ПРЕДСТАВЛЕНИЕ ДАННЫХ В СУБД
3.1. Иерархическая модель представления данных
Иерархическая модель данных — логическая модель данных в виде древовидной структуры. Иерархическая модель данных представляет собой совокупность элементов, расположенных в порядке их подчинения от общего к частному и образующих перевернутое дерево (граф). Данная модель характеризуется такими параметрами, как уровни, узлы, связи. Принцип работы модели таков, что несколько узлов более низкого уровня соединяется при помощи связи с одним узлом более высокого уровня.
Часто организацию данных в СУБД иерархического типа определяется в терминах: элемент, агрегат, запись (группа), групповое отношение, база данных.
· Атрибут (элемент данных)- наименьшая единица структуры данных. Обычно каждому элементу при описании базы данных присваивается уникальное имя. По этому имени к нему обращаются при обработке. Элемент данных также часто называют полем.
· Запись - именованная совокупность атрибутов. Использование записей позволяет за одно обращение к базе получить некоторую логически связанную совокупность данных. Именно записи изменяются, добавляются и удаляются. Тип записи определяется составом ее атрибутов. Экземпляр записи - конкретная запись с конкретным значением элементов
· Групповое отношение - иерархическое отношение между записями двух типов. Родительская запись (владелец группового отношения) называется исходной записью, а дочерние записи (члены группового отношения) - подчиненными. Иерархическая база данных может хранить только такие древовидные структуры.
Корневая запись каждого дерева обязательно должна содержать ключ с уникальным значением. Ключи некорневых записей должны иметь уникальное значение только в рамках группового отношения. Каждая запись идентифицируется полным сцепленным ключом, под которым понимается совокупность ключей всех записей от корневой по иерархическому пути.
При графическом изображении групповые отношения изображают дугами ориентированного графа, а типы записей - вершинами (диаграмма Бахмана).
Для групповых отношений в иерархической модели обеспечивается автоматический режим включения и фиксированное членство. Это означает, что для запоминания любой некорневой записи в БД должна существовать ее родительская запись (подробнее о режимах включения и исключения записей сказано в параграфе о сетевой модели). При удалении родительской записи автоматически удаляются все подчиненные.
Пример:
Рассмотрим следующую модель данных предприятия (рис. 3). Предприятие состоит из отделов, в которых работают сотрудники. В каждом отделе может работать несколько сотрудников, но сотрудник не может работать более чем в одном отделе.
Поэтому, для информационной системы управления персоналом необходимо создать групповое отношение, состоящее из родительской записи ОТДЕЛ (НАИМЕНОВАНИЕ_ОТДЕЛА, ЧИСЛО_РАБОТНИКОВ) и дочерней записи СОТРУДНИК (ФАМИЛИЯ, ДОЛЖНОСТЬ, ОКЛАД). Это отношение показано на рис. 3(а) (Для простоты полагается, что имеются только две дочерние записи).
Для автоматизации учета контрактов с заказчиками необходимо создание еще одной иерархической структуры : заказчик - контракты с ним - сотрудники, задействованные в работе над контрактом. Это дерево будет включать записи ЗАКАЗЧИК(НАИМЕНОВАНИЕ_ЗАКАЗЧИКА, АДРЕС), КОНТРАКТ(НОМЕР, ДАТА,СУММА), ИСПОЛНИТЕЛЬ (ФАМИЛИЯ, ДОЛЖНОСТЬ, НАИМЕНОВАНИЕ_ОТДЕЛА) (рис. 3(b)).
