Предъявите ваш геном. Чтение ДНК, геномный анализ, геномные войны, персонализированная медицина, метагеномика
В 1964 году американский биохимик Роберт Холли с коллегами установили последовательность нуклеотидов молекулы транспортной РНК, необходимой для присоединения аминокислоты аланина к синтезирующимся аминокислотным последовательностям белков263. За это открытие в 1968 году им дали Нобелевскую премию. В 1972-м в лаборатории бельгийского молекулярного биолога Вальтера Фьера впервые в истории была установлена последовательность нуклеотидов белок-кодирующего гена. Это был ген оболочки бактериофага MS2264, а вскоре стали известны и другие последовательности генов этого вируса79. В те времена “прочитать" последовательность какого-нибудь гена было все еще настолько серьезным достижением, что, сделав это, можно было смело публиковать статью в престижном научном журнале Nature.
Сегодня прочитанных последовательностей ДНК различных организмов так много, что ученые не всегда успевают их обработать и проанализировать, чтобы хотя бы разобраться, где среди них гены, где регулирующие области, а где всякий ненужный мусор. Забегая немного вперед, скажу, что проект чтения генома человека обошелся в несколько миллиардов долларов и занял более тринадцати лет. С тех пор технология чтения ДНК так сильно подешевела, что при желании любой из нас, обладая средним уровнем дохода, может взять и прочитать своей собственный геном, записать его последовательность на флешку и гордо носить ее на шее. Обойдется это всего в несколько тысяч долларов, но спешить не стоит: в скором времени реализовать такую идею станет еще дешевле. А может быть, в обозримом будущем это и вовсе сделают обязательным требованием для получения медицинской страховки или посещения поликлиники.
Изменилось отношение к чтению ДНК и в научном мире: статья не то что о гене, но даже о полном геноме, содержащем тысячи генов, едва ли произведет большое впечатление и удостоится страниц самых известных научных журналов. Разве что речь пойдет о геноме какого-то совершенно уникального организма, чьи генетические данные радикально меняют представление об эволюции жизни на Земле. Как мы пришли к тому, что читать последовательности ДНК стало так легко?
В 1977 году Уолтер Гилберт и Аллан Максам предложили первый метод чтения ДНК265. Образец ДНК, содержащий анализируемую последовательность, помещали в четыре пробирки. В каждой из пробирок проводились химические реакции, в ходе которых нуклеотидные последовательности разрезались после разных букв. В первой пробирке молекула ДНК разрезалась после нуклеотидов А или G, во второй – после нуклеотида A, в третьей – после C, а в четвертой – после С или T. В итоге получались фрагменты всевозможной длины. Продукты реакций помещали в четыре параллельные лунки, проделанные внутри специального геля, через который пускали ток.
ДНК – дезоксирибонуклеиновая кислота, а раз это кислота, значит, в растворе она отдает протон и становится отрицательно заряженной молекулой. Поэтому при включении тока молекулы ДНК начинают бежать от отрицательного плюса к положительному. Маленькие молекулы бегут быстрее, чем длинные, которые застревают в геле, и таким образом нарезанные фрагменты ДНК выстраиваются по длине. Эта процедура упорядочивания молекул ДНК при помощи тока называется гель-электрофорезом.
До помещения в лунки ДНК помечалась радиоактивными метками. После электрофореза на гель накладывалась специальная пленка, которая засвечивалась радиоактивным излучением от меченой ДНК, и ученые получали снимок, где были видны четыре дорожки с чередующимися полосами. Глядя на эти полосы, можно было установить последовательность нуклеотидов анализируемого фрагмента ДНК. Давайте представим, как бы выглядел набор полученных полос для следующей последовательности ДНК: GATTACA.

Самый короткий фрагмент заканчивается нуклеотидом G. Он “убежит" вперед и со временем окажется ближе всех к положительному полюсу. После нуклеотида G разрезание происходило только в первой пробирке, поэтому мы видим одну полосу в крайнем левом ряду. Второй по длине фрагмент заканчивается на нуклеотид А. После этого нуклеотида разрезы происходили в первой и второй пробирках, поэтому мы видим полосы в двух левых рядах. Чтение ДНК по таким снимкам напоминало чтение музыкальных нот с листа, только в этом процессе, как правило, участвовало двое ученых: один, глядя на снимок, называл нуклеотиды, а другой записывал букву за буквой.
