Контекстная диаграмма и детализация процессов
Декомпозиция DFD осуществляется на основе процессов: каждый процесс может раскрываться с помощью DFD нижнего уровня.
Важную специфическую роль в модели играет специальный вид DFD - контекстная диаграмма, моделирующая систему наиболее общим образом.
Контекстная диаграмма отражает интерфейссистемы с внешним миром, а именно, информационные потоки между системой и внешними сущностями, с которыми она должна быть связана. Она идентифицирует эти внешние сущности, а также, как правило, единственный процесс, отражающий главную цель или природу системы насколько это возможно. И хотя контекстная диаграмма выглядит тривиальной, несомненная ее полезность заключается в том, что она устанавливает границы анализируемой системы. Каждый проект должен иметь ровно одну контекстную диаграмму, при этом нет необходимости в нумерации единственного ее процесса.
DFD первого уровня строится как декомпозиция процесса, который присутствует на контекстной диаграмме.
Построенная диаграмма первого уровня также имеет множество процессов, которые в свою очередь могут быть декомпозированы в DFD нижнего уровня. Таким образом, строится иерархия DFD с контекстной диаграммой в корне дерева. Этот процесс декомпозиции продолжается до тех пор, пока процессы могут быть эффективно описаны с помощью коротких (до одной страницы) миниспецификаций обработки (спецификаций процессов). При таком построении иерархии DFD каждый процесс более низкого уровня необходимо соотнести с процессом верхнего уровня. Обычно для этой цели используются структурированные номера процессов. Так, например, если мы детализируем процесс номер 2 на диаграмме первого уровня, раскрывая его с помощью DFD, содержащей три процесса, то их номера будут иметь следующий вид: 2.1, 2.2 и 2.3. При необходимости можно перейти на следующий уровень, т.е. для процесса 2.2 получим 2.2.1, 2.2.2. и т.д.
Декомпозиция данных и соответствующие расширения диаграмм потоков данных
Индивидуальные данные в системе часто являются независимыми. Однако иногда необходимо иметь дело с несколькими независимыми данными одновременно. Например, в системе имеются потоки яблоки, апельсины и груши. Эти потоки могут быть сгруппированы с помощью введения нового потока фрукты. Для этого необходимо определить формально поток фрукты как состоящий из нескольких элементов-потомков. Такое определение задается в словаре данных. В свою очередь поток фрукты сам может содержаться в потоке-предке еда вместе с потоками овощи, мясо и др. Такие потоки, объединяющие несколько потоков, получили название групповых.
Обратная операция, расщепление потоков на подпотоки, осуществляется с использованием группового узла (рис.38), позволяющего расщепить поток на любое число подпотоков. При расщеплении также необходимо формально определить подпотоки в словаре данных.
Аналогичным образом осуществляется и декомпозиция потоков через границы диаграмм, позволяющая упростить детализирующую DFD. Пусть имеется поток фрукты, входящий в детализируемый процесс. На детализирующей этот процесс диаграмме потока фрукты может не быть вовсе, но вместо него могут быть потоки яблоки и апельсины (как будто бы они переданы из детализируемого процесса). В этом случае должно существовать определение потока фрукты, состоящего из подпотоков яблоки и апельсины, для целей балансирования.
Применение этих операций над данными позволяет обеспечить структуризацию данных, увеличивает наглядность и читабельность диаграмм.
Для обеспечения декомпозиции данных и некоторых других сервисных возможностей к DFD добавляются следующие типы объектов.
1. Групповой узел.Предназначен для расщепления и объединения потоков.
В некоторых случаях может отсутствовать (т.е. фактически вырождаться в точку слияния/расщепления потоков на диаграмме).
2. Узел-предок.Позволяет увязывать входящие и выходящиепотоки между детализируемым процессом и детализирующей DFD.
3. Неиспользуемый узел.Применяется в ситуации, когда декомпозиция данных производится в групповом узле, при этом требуются не все элементы входящего в узел потока.