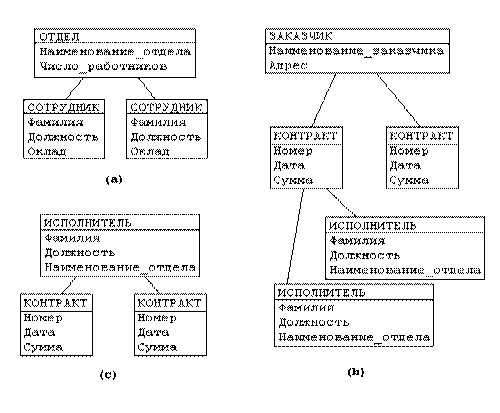
Рис. 3. Иерархическая модель данных предприятия
Из этого примера видны недостатки иерархических БД:
· Частично дублируется информация между записями СОТРУДНИК и ИСПОЛНИТЕЛЬ (такие записи называют парными), причем в иерархической модели данных не предусмотрена поддержка соответствия между парными записями.
· Иерархическая модель реализует отношение между исходной и дочерней записью по схеме 1:N, то есть одной родительской записи может соответствовать любое число дочерних. Допустим теперь, что исполнитель может принимать участие более чем в одном контракте (т.е. возникает связь типа M:N). В этом случае в базу данных необходимо ввести еще одно групповое отношение, в котором ИСПОЛНИТЕЛЬ будет являться исходной записью, а КОНТРАКТ - дочерней (рис. (c)). Таким образом, мы опять вынуждены дублировать информацию.
Операции над данными, определенные в иерархической модели:
· ДОБАВИТЬ в базу данных новую запись. Для корневой записи обязательно формирование значения ключа.
· ИЗМЕНИТЬ значение данных предварительно извлеченной записи. Ключевые данные не должны подвергаться изменениям.
· УДАЛИТЬ некоторую запись и все подчиненные ей записи.
· ИЗВЛЕЧЬ:
o извлечь корневую запись по ключевому значению, допускается также последовательный просмотр корневых записей
o извлечь следующую запись (следующая запись извлекается в порядке левостороннего обхода дерева)
В операции ИЗВЛЕЧЬ допускается задание условий выборки (например, извлечь сотрудников с окладом более 1 тысячи руб.)
Как видим, все операции изменения применяются только к одной "текущей" записи (которая предварительно извлечена из базы данных). Такой подход к манипулированию данных получил название "навигационного".
3.2. Сетевая модель представления данных
Сети - естественный способ представления отношений между объектами. Они широко применяются в математике, исследованиях операций, химии, физике, социологии и других областях знаний. Сети обычно могут быть представлены математической структурой, которая называется направленным графом. Направленный граф имеет простую структуру. Он состоит из точек или узлов, соединенных стрелками или ребрами. В контексте моделей данных узлы можно представлять как типы записей данных, а ребра представляют отношения один-к-одному или один-ко-многим. Структура графа делает возможными простые представления иерархических отношений (таких, как генеалогические данные) .
Сетевая модель данных - это представление данных сетевыми структурами типов записей и связанных отношениями мощности один-к-одному или один-ко-многим. В конце 60-х конференция по языкам систем данных (Conference on Data Systems Languages, CODASYL) поручила подгруппе, названной Database Task Group (DTBG), разработать стандарты систем управления базами данных. На DTBG оказывала сильное влияние архитектура, использованная в одной из самых первых СУБД, Iategrated Data Store (IDS), созданной ранее компанией General Electric.Это привело к тому, что была рекомендована сетевая модель.
Документы Database Task Group (DTBG) (группа для разработки стандартов систем управления базами данных) от 1971 года остается основной формулировкой сетевой модели, на него ссылаются как на модель CODASYL DTBG. Она послужила основой для разработки сетевых систем управления базами данных нескольких производителей. IDS (Honeywell) и IDMS (Computer Associates) - две наиболее известных коммерческих реализации. В сетевой модели существует две основные структуры данных: типы записей и наборы:
· Тип записей. Совокупность логически связанных элементов данных.
· Набор. В модели DTBG отношение один-ко-многим между двумя типами записей.
· Простая сеть. Структура данных, в которой все бинарные отношения имеют мощность один-ко-многим.
· Сложная сеть. Структура данных, в которой одно или несколько бинарных отношений имеют мощность многие-ко-многим.
· Тип записи связи. Формальная запись, созданная для того, чтобы преобразовать сложную сеть в эквивалентную ей простую сеть.