К сожалению, мы бы скорее успели колонизировать Марс, чем прочитать геном человека, используя этот метод. Человечество нуждалось в более совершенных методах чтения ДНК. В самой крупной базе данных научных публикаций Web of Science находится более 2,3 миллиона статей, в которых упоминается DNA (ДНК). Среди них на первом месте по количеству цитирований – статья, опубликованная все в том же 1977 году в журнале PNAS британским биохимиком Фредериком Сенгером266. На эту статью ссылались более 65 тысяч раз! Почти вдвое больше, чем на следующую в рейтинге. Сенгер описал метод “терминации цепи", который произвел настоящую революцию в области чтения ДНК благодаря удобной автоматизации процесса. В основе метода лежат особые “терминирующие нуклеотиды", которые отличаются от обычных тем, что стоит им встроиться в растущую нуклеотидную цепь, и синтез останавливается. Это происходит потому, что у меченых нуклеотидов нет З’-конца, к которому мог бы присоединиться следующий нуклеотид.
Для анализа ДНК по методу Сенгера, как и в случае с методом Гилберта и Максама, нужно было использовать четыре пробирки. Во все пробирки добавлялись анализируемый образец ДНК, ДНК-полимераза и обычные нуклеотиды. Кроме того, в каждую из пробирок добавлялось небольшое количество терминирующих нуклеотидов одного из четырех типов, помеченных радиоактивной меткой. Наконец, в каждую пробирку добавлялись праймеры. Обычно праймеры синтезируются путем последовательного химического соединения нуклеотидов. Они подбираются комплементарными некоторому уже известному участку анализируемой молекулы ДНК, продолжение которой мы хотим прочитать. Без праймеров ДНК-полимераза не может начать синтез.
В каждой из четырех пробирок происходит синтез ДНК, праймеры достраиваются до полноразмерных цепочек, последовательности растут, но как только присоединяется терминирующий нуклеотид, синтез останавливается, и чем раньше это произойдет, тем короче получится фрагмент ДНК. Поскольку терминирующие нуклеотиды представляют небольшую долю от общего числа нуклеотидов в смеси, получаются как короткие, так и длинные фрагменты ДНК. Дальше продукты реакций из четырех пробирок наносятся на гель (каждый в свою лунку), через который пускается ток. Фрагменты выстраиваются по длине, делается снимок радиоактивности, по которому восстанавливается последовательность ДНК.

В 1985 году метод Сенгера был доработан в лаборатории Лероя Худа. Там придумали, как заменить радиоактивную метку на четыре типа флуоресцентных меток: были получены терминирующие нуклеотиды, каждый из которых имел свой цвет267. Теперь все реакции можно было проводить в одной пробирке. Поскольку окрашены только терминирующие нуклеотиды, а при их присоединении синтез ДНК останавливается, каждая молекула ДНК будет окрашена в тот цвет, в который был окрашен последний присоединенный к ней (терминирующий) нуклеотид. Как и раньше, терминирующих нуклеотидов добавлялось совсем немного, чтобы получались последовательности всех возможных длин. Эти последовательности разделялись по длине на геле, но дальнейший анализ делала машина, которая самостоятельно считывала цвет каждой полоски на геле и определяла по цвету, какая там буква. Так был создан прибор для автоматизированного чтения ДНК.
В 1980 году Сенгер получил вторую Нобелевскую премию по химии (первая была присуждена ему еще в 1958-м за определение аминокислотной последовательности белка инсулина – первого прочитанного белка), а его метод в различных модификациях еще долгие годы был основным методом чтения ДНК. Сначала с его помощью был прочитан первый ДНК-геном – геном бактериофага 9X174, длиной 5386 нуклеотидов, потом в 1995 году был прочитан первый полный геном клеточного организма, гемофильной палочки Haemophilus influenzae 268, возбудителя пневмонии и менингита. Геном этой бактерии имел длину 1830137 нуклеотидов! В 1998 году был прочитан первый геном многоклеточного животного, круглого червя Caenorhabditis elegans 269 (уже 98 миллионов нуклеотидов!). В 2000-м – первый растительный геном Arabidopsis thaliana270 (157 миллионов нуклеотидов!). Тем временем уже вовсю шла работа над проектом по чтению генома человека, количество нуклеотидов в котором, как мы уже знаем, около трех миллиардов.