4. Узел изменения имени.Позволяет неоднозначно именовать потоки, при этом их содержимое эквивалентно. Например, если при проектировании разных частей системы один и тот же фрагмент данных получил различные имена, то эквивалентность соответствующих потоков данных обеспечивается узлом изменения имени. При этом один из потоков данных является входным для данного узла, а другой - выходным.
5. Текств свободном формате в любом месте диаграммы.
Возможный способ изображения этих узлов приведен на рис. 10.
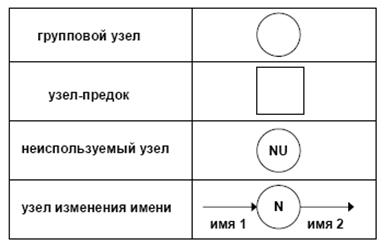
Рис. 10. Расширения диаграммы потоков данных
Построение модели
Главная цель построения иерархического множества DFD заключается в том, чтобы сделать требования ясными и понятными на каждом уровне детализации, а также разбить эти требования на части с точно определенными отношениями между ними. Для достижения этого целесообразно пользоваться следующими рекомендациями:
1. Размещать на каждой диаграмме от 3 до 6-7 процессов. Верхняя граница соответствует человеческим возможностям одновременного восприятия и понимания структуры сложной системы с множеством внутренних связей, нижняя граница выбрана по соображениям здравого смысла: нет необходимости детализировать процесс диаграммой, содержащей всего один или два процесса.
2. Не загромождать диаграммы несущественными на данном уровне деталями.
3. Декомпозицию потоков данных осуществлять параллельно с декомпозицией процессов; эти две работы должны выполняться одновременно, а не одна после завершения другой.
4. Выбирать ясные, отражающие суть дела, имена процессов и потоков для улучшения понимаемости диаграмм, при этом стараться не использовать аббревиатуры.
5. Однократно определять функционально идентичные процессы на самом верхнем уровне, где такой процесс необходим, и ссылаться на него на нижних уровнях.
6. Пользоваться простейшими диаграммными техниками: если что-либо возможно описать с помощью DFD, то это и необходимо делать, а не использовать для описания более сложные объекты.
7. Отделять управляющие структуры от обрабатывающих структур (т.е. процессов), локализовать управляющие структуры.
В соответствии с этими рекомендациями процесс построения модели разбивается на следующие этапы:
1. Расчленение множества требований и организация их в основные функциональные группы.
2. Идентификация внешних объектов, с которыми система должна быть связана.
3. Идентификация основных видов информации, циркулирующей между системой и внешними объектами.
4. Предварительная разработка контекстнойдиаграммы, на которой основные функциональные группы представляются процессами, внешние объекты – внешними сущностями, основные виды информации – потоками данных между процессами и внешними сущностями.
5. Изучение предварительной контекстной диаграммы и внесение в нее изменений по результатам ответов на возникающие при этом изучении вопросы по всем ее частям.
6. Построение контекстной диаграммы путем объединения всех процессов предварительной диаграммы в один процесс, а также группирования потоков.
7. Формирование DFD первого уровня на базе процессов предварительной контекстной диаграммы.
8. Проверка основных требований по DFD первого уровня.
9. Декомпозиция каждого процесса текущей DFD с помощью детализирующей диаграммы или спецификации процесса.
10. Проверка основных требований по DFD соответствующего уровня.
11. Добавление определений новых потоков в словарь данных при каждом их появлении на диаграммах.
12. Параллельное (с процессом декомпозиции) изучение требований (в том числе и вновь поступающих), разбиение их на элементарные и идентификация процессов или спецификаций процессов, соответствующих этим требованиям.
13. Проведение ревизии после построения двух-трех уровней с целью проверки корректности и улучшения понимаемости модели. Построение спецификации процесса (а не простейшей диаграммы) в случае, если некоторую функцию сложно или невозможно выразить комбинацией процессов.
Пример построения DFD диаграммы
В качестве примера создания модели рассмотрим фрагмент проекта системы обработки заказов клиентов и их обслуживания. Организация принимает от клиентов заказы на поставку товаров. Клиенту выписывается счет, после оплаты которого происходит отгрузка товара. Основными функциями системы являются выписка счета клиенту, прием оплаты от клиента, отгрузка товаров.