В модели DBTG возможны только простые сети, в которых все отношения имеют мощность один-к-одному или один-ко-многим. Сложные сети, включающие одно или несколько отношений многие-ко-многим, не могут быть напрямую реализованы в модели DBTG. Следствием возможности создания искусственных формальных записей является необходимость дополнительного объема памяти и обработки, однако при этом модель данных имеет простую сетевую форму и удовлетворяет требованиям DBTG.
Иерархическая структура преобразовывается в сетевую следующим образом (рис. 4):
· древья (a) и (b), показанные на рис. 3, заменяются одной сетевой структурой, в которой запись СОТРУДНИК входит в два групповых отношения;
· для отображения типа M:N вводится запись СОТРУДНИК_КОНТРАКТ, которая не имеет полей и служит только для связи записей КОНТРАКТ и СОТРУДНИК, см. рис. 4.(Отметим, что в этой записи может храниться и полезная информация, например, доля данного сотрудника в общем вознаграждении по данному контракту.)
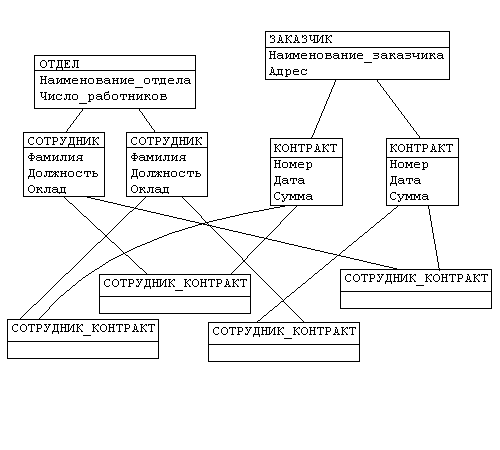
Рис. 4. Сетевая модель данных предприятия
Реализация групповых отношений в сетевой модели осуществляется с использованием специально вводимых дополнительных полей - указателей (адресов связи или ссылок), которые устанавливают связь между владельцем и членом группового отношения. Запись может состоять в отношениях разных типов (1:1, 1:N, M:N). Заметим, что если один из вариантов установления связи 1:1 очевиден (в запись – владелец отношения, поля которой соответствуют атрибутам сущности, включается дополнительное поле – указатель на запись – член отношения), то возможность представления связей 1:N и M:N таким же образом весьма проблематична. Поэтому наиболее распространенным способом организации связей в сетевых СУБД является введение дополнительного типа записей (и соответственно, дополнительного файла), полями которых являются указатели.
Наиболее существенным недостатком сетевой модели является "жесткость" получаемой концептуальной схемы. Связи закреплены в записях в виде указателей. При появлении новых аспектов использования этих же данных может возникнуть необходимость установления новых связей между ними. Это требует введения в записи новых указателей, т.е. изменения структуры БД, и, соответственно, переформирования всей базы данных.
СУБД, поддерживающие сетевую модель, широко использовались на вычислительных системах серии IBM 360/370 (ЕС ЭВМ). В качестве примеров таких систем можно указать IDMS, UNIBAD (БАНК), и их аналоги СЕДАН, СЕТОР. На персональных компьютерах сетевые СУБД не получили широкого распространения. Примером сетевой СУБД для персонального компьютера является db_VISTA III. Отметим, что система db_VISTA реализована на языке С и поэтому является переносимой. Система может эксплуатироваться на ПЭВМ типа IBM PC, SUN, Macintosh.
3.3. Реляционная модель представления данных
Учитывая отмеченные в предыдущих разделах недостатки сетевых и иерархических моделей, можно сформулировать желательные требования к модели данных:
· модель должна быть понятна пользователю, не имеющему особых навыков в программировании;
· появление новых аспектов использования данных и необходимость введения новых связей не должны приводить к реструктуризации всей модели данных и базы данных в целом.
Моделью данных, удовлетворяющей вышеуказанным требованиям, является реляционная модель, часто называемая также табличной.