Идея прочитать геном человека родилась еще в 1986 году по инициативе Министерства энергетики США – впоследствии оно же финансировало проект вместе с Национальными институтами здравоохранения США. При стоимости в 3 миллиарда долларов проект, в котором участвовали Китай, Германия, Франция, Великобритания и Япония, был рассчитан на 15 лет. Директором проекта по чтению генома человека был Джеймс Уотсон, один из первооткрывателей структуры молекулы ДНК, пока его не сменил Фрэнсис Коллинз.
Позволю себе предположить, что международный проект по чтению генома человека затянулся бы не на тринадцать, а на все двадцать лет, если бы не старания весьма амбициозного ученого – Крейга Вентера. Крейг Вентер и его компания Celera Genomics, основанная в 1998 году, сыграли примерно такую же роль в истории геномики, как Советский Союз в истории полета американцев на Луну. Вентер заявил, что его компания закончит расшифровку генома человека раньше, чем завершится международный проект, а именно к 2001 году. Международный проект задерживался и, по новым оценкам, должен был завершиться в 2005-м. Причем сделать геном человека Вентер собирался не за миллиарды долларов, а всего за 300 миллионов благодаря новому подходу к чтению ДНК, названному whole genome shotgun (раздробление генома, или “метод дробовика") и основанному на фрагментации ДНК и чтении случайных коротких участков генома в произвольном порядке.
“Мы сделаем геном человека, а вы можете сделать мышь”, – ехидно предложил Вентер своим конкурентам.
Этот период вошел в историю геномики как время “геномных войн". Научное сообщество всполошилось! Дело было не только в том, что Вентер собирался утереть нос членам уважаемых международных коллективов, но и в том, что компания Celera Genomics собиралась заработать на проекте, создав полную базу данных генетических последовательностей, платную для всех, кто хотел бы пользоваться ею в коммерческих целях. В первую очередь это касалось фармацевтических компаний. Тогда шли острые споры о возможности патентования генетических последовательностей, и было неясно, что случится, если первой до генома человека доберется коммерческая Celera, а не финансируемые из бюджета научные организации.
Чем отличается метод дробления ДНК от тех методов, которые использовал международный консорциум по чтению генома человека? Обычные методы подразумевают последовательный анализ генома: мы шагаем по хромосомам, читая фрагмент за фрагментом. Концы предыдущих прочитанных фрагментов выступают затравками для чтения новых и так далее. Этот подход надежен и неизбежно приводит к нужному результату, не требует каких-то сложных алгоритмов для анализа данных, но очень медлителен и требует серьезных усилий со стороны ученых-экспериментаторов, которым приходится ставить эксперимент за экспериментом, реакцию за реакцией.
Метод раздробления генома начал применяться для чтения коротких фрагментов ДНК еще в 1979 году271, но мало кто верил, что с его помощью можно будет прочитать большой геном. Мы взяли ДНК, раздробили, прочитали разрозненный набор фрагментов, которые называются чтениями. И что дальше? Как мы все это соберем? И можно ли вообще собрать такой “пазл"? Задача по “сборке" генома из чтений легла на специалистов в области вычислительной биологии – биоинформатики, еще одного бурно развивающегося направления современной науки.
Возьмем множество прочитанных фрагментов ДНК. Найдем такую пару последовательностей, которые имеют хорошее перекрытие, объединим их и получим более длинный фрагмент. Последовательно сшивая перекрывающиеся фрагменты, мы будем получать все более длинные последовательности, пока в идеале не получим целые хромосомы. Иллюстрация такого объединения фрагментов приведена ниже.