Построим контекстную диаграмму системы. Для этого изобразим основную функцию рассматриваемой системы и внешние по отношению к ней сущности, а также взаимосвязи между внешними сущностями и функцией системы.
Здесь сущность Склад является внешней по отношению к системе, т.к. рассматриваемая система не выполняет складских операций. Таким образом она лишь получает необходимую для работы информацию от Склада. Клиенты делают заказы на покупку товаров и получают товары, что изображено в виде стрелок с соответствующими наименованиями.

Рис. 11. Контекстная диаграмма системы «Обработка заказов клиентов»
После создания контекстной диаграммы, постараемся рассмотреть функции системы более подробно и построить в результате диаграмму детализации первого уровня. В начале рассмотрения примера было указано, что система должна выполнять три основных функции: выписка счета клиенту, прием оплаты от клиента, отгрузка товаров. Изобразим эти фукнции на диаграмме детализации, а также определим и изобразим хранилища данных и потоки данных между функциями, хранилищами и контекстной диаграммой.
Результат построения диаграммы детализации первого уровня представлен на рис.12.
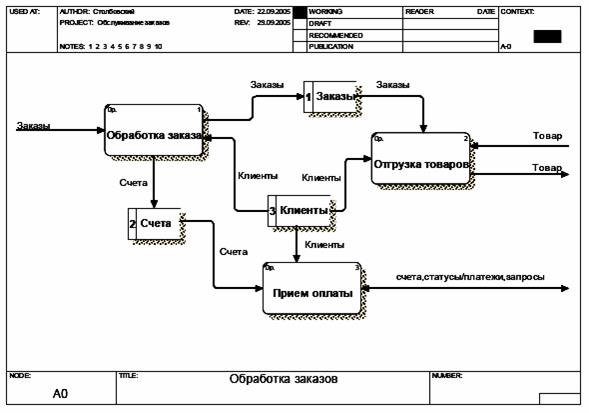
Рис. 12. Диаграмма детализации первого уровня системы «Обработка заказов клиентов»
Здесь, помимо трех функций системы представлены три хранилища, предназначенные для хранения данных о заказах, счетах и клиентах.
Рассмотренный пример является упрощенным и предназначен для знакомства с техникой построения как отдельных DFD диаграмм, так и их иерархии. Все рассмотренные выше принципы и техники построения подобных диаграмм применимы на практике.
Пример 2.Рассмотрим процесс СДАТЬ ЭКЗАМЕН. У нас есть две сущности СТУДЕНТ и ПРЕПОДАВАТЕЛЬ. Опишем потоки данных, которыми обменивается наша проектируемая система с внешними объектами.
Со стороны сущности СТУДЕНТ опишем информационные потоки. Для сдачи экзамена необходимо, чтобы у СТУДЕНТА была ЗАЧЕТКА, а также чтобы он имел ДОПУСК К ЭКЗАМЕНУ. Результатом сдачи экзамена, т.е. выходными потоками будут ОЦЕНКА ЗА ЭКЗАМЕН и ЗАЧЕТКА, в которую будет проставлена ОЦЕНКА.
Со стороны сущности ПРЕПОДАВАТЕЛЬ информационные потоки следующие: ЭКЗАМЕНАЦИОННАЯ ВЕДОМОСТЬ, согласно которой будет известно, что СТУДЕНТ допущен до экзамена, а также официальная бумага, куда будет занесен результат экзамена, т.е. ОЦЕНКА ЗА ЭКЗАМЕН, проставленная в ЭКЗАМЕНАЦИОННУЮ ВЕДОМОСТЬ.
