МОДЕЛИРОВАНИЕ ДАННЫХ
4.1. Подходы к моделированию данных
Существует два основных способа проектирования программных систем и данных - структурное проектирование, основанное на алгоритмической декомпозиции, и объектно-ориентированное проектирование, основанное на объектно-ориентированной декомпозиции. Разделение по алгоритмам концентрирует внимание на порядке происходящих событий, а разделение по объектам придает особое значение объектам действия.
Алгоритмическую декомпозицию можно представить как обычное разделение алгоритмов, где каждый модуль системы выполняет один из этапов общего процесса. При объектно-ориентированной декомпозиции каждый объект обладает своим собственным поведением и каждый из них моделирует некоторый объект реального мира.
Объектная декомпозиция имеет несколько преимуществ перед алгоритмической.
• Объектная декомпозиция уменьшает размер программных систем за счет повторного использования общих механизмов.
• Объектно-ориентированные системы более гибки и проще эволюционируют со временем.
В объектно-ориентированном анализе существует четыре основных типа моделей: динамическая, статическая, логическая и физическая.
Через них можно выразить результаты анализа и проектирования, выполненные в рамках любого проекта. Эти модели в совокупности семантически достаточно универсальны, чтобы разработчик мог выразить все заслуживающие внимания стратегические и тактические решения, которые он должен принять при анализе системы и формировании ее архитектуры.
Кроме того, эти модели достаточно полны, чтобы служить техническим проектом реализации практически на любом объектно-ориентированном языке программирования.
Фактически все сложные системы можно представить одной и той же канонической формой - в виде двух ортогональных иерархий одной системы: классов и объектов. Каждая иерархия является многоуровневой, причем в ней классы и объекты более высокого уровня построены из более простых. Какой класс или объект выбран в качестве элементарного, зависит от рассматриваемой задачи. Объекты одного уровня имеют четко выраженные связи, особенно это касается компонентов структуры объектов.
Внутри любого рассматриваемого уровня находится следующий уровень сложности. Структуры классов и объектов не являются независимыми:
каждый элемент структуры объектов представляет специфический экземпляр определенного класса. Объектов в сложной системе обычно гораздо больше, чем классов. С введением структуры классов в ней размещаются общие свойства экземпляров классов.
Сущность структурного подхода к разработке ИС заключается в ее декомпозиции (разбиении) на автоматизируемые функции: система разбивается на функциональные подсистемы, которые в свою очередь делятся на подфункции, подразделяемые на задачи и так далее. Процесс разбиения продолжается вплоть до конкретных процедур. При этом автоматизируемая система сохраняет целостное представление, в котором все составляющие компоненты взаимоувязаны. Общая модель системы строится в виде некоторой иерархической структуры, которая отражает различные уровни абстракции с ограниченным числом компонентов на каждом из уровней. Одним из главных принципов структурного системного анализа является выделение на каждом из уровней абстракции только наиболее существенных компонентов или элементов системы.
Все наиболее распространенные методологии структурного подхода базируются на ряде общих принципов. В качестве двух базовых принципов используются следующие:
· принцип "разделяй и властвуй" - принцип решения сложных проблем путем их разбиения на множество меньших независимых задач, легких для понимания и решения;
· принцип иерархического упорядочивания - принцип организации составных частей проблемы в иерархические древовидные структуры с добавлением новых деталей на каждом уровне.
Выделение двух базовых принципов не означает, что остальные принципы являются второстепенными, поскольку игнорирование любого из них может привести к непредсказуемым последствиям (в том числе и к провалу всего проекта). Основными из этих принципов являются следующие:
· принцип абстрагирования - заключается в выделении существенных аспектов системы и отвлечения от несущественных;
· принцип формализации - заключается в необходимости строгого методического подхода к решению проблемы;
· принцип непротиворечивости - заключается в обоснованности и согласованности элементов;
· принцип структурирования данных - заключается в том, что данные должны быть структурированы и иерархически организованы.
В структурном анализе используется ряд средств, иллюстрирующих функции, выполняемые системой и отношения между данными. Каждой группе средств соответствуют определенные виды моделей (диаграмм). Наиболее распространенной диаграммой, предназначенной для моделирования данных, является диаграмма ERD (Entity-Relationship Diagrams) "сущность-связь".
4.2. Диаграммы потоков данных (DFD)
Диаграммы DFD (Data Flow Diagramming) могут дополнить то, что уже отражено в модели IDEF0, поскольку они описывают потоки данных, позволяя проследить, каким образом происходит обмен информацией как внутри системы между бизнес-функциями, так и системы в целом с внешней информационной средой.