На практике с таким подходом возникают определенные проблемы, которые приходится решать. Во-первых, каждое чтение получено из случайно взятой молекулы ДНК. Какие-то фрагменты ДНК по воле случая будут прочитаны по десять или даже по сто раз, а какие-то не будут прочитаны вовсе, и в нашем геноме появятся “дырки". Решается эта проблема тем, что мы делаем очень большое “покрытие" генома, чтобы в среднем на каждый участок приходились десятки, а то и сотни чтений. Увы, некоторые участки генома читаются очень плохо, и даже большое покрытие чтениями не всегда помогает. В таких случаях дырки можно попробовать залатать, применив альтернативные методы чтения ДНК.
Еще одна проблема заключается в том, что чтение ДНК происходит не без ошибок. Избежать ошибок при сборке можно, сравнивая большое количество чтений одного и того же места в геноме. Наиболее часто встречающийся вариант, скорее всего, правильный.
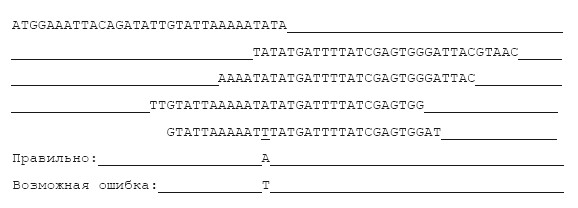
Отличить ошибку чтения от двух разных вариантов (аллелей) гена тоже можно: разные варианты будут присутствовать примерно в равном количестве.
Картину портят повторяющиеся последовательности, которые присутствуют в некоторых геномах. Из-за них мы иногда рискуем сшить два несвязанных фрагмента. Представьте, что у нас есть последовательность ATTGAAAATAAAA на одной хромосоме и последовательность GGCCAAAATAAAA на другой. С какой из них мы склеим последовательность AAAATAAAAGCGT? В такой сложной ситуации желательно иметь какие-то дополнительные данные (например, более длинные прочитанные фрагменты ДНК), но иногда приходится признавать, что мы не знаем, как правильно склеить фрагменты. В итоге в нашей сборке останется “дырка”. Если “дырок” не слишком много, это не помешает большинству последующих анализов с использованием данного генома.
Но в результате оказалось, что Вентер был в значительной степени прав. Если пошевелить мозгами, мы действительно можем собирать геномы (по крайней мере, вполне удовлетворительного качества) даже из множества мелких фрагментов. В 2000 году Celera, объединив усилия с лабораторией генетика Джеральда Рубина, доказала эффективность своего подхода к чтению ДНК, опубликовав в журнале Science статью о прочитанном геноме плодовой мушки дрозофилы Drosophila melanogaster 272.
Пинок со стороны Вентера и его команды в рамках “геномных войн” стимулировал конкурентов, и уже в 2001 году почти одновременно и после долгих торгов были опубликованы сразу два генома человека. Один со стороны международного проекта, а второй со стороны Celera, в журналах Nature и Science соответственно273, 274. “Геномные войны” закончились победой науки, а за ней последовало интересное продолжение.
В 2005 году был опубликован геном нашего ближайшего родственника – шимпанзе275. Тогда подтвердилось, что на молекулярно-генетическом уровне мы с шимпанзе очень похожи. Например, 29 % белков, кодируемых генами шимпанзе и человека, идентичны, то есть не отличаются даже одной аминокислотой, а типичный белок человека отличается от аналогичного белка шимпанзе всего лишь одной или двумя аминокислотами. С другой стороны, оказалось, что существуют как гены, утраченные шимпанзе, так и гены, утраченные людьми в процессе нашей эволюции от общего предка. Но в целом, как уже упоминалось, ДНК человека и ДНК шимпанзе тожественны на 98,76 %88, а если говорить только про те участки, которые кодируют работающие белки, то сходства еще больше. Большинство хромосом человека практически идентичны хромосомам шимпанзе276, но есть одно весьма занимательное отличие.