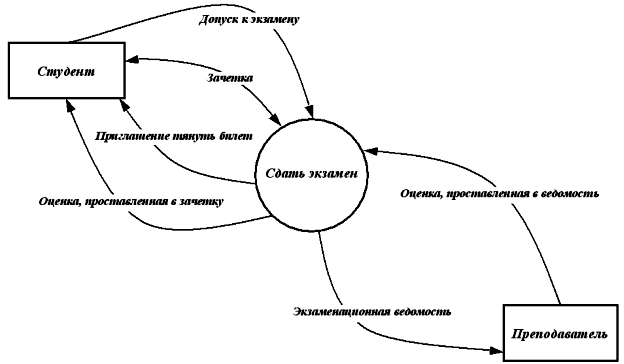
Рис. 13. DFD-диаграмма процесса «Сдать экзамен»
Теперь детализируем процесс СДАЧА ЭКЗАМЕНА. Этот процесс будет содержать следующие процессы (рис. 14): ВЫТЯНУТЬ БИЛЕТ {1.1}, ПОДГОТОВИТЬСЯ К ОТВЕТУ {1.2}, ОТВЕТИТЬ НА БИЛЕТ {1.3}, ПРОСТАВЛЕНИЕ ОЦЕНКИ{1.4}.
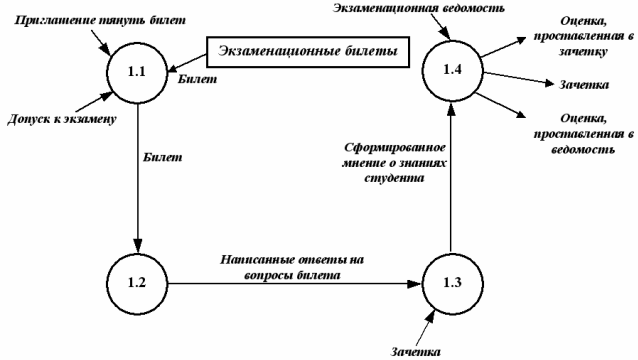
Рис. 14 Декомпозиция 1-го уровня DFD-диаграммы процесса «Сдать экзамен»
Пример 3.Построим DFD-диаграмму для предприятия, строящего свою деятельность по принципу "изготовление на заказ". На основании полученных заказов формируется план выпуска продукции на определенный период. В соответствии с этим планом определяются потребность в комплектующих изделиях и материалах, а также график загрузки производственного оборудования. После изготовления продукции и проведения платежей, готовая продукция отправляется заказчику.
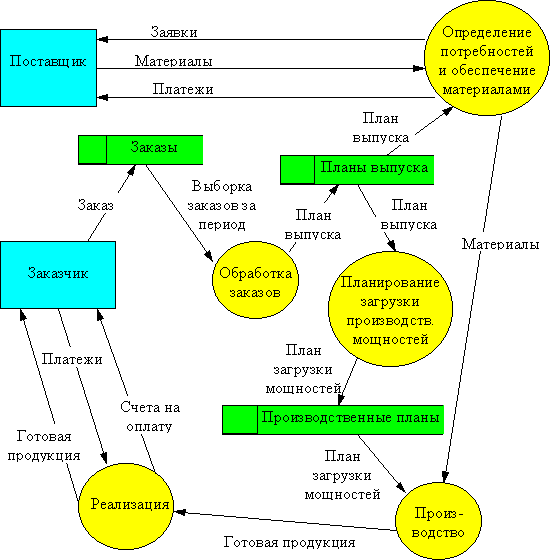
Рис. 15. DFD диаграмма процесса «Изготовление на заказ»
Эта диаграмма представляет самый верхний уровень функциональной модели. Естественно, это весьма грубое описание предметной области. Уточнение модели производится путем детализации необходимых функций на DFD-диаграмме следующего уровня. Так мы можем разбить функцию "Определение потребностей и обеспечение материалами" на подфункции "Определение потребностей", "Поиск поставщиков", "Заключение и анализ договоров на поставку", "Контроль платежей", "Контроль поставок", связанные собственными потоками данных, которые будут представлены на отдельной диаграмме. Детализация модели должна производится до тех пор, пока она не будет содержать всю информацию, необходимую для построения ифнормационной системы.
4.3. Диаграммы сущность-связь (ERD)
Цель моделирования данных состоит в обеспечении разработчика ИС концептуальной схемой базы данных в форме одной модели или нескольких локальных моделей, которые относительно легко могут быть отображены в любую систему баз данных.