Основным используемым понятиям здесь является понятие отношения, представляемого в виде таблицы, столбцы которой соответствуют атрибутам сущности (структура строки таблицы аналогична структуре записи). Каждый атрибут может принимать определенное множество значений, называемое доменом. Строка таблицы с конкретными значениями полей здесь называется кортежем (соответствует понятию "экземпляр записи"). Поля таблицы предполагаются элементарными (неделимыми). Таким образом, понятие "таблица" здесь соответствует понятию "файл" модели данных. Первичный ключ здесь – минимальный набор атрибутов, однозначно идентифицирующий кортеж в отношении.
В отличие от иерархической и сетевой моделей данных в реляционной отсутствует понятие группового отношения. Для отражения ассоциаций между кортежами разных отношений используется дублирование их ключей. Рассмотренный ранее пример базы данных, содержащей сведения о подразделениях предприятия и работающих в них сотрудниках, применительно к реляционной модели будет иметь вид:
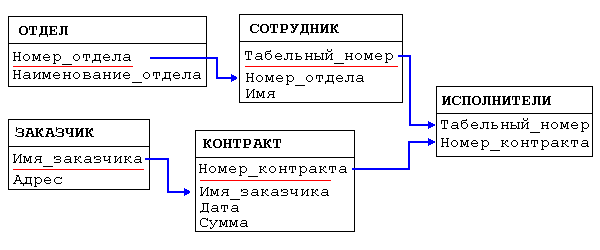
Рис. 5. База данных о подразделениях и сотрудниках предприятия.
Например, связь между отношениями ОТДЕЛ и СОТРУДНИК создается путем копирования первичного ключа "Номер_отдела" из первого отношения во второе. Таким образом:
· для того, чтобы получить список работников данного подразделения, необходимо
1. из таблицы ОТДЕЛ установить значение атрибута "Номер_отдела", соответствующее данному "Наименованию_отдела"
2. выбрать из таблицы СОТРУДНИК все записи, значение атрибута "Номер_отдела" которых равно полученному на предыдушем шаге.
· для того, чтобы узнать в каком отделе работает сотрудник, нужно выполнить обратную операцию:
1. определяем "Номер_отдела" из таблицы СОТРУДНИК
2. по полученному значению находим запись в таблице ОТДЕЛ.
Атрибуты, представляющие собой копии ключей других отношений, называются внешними ключами.
Таким образом, реляционная модель представления данных представляет собой модель, в которой данные хранятся в виде таблиц, между которыми установлены определенные связи. Для работы с такими моделями данных с использованием языка Java предлагается следующая схема:
Пошаговая инструкция.
Связь с базой данных с помощью JDBC.
1. Установка связи между Java-программой и диспетчером базы данных.
2. Передача SQL-команды в базу данных с помощью объекта Statement.
3. Чтение полученных результатов из базы данных и использование их в программе.
Первый этап
Первый этап включает в себя подключение драйвера базы данных и непосредственно подключение к ней. Реализация этого этапа представляется следующим образом:
Class.forName(“org.gjt.mm.mysql.Driver”);
Conection connection=DriverManager.getConnection (“jdbc:mysql://localhost:3306/NewsDB”, “User”, “Password”);
После регистрации драйвера с помощью диспетчера драйверов его можно применять для подключения к базе данных. Для этого диспетчеру драйверов следует сообщить о создании нового подключения. В ответ на это диспетчер драйверов вызовет соответствующий драйвер и возвратит ссылку на установленное подключение. Для создания подключения необходимо указать место расположения базы данных, а также (как правило, для большинства баз данных) учетное имя и пароль.
Второй этап
Объект Statement предназначен для хранения SQL-команд. При пересылке объекта Statement базе данных с помощью установленного подключения СУБД запустит заданную SQL-команду и возвратит результат ее выполнения в виде объекта ResultSet.