У шимпанзе (а также у гориллы и орангутанга) 48 хромосом, а у человека – 46277. “Куда же делись еще одна пара хромосом и расположенные на ней гены?” – спросите вы. Поскольку геномы человека и шимпанзе полностью прочитаны, мы можем ответить на этот вопрос очень точно. Для каждого гена шимпанзе мы можем найти похожий (гомологичный) ген человека и посмотреть, на какой хромосоме он расположен. Такой анализ показывает, что по набору генов каждая хромосома шимпанзе соответствует одной хромосоме человека. Исключениями являются хромосомы 12 и 13 шимпанзе, каждая из которых соответствует разным половинам второй хромосомы человека.
У наших давних предков произошло слияние хромосом, и это одно из наиболее наглядных молекулярно-генетических подтверждений идеи Дарвина о наличии общего предка у человека и шимпанзе. Теория эволюции позволяет правильно предсказать не только состав генов на второй хромосоме человека, но и порядок их расположения. Более того, в предполагаемом месте слияния сохранились остатки теломер, участков, которые обычно расположены на концах хромосом. Наконец, на нашей второй хромосоме имеются следы дополнительной центромеры. Центромеры – это особые участки ДНК, с которыми связываются микротрубочки, чтобы растащить хромосомы к разным полюсам клетки перед ее делением. Это обеспечивает одинаковый хромосомный состав дочерних клеток. Обычно у хромосом одна центромера.
Кто-то скажет: но ведь никто не видел эволюцию человека! Значит, мы не можем знать наверняка, был ли у нас с шимпанзе общий предок, а теории эволюционистов – такая же вера, как вера в божественное сотворение человека. Ошибочность подобных рассуждений продемонстрировать очень легко. Представьте, что было совершено убийство. Никто из живущих не видел преступления, но у нас есть отпечатки пальцев преступника на предполагаемом орудии убийства и результаты анализа ДНК, следы ботинок рядом с местом преступления. Все факты указывают на одного-единственного человека, у которого отсутствует алиби. Понятно, что ни в одном суде при наличии столь убедительных объективных доказательств вины аргумент адвоката, что “никто же не видел преступления”, не пройдет. Современные данные по чтению полных геномов живых организмов позволяют реконструировать процесс эволюции не хуже, чем методы криминалистики позволяют реконструировать способ и обстоятельства убийства.
К началу 2015 года было опубликовано более пятисот полных геномов эукариот, тысячи полных геномов бактерий, тысячи полных геномов вирусов. Этот взрывоподобный рост количества генетических данных был связан с появлением методов чтения ДНК нового поколения. Именно благодаря этим методам геном человека (или аналогичный по размерам геном) сейчас можно прочитать всего за несколько тысяч долларов.
Из множества методов чтения ДНК нового поколения мы рассмотрим только одну технологию, которую можно просто и понятно описать. В 2008 году исследователи из компании Pacific Biosciences опубликовали в журнале Science статью под названием “Чтение ДНК в реальном времени с использованием одиночных ДНК-полимераз”278. Этот метод основан на том, что ученые научились “подсматривать” за ДНК-полимеразой прямо в процессе удвоения молекулы ДНК.
Для того чтобы визуализировать активность ДНК-полимеразы, к каждому из четырех типов нуклеотидов приделывается метка определенного цвета. Например, нуклеотид А можно пометить зеленой флуоресцентной меткой, G – желтой и так далее. Ровно одна молекула ДНК-полимеразы помещается в нанофотонную камеру для визуализации. Это цилиндрическая камера шириной около семидесяти нанометров. Пучок света освещает небольшую часть этой камеры, объемом всего в 20 X 10-21 литра, с полимеразой внутри. Нуклеотиды диффундируют в освещенную область камеры и из нее, как правило не задерживаясь надолго внутри, а очень чувствительный прибор фиксирует флуоресценцию в камере. Когда правильный нуклеотид связывается с полимеразой, она хватает его и удерживает, ведь полимеразе нужно время, чтобы присоединить нуклеотид. Благодаря этому правильный нуклеотид проводит больше времени в камере, что приводит к более длительному и сильному световому сигналу, существенно отличающемуся от “шума”. Этот сигнал и фиксирует прибор. После присоединения нуклеотида метка отваливается и уплывает из камеры. В итоге прибор видит последовательные вспышки четырех цветов, соответствующие четырем типам нуклеотидов, и по этим вспышкам восстанавливается последовательность анализируемой молекулы ДНК.