Наиболее распространенным средством моделирования данных являются диаграммы "сущность-связь" (ERD). С их помощью определяются важные для предметной области объекты (сущности), их свойства (атрибуты) и отношения друг с другом (связи). ERD непосредственно используются для проектирования реляционных баз данных.
Наибольшее распространение получили следующие нотации, используемые при построении ER-диаграмм: нотация Чена, нотация Мартина, нотация DEF1X, нотация Баркера.
Данная нотация была предложена П. Ченом (P. Chen) в его известной работе 1976 года и получила дальнейшее развитие в работах Р. Баркера (R. Barker). Диаграммы "сущность-связь" (ERD) предназначены для графического представления моделей данных разрабатываемой программной системы и предлагают некоторый набор стандартных обозначений для определения данных и отношений между ними. С помощью этого вида диаграмм можно описать отдельные компоненты концептуальной модели данных и совокупность взаимосвязей между ними, имеющих важное значение для разрабатываемой системы.
Основными понятиями являются понятия сущности и связи. При этом под сущностью (entity) понимается произвольное множество реальных или абстрактных объектов, каждый из которых обладает одинаковыми свойствами и характеристиками. В этом случае каждый рассматриваемый объект может являться экземпляром одной и только одной сущности, должен иметь уникальное имя или идентификатор, а также отличаться от других экземпляров данной сущности.
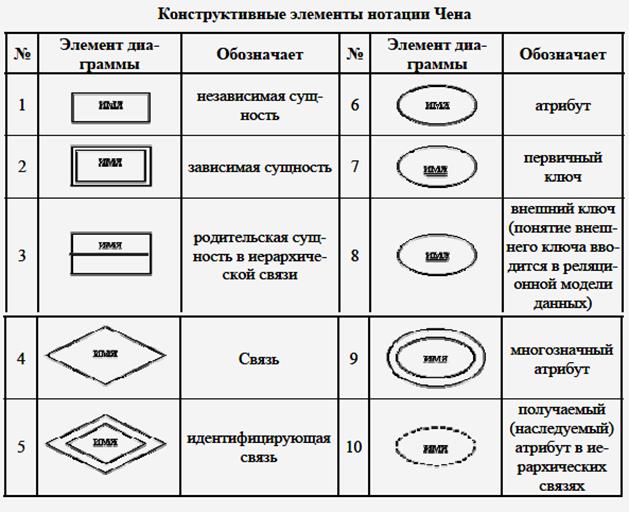
Примерами сущностей могут быть: банк, клиент банка, счет клиента, аэропорт, пассажир, рейс, компьютер, терминал, автомобиль, водитель. Каждая из сущностей может рассматриваться с различной степенью детализации и на различном уровне абстракции, что определяется конкретной постановкой задачи. Для графического представления сущностей используются специальные обозначения (рис. 16).

Рис. 16. Графические изображения для обозначения сущностей
Связь (relationship) определяется как отношение или некоторая ассоциация между отдельными сущностями. Примерами связей могут являться родственные отношения типа "отец-сын" или производственные отношения типа "начальник-подчиненный". Другой тип связей задается отношениями "иметь в собственности" или "обладать свойством". Различные типы связей графически изображаются в форме ромба с соответствующим именем данной связи (рис. 17).
Рис. 17. Графические изображения для обозначения связей
Графическая модель данных строится таким образом, чтобы связи между отдельными сущностями отражали не только семантический характер соответствующего отношения, а также кратность участвующих в данных отношениях экземпляров сущностей.
Рассмотрим в качестве простого примера ситуацию, которая описывается двумя сущностями: "Сотрудник" и "Компания". При этом в качестве связи естественно. использовать отношение принадлежности сотрудника данной компании. Если учесть соображения о том, что в компании работают несколько сотрудников, и эти сотрудники не могут быть работниками других компаний, то данная информация может быть представлена графически в виде следующей диаграммы "сущность-связь" (рис. 18). На данном рисунке буква "N" около связи означает тот факт, что в компании могут работать более одного сотрудника, при этом значение N заранее не фиксируется. Цифра "1" на другом конце связи означает, что сотрудник может работать только в одной конкретной компании, т. е. не допускается прием на работу сотрудников по совместительству из других компаний или учреждений.

