Приближение разной вероятности встречаемости символов в тексте
В этом приближении учитывается, что в реальном тексте разные символы встречаются с разной частотой. Отсюда следует, что вероятности появления разных символов в определенной позиции текста различны и, следовательно, различаются их информационные веса.
Статистический анализ русских текстов показывает, что частота появления буквы “о” составляет 0,09. Это значит, что на каждые 100 символов буква “о” в среднем встречается 9 раз. Это же число обозначает вероятность появления буквы “о” в определенной позиции текста: po = 0,09.Отсюда следует, что информационный вес буквы “о” в русском тексте равен:
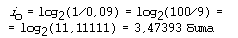
Самой редкой в текстах буквой является буква “ф”. Ее частота равна 0,002. Отсюда:
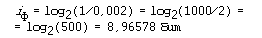
Отсюда следует качественный вывод: информационный вес редких букв больше, чем вес часто встречающихся букв.
Как же вычислить информационный объем текста с учетом разных информационных весов символов алфавита? Делается это по следующей формуле:
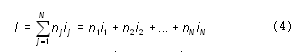
Здесь N — размер (мощность) алфавита; nj — число повторений символа номер j в тексте; ij — информационный вес символа номер j.
Дата добавления: 2015-12-26; просмотров: 1115;