Сегодня приборы для чтения ДНК становятся все лучше и дешевле. Уже начали появляться карманные устройства279, позволяющие читать такие молекулы. Подобные технологии могут помочь полевым лабораториям быстро устанавливать наличие опасных возбудителей заболеваний прямо на месте. Кроме того, они помогают развитию персонализированной медицины – использованию знаний об индивидуальных генетических особенностях человека для прогнозирования и диагностики заболеваний, а также для оптимального выбора лекарственных препаратов.
Помните, как актриса Анджелина Джоли решила сделать мастэктомию, чтобы предотвратить развитие рака молочной железы? От этого заболевания погибли ее мать, бабушка и тетя, поэтому опасения актрисы за собственное здоровье были небезосновательны. Генетический анализ подтвердил худшие ожидания – наличие вредной мутации в гене BRCAi. Некоторые мутации в этом гене могут приводить к очень высокому риску рака груди (вплоть до 80–90 % вероятности в течение жизни) и рака яичников (с вероятностью до 40–50 %). Это не гарантированный приговор, но, взвесив все “за” и “против” (в том числе возможность получить высококачественное протезирование груди), Джоли пошла на столь необычный шаг. В большинстве случаев носителям мутаций, чреватых склонностью к тому или иному виду рака, по результатам генетических тестов рекомендуют проходить регулярные обследования у врача, чтобы успеть обнаружить заболевание на ранних стадиях развития (если оно возникнет).
Если говорить о персонализированном подборе лекарств280, то рассмотрим роль гена, кодирующего цитохром P450 2D6. Этот важный фермент работает прежде всего в печени, где он метаболизирует многие несвойственные нашему телу вещества, в том числе и некоторые лекарства (например, галоперидол и ряд других антипсихотиков). В частности, цитохром P450 превращает кодеин в морфин. У людей встречаются разные варианты цитохрома – более активные и менее активные. Если лекарство метаболизируется в более слабое по воздействию вещество, то на пациента с активным цитохромом препарат будет действовать менее эффективно. Пациенты с менее активным цитохромом в этом случае испытают больше побочных эффектов. Если лекарство метаболизируется в более сильнодействующее вещество, то ситуация будет обратной. Врачу, назначающему лекарство, имеет смысл учесть генетические особенности пациента при подборе препарата и расчете оптимальных дозировок.
Но речь идет не только о медицинских препаратах, а даже и о продуктах повседневного потребления. Существует еще один цитохром CYP1A2, отвечающий за метаболизм кофеина. У некоторых людей этот ген работает плохо или выключен совсем. При употреблении четырех и более чашек кофе в день у таких людей существенно увеличивается риск возникновения сердечно-сосудистых заболеваний, в среднем на 64 %281. У людей с исправной копией гена потребление большого количества кофе почти не влияет на этот риск. Когда ученый Крейг Вентер прочитал свой собственный геном, он узнал, что у него целых две хороших копии этого гена, а значит, свой любимый кофе он может и дальше пить спокойно, в больших количествах, как и раньше.
Похожая история с употреблением алкоголя. Фермент алкогольдегидрогеназа метаболизирует этиловый спирт. Среди людей распространены две версии этого гена: кодирующие “быстрый" и “медленный" вариант фермента. У человека с “быстрым" ферментом этиловый спирт метаболизируется эффективно, поэтому у него менее выражено опьяняющее действие алкоголя, но быстро происходит накопление токсичного продукта метаболизма этанола – ацетальдегида. Накопление ацетальдегида приводит к неприятным ощущениям, ряду признаков похмелья и, кроме того, к характерному покраснению лица вскоре после принятия алкоголя. Как следствие, люди с “быстрым" вариантом фермента алкогольдегидрогеназы получают меньше удовольствия от алкогольных напитков, в среднем пьют меньше282 и реже страдают от алкоголизма283. Еще один фермент, альдегиддегидрогеназа, метаболизирует ацетальдегид до уксусной кислоты, которая легко выводится из организма. Люди с эффективной альдегиддегидрогеназой испытывают меньше негативных последствий от употребления алкоголя. То есть гены определяют безопасные для организма количества алкоголя, а также влияют на вероятность появления алкогольной зависимости.