Рис. 18. Диаграмма "сущность-связь" для примера сотрудников некоторой компании
Несколько иная ситуация складывается в случае рассмотрения сущностей "сотрудник" и "проект", и связи "участвует в работе над проектом" (рис. 19). Поскольку в общем случае один сотрудник может участвовать в разработке нескольких проектов, а в разработке одного проекта могут принимать участие несколько сотрудников, то данная связь является многозначной. Данный факт специально отражается на диаграмме указанием букв "N" и "М" около соответствующих сущностей, при этом выбор конкретных букв не является принципиальным.

Рис. 19. Диаграмма "сущность-связь" для примера сотрудников, участвующих в работе над проектами
Рассмотренные две диаграммы могут быть объединены в одну, на которой будет представлена информация о сотрудниках компании, участвующих в разработке проектов данной компании (рис. 20). При этом может быть введена дополнительная связь, характеризующая проекты данной компании.
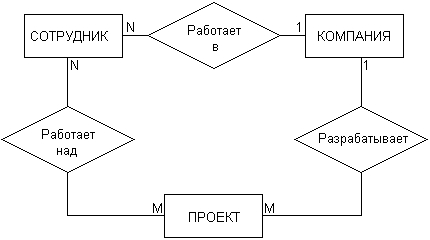
Рис. 20. Диаграмма "сущность-связь" для общего примера компании
На указанных диаграммах могут быть отражены более сложные зависимости между отдельными сущностями, которые отражают обязательность выполнения некоторых дополнительных условий, определяемых спецификой решаемой задачи и моделируемой предметной области. В частности, могут быть отражены связи подчинения одной сущности другой или введения ограничений на действие отдельных связей. В подобных случаях используются дополнительные графические обозначения, отражающие особенности соответствующей семантики.
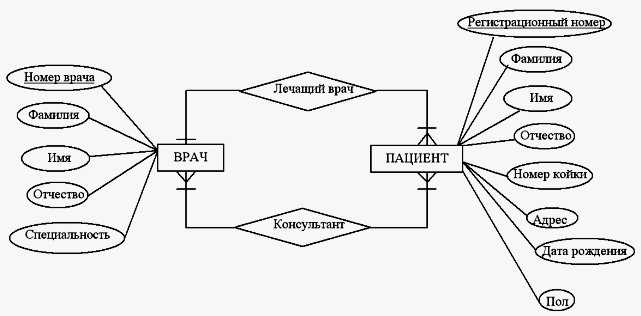
Рис. 21. Фрагмент концептуальной схемы в нотации Чена
4.4. Проектирование структур данных с использованием нотации IDEF1X/IE
На сегодняшний день наиболее проработанным и часто используемым подходом при проектировании структур данных информационных хранилищ является структурный подход. В рамках структурного подхода используются несколько нотаций, предназначенных для моделирования структур данных информационных систем. Наиболее распространенными из них сегодня являются IDEF1X и IE. Рассмотрим методологию и используемые в ее рамках нотации более подробно.
Уровни моделирования данных делятся на общие модели, изображающие сущности в общем не детализированном виде, содержащем сущности важные для рассматриваемой предметной области и модели, детально изображающие взаимосвязи между сущностями предметной области в терминах конкретной СУБД, выбранной для реализации модели данных. Таким образом, на самом нижнем уровне представления модели в значительной степени зависят от выбранной реализации (СУБД) и, следовательно, модель, созданная для использования в СУБД Access будет значительно отличаться от SQL Server и тем более Oracle. Модели верхнего уровня технологически независимы и могут содержать информацию об элементах, физически не сохраняемых в БД.
Таким образом, уровни создания информационной модели можно представить следующим образом (рис. 22).
