «метод решета числового поля» (number field sieve), для дискретного логарифмирования в F2m - вариант данного алгоритма под названием «алгоритм Копперсмита» (Coppersmith’s algorithm). Эти алгоритмы слишком сложны, чтобы приводить их здесь.
Дата добавления: 2015-11-28; просмотров: 4218;