Для усиления функциональности в данной нотации диаграмм предусмотрены специфические элементы, предназначенные для описания информационных и документопотоков, такие как внешние сущности и хранилища данных.
Без объекта "внешняя сущность" аналитику бывает иногда сложно определить, откуда пришли в компанию данные документы. Или какие документы еще приходят от, такой внешней сущности как, например, "клиент". Объект "хранилище данных" является уникальным обозначением длительного хранения, очередности обработки, резерва документов.
Это представление потоков совместно с хранилищами данных и внешними сущностями делает модели DFD более похожими на физические характеристики системы — движение объектов, хранение объектов, поставка и распространение объектов.
Основой данной методологии графического моделирования информационных систем является специальная технология построения диаграмм потоков данных DFD. В разработке методологии DFD приняли участие многие аналитики, среди которых следует отметить Э. Йордона (Е. Yourdon). Он является автором одной из первых графических нотаций DFD. В настоящее время наиболее распространенной является так называемая нотация Гейна-Сарсона (Gene-Sarson), основные элементы которой будут рассмотрены в этом разделе.
Диаграммы потоков данных (DFD – Data Flow Diagram) являются основным средством моделирования функциональных требований проектируемой системы. С их помощью эти требования разбиваются на функциональные компоненты (процессы) и представляются в виде сети, связанной потоками данных. Главная цель таких средств – продемонстрировать, как каждый процесс преобразует свои входные данные в выходные, а также выявить отношения между этими процессами.
Система в контексте DFD представляется в виде некоторой информационной модели, основными компонентами которой являются различные потоки данных, которые переносят информацию от одной подсистемы к другой. Каждая из подсистем выполняет определенные преобразования входного потока данных и передает результаты обработки информации в виде потоков данных для других подсистем.
Для изображения DFD традиционно используются две различные нотации: Йодана (Yourdon) и Гейна-Сарсона (Gane-Sarson). Далее при построении примеров будет использоваться нотация Йодана, все исключения будут предварительно оговариваться.
На диаграммах функциональные требования представляются с помощью процессов и хранилищ, связанных потоками данных. Основные компоненты диаграмм потоков данных изображены на рис. 8. Опишем их назначение.
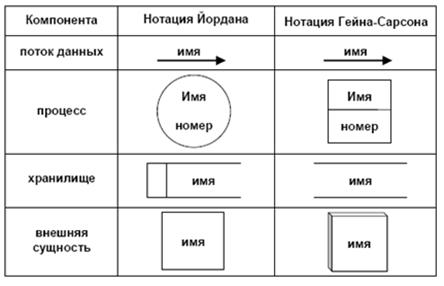
Рис. 8. Основные символы диаграммы потоков данных
Потоки данныхявляются механизмами, использующимися для моделирования передачи информации (или даже физических компонент) из одной части системы в другую. Важность этого объекта очевидна: он дает название целому инструменту. Потоки на диаграммах обычно изображаются именованными стрелками, ориентация которых указывает направление движения информации.
Назначение процессасостоит в продуцировании выходных потоков из входных в соответствии с действием, задаваемым именем процесса. Это имя должно содержать глагол в неопределенной форме с последующим дополнением (например, «вычислить максимальную высоту»). Кроме того, каждый процесс должен иметь уникальный номер для ссылок на него внутри диаграммы. Этот номер может использоваться совместно с номером диаграммы для получения уникального индекса процесса во всей модели.
Накопитель данных или хранилище представляет собой абстрактное устройство или способ хранения информации, перемещаемой между процессами. Хранилище (накопитель) данныхпозволяет на определенных участках определять данные, которые будут сохраняться в памяти между процессами. Фактически хранилище представляет «срезы» потоков данных во времени. Информация, которую оно содержит, может использоваться в любое время после ее определения, при этом данные могут выбираться в любом порядке. Имя хранилища должно идентифицировать его содержимое и быть существительным. В случае, когда поток данных входит или выходит в/из хранилища, и его структура соответствует структуре хранилища, он должен иметь то же самое имя, которое нет необходимости отражать на диаграмме.
Накопитель данных может быть физически реализован различными способами, но наиболее часто предполагается его реализация в электронном виде на магнитных носителях

Рис. 9. Изображение накопителя на диаграмме потоков данных
Внешняя сущность (терминатор)представляет сущность вне контекста системы, являющуюся источником или приемником системных данных. Ее имя должно содержать существительное, например, склад товаров. Предполагается, что объекты, представленные такими узлами, не должны участвовать ни в какой обработке. Примерами внешних сущностей могут служить: клиенты организации, заказчики, персонал, поставщики.
Дата добавления: 2016-01-07; просмотров: 2405;