Модели верхнего уровня делятся на две категории. ERD (Entity Relationship Diagram) диаграммы Сущность-связь содержат наиболее общие для рассматриваемой предметной области сущности и связи между ними. KB (Key Based) Models – Ключевые модели (модели, основанные на ключах) устанавливают границы требований к информации предметной области и содержат все ее сущности. В KB моделях начинают проявляться детали и особенности строения данных.
Модели нижнего уровня также делятся на две категории. FA (Fully Attributed) модель с полным набором атрибутов, все отношения которой приведены к третьей нормальной форме, содержащая все необходимые элементы для полной реализации базы данных. TM (Transformation Model) модель, представляющая собой трансформационную модель из реляционной в модель, предназначенную для реализации в конкретной СУБД с учетом ее особенностей. TM модель в большинстве случаев не удовлетворяет условиям третьей нормальной формы, т.к. она оптимизирована для использования в рамках конкретной СУБД с учетом ее особенностей и возможностей. В зависимости от уровня интеграции ИС физическая модель данных может быть как уровня системы в целом (глобальная модель), отображая взаимодействие информационных объектов масштаба ИС, так и уровня подсистем (локальная модель), отображая, соответственно, элементы, присущие только подсистемам ИС.
Заметим, что в идеальной ситуации должно существовать несколько локальных физических моделей, каждая из которых предназначена для своей подсистемы с возможностью взаимного использования элементов моделей.
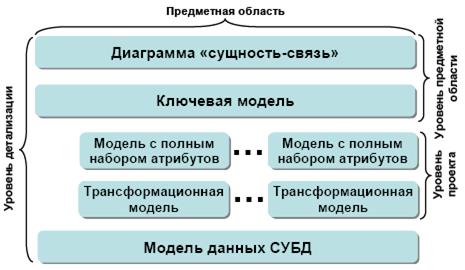
Рис. 22. Уровни создания моделей данных
Логические модели
Существует три уровня логических моделей, предназначенных для моделирования бизнес информации: диаграммы сущность-связь (ER), Ключевые модели (KB) и модели с полным набором атрибутов (FA). ER и KB модели также называют «моделями предметной области», т.к. они содержат элементы и их взаимосвязи внутри всей предметной области, являясь таким образом, более «широкими» по сравнению с моделями, используемыми для автоматизации в рамках конкретного проекта, охватывающего обычно часть предметной области. В свою очередь FA модели называют «моделями проекта», т.к. они обычно содержат описание части предметной области, необходимой в рамках решения конкретной задачи автоматизации.
ER диаграммы
ER диаграммы представляют собой диаграммы верхнего уровня, содержащие общие сущности и связи между ними отображающие общее представление о всей предметной области.
Основная цель ER диаграмм, является представление информации о бизнес требованиях, способных обеспечить возможность общего планирования разработки информационной системы. Эти модели не детализированы (содержат только общие сущности и атрибуты). В них возможно использовать связи между сущностями типа «многие-ко-многим», при этом ключевые атрибуты обычно не указываются. Это прежде всего модель для ее дальнейшего представления и обсуждения.
KB модели
KB модели описывают общие структуры данных, содержащие элементы в широких пределах предметной области. Сюда включаются все сущности и ключевые атрибуты, а также основные неключевые атрибуты.
Основная цель KB моделей дать широкое представление о сущностях и атрибутах, используемых в данной части предметной области. Эти модели создают возможность для построения детализированных моделей реализации. KB модели охватывают ту же область что и ER модели предметной области, но содержат больше деталей.
FA модели
FA модели представляют собой модели данных, приведенные к третьей нормальной форме, содержащие все сущности, атрибуты и связи необходимые для реализации в рамках одного проекта автоматизации. Данная модель включает размер экземпляра сущности, пути и скорость доступа, а также образцы возможностей доступа к данным.
Физические модели
Существует также два типа физических моделей: трансформационные модели и модели, привязанные к СУБД. Физические модели содержат всю необходимую для реализации разработчиками базы данных на основе логической модели. Трансформационная модель является также «проектной моделью», описывающей часть общей структуры данных, необходимой в рамках создания одного проекта (части создания интегрированной ИС).
Дата добавления: 2016-01-07; просмотров: 20770;