Реализация второго этапа выглядит так:
Statement statement=connection.createStatement();
ResultSet=statement.executeQuery(“select * from vus”);
Третий этап
Работа с результатами выполнения запроса.Объект ResultSet функционирует как курсор, в котором доступ к отдельной строке можно осуществить с помощью команды SELECT. Для перехода к следующей строке необходимо вызвать метод next(), который возвращает логическое значение, например значение false возвращается после перебора всех строк, т.е. когда следующей строки уже нет.
Внутри строки содержимое столбцов считывается в порядке слева направо. (Напомним. что команду SELECT можно использовать для выборки необходимых для работы столбцов в заданном порядке.) Специалистами фирмы Sun разработаны методы qetTun() для всех основных типов данных, которые совместимы с SQL.
Рассмотрим пример.
ResultSet theResults =
theStatement.executeQuery
("SELECT title, author, retailPrice FROM books");
while (theResults.next())
{
String theTitle = theResults.getString("title");
String theAuthor = theResults.getString("author");
float thePrice = theResults.getFloat("retailPrice");
System.out.println(theTitle + " " + theAuthor + " " + thePrice. toString());
}
Код будет более понятным, если извлекать столбцы по их названию, но для небольшого повышения производительности их можно извлекать и по порядковому номеру, как показано в следующем примере:
float thePrice = theResults.getFloat(3);
По окончании работы с объектами Statement и Connection для них обоих рекомендуется вызвать метод close (). Это позволяет высвободить ресурсы, как правило, задолго до того. как сборщик мусора приступит к своей работе.
Пример подключения к базе данных MySql
Приведем пример подключения и работы с базой данных MySql:
import java.sql.*;
………
try {
Class.forName(“org.gjt.mm.mysql.Driver”);
Conection connection=DriverManager.getConnection (“jdbc:mysql://localhost:3306/NewsDB”, “User”, “Password”);
Statement statement=connection.createStatement();
}
catch (ClassNotFoundExeception e)
{
System.out.println(“Cannot connection to database”);
}
catch (SQLException e)
{
System.out.println(“Cannot connection to database”);
}
ResultSet=statement.executeQuery(“select * from vus”);
while (rs.next())
{
String idS=rs.getString(1);
System.out.println(“строка=”+idS);
}
rs.close();
statement.close();
connection.close();
3.4 Теория нормальных форм
Реляционная база данных содержит как структурную, так и семантическую информацию. Структура базы данных определяется числом и видом включенных в нее отношений, и связями типа "один ко многим", существующими между кортежами этих отношений. Семантическая часть описывает множество функциональных зависимостей, существующих между атрибутами этих отношений. Дадим определение функциональной зависимости.
Определение:
Если даны два атрибута X и Y некоторого отношения, то говорят, что Y функционально зависит от X, если в любой момент времени каждому значению X соответствует ровно одно значение Y.
Функциональная зависимость обозначается X -> Y. Отметим, что X и Y могут представлять собой не только единичные атрибуты, но и группы, составленные из нескольких атрибутов одного отношения.
Можно сказать, что функциональные зависимости представляют собой связи типа "один ко многим", существующие внутри отношения.
Некоторые функциональные зависимости могут быть нежелательны.
Определение:
Избыточная функциональная зависимость - зависимость, заключающая в себе такую информацию, которая может быть получена на основе других зависимостей, имеющихся в базе данных.
Корректной считается такая схема базы данных, в которой отсутствуют избыточные функциональные зависимости. В противном случае приходится прибегать к процедуре декомпозиции (разложения) имеющегося множества отношений. При этом порождаемое множество содержит большее число отношений, которые являются проекциями отношений исходного множества. (Операция проекции описана в разделе, посвященном реляционной алгебре). Обратимый пошаговый процесс замены данной совокупности отношений другой схемой с устранением избыточных функциональных зависимостей называется нормализацией.
Условие обратимости требует, чтобы декомпозиция сохраняла эквивалентность схем при замене одной схемы на другую, т.е. в результирующих отношениях:
· не должны появляться ранее отсутствовавшие кортежи;
· на отношениях новой схемы должно выполняться исходное множество функциональных зависимостей.
Дата добавления: 2016-01-07; просмотров: 2795;