Генетические данные человека могут использовать не только медицинские работники, но также страховые компании и кадровые агентства. Если вы хотите найти ребенка, из которого можно будет вырастить нового олимпийского чемпиона, проанализируйте гены всех школьников и найдите тех, у кого гены похожи на гены известных спортсменов. Однако на данный момент мы знаем не так много примеров надежных связей между генетическими признаками и способностями людей. Потребуется чтение сотен тысяч геномов, чтобы в этом разобраться. Ситуацию усложняет то обстоятельство, что многие признаки зависят от работы множества генов, а сами гены могут по-разному работать в зависимости от условий. Не будем забывать и о том, что на многие признаки существенно влияют и негенетические факторы.
Бурное развитие геномики – науки, изучающей геномы живых организмов, – привело к появлению еще одного направления современных исследований – метагеномики. Существенный вклад в эту область внес все тот же Крейг Вентер, которого мы упоминаем не в последний раз. В 2004 году Вентер опубликовал статью, в которой было описано чтение “генома” Саргассового моря284! Это вовсе не отсылка к живому океану из фантастического произведения Станислава Лема “Солярис”. Просто исследователи брали пробы морской воды, выделяли из них ДНК, дробили ее и читали все последовательности подряд. В итоге получалась смесь прочитанных фрагментов ДНК из разных геномов, и благодаря такому подходу удалось найти последовательности генов многих ранее не описанных видов.
Вскоре после того, как оказалось, что читать последовательности ДНК из сложных экосистем совсем не трудно, метагеномика обрела колоссальные масштабы. Анализ ДНК позволял находить бактерий, о существовании которых мы раньше даже не подозревали, поскольку их не удавалось культивировать в лабораторных условиях. Был запущен крупномасштабный проект по изучению микрофлоры (микробиома) человека285. Были исследованы метагеномы человеческой кожи, ротовой полости, уретры, половых путей и так далее.
Особое внимание привлекло к себе изучение микрофлоры человеческого кишечника, в котором, как оказалось, живут сотни разных видов бактерий. Ученые даже начали сравнивать бактерий, живущих в кишечниках разных людей286, чтобы оценить их влияние на наш организм. Названия некоторых работ по кишечной метагеномике были прямо-таки завораживающими, например “Сравнительная фекальная метагеномика раскрывает уникальную функциональную емкость кишки свиньи"287. В России подобные исследования иногда в шутку называли “метаговномикой”, и мне даже довелось немного поучаствовать в одном таком проекте. Поскольку копаться в таких метагеномных данных – не самый веселый труд, студентам нашего факультета в качестве учебных заданий по биоинформатике давали неопределенные фрагменты ДНК микробов из кала, и мы пытались понять, что это за последовательности и из каких бактерий они родом.
Шутки шутками, а это на самом деле довольно интересная и важная тема. Российский биолог Илья Мечников первым предположил, что даже здоровый человек существенно зависит от микробов, которые в нем живут. Ученый считал, что качество микрофлоры кишечника имеет непосредственную связь с продолжительностью жизни. В своей статье “Этюды о природе человека” он писал: “Существует распространенная идея, будто микробы нашего кишечника находятся в симбиозе с нашим организмом; однако я полагаю обратное. Я думаю, что мы вскармливаем большое количество вредных микробов, укорачивающих нашу жизнь и вызывающих преждевременную и мучительную старость. […] Я воздерживаюсь от всякой сырой пищи и, сверх того, ввожу в свой обиход молочнокислые микробы, мешающие загниванию в кишках”.
Пищеварительные органы Мечников считал неким неизбежным злом:“Неудивительно, что пищеварительные органы представляют нам столько примеров частей, бесполезных или вредных для внутренней организации. Животные, наши предки, могли употреблять только сырую, грубую пищу как дикорастущие растения или сырое мясо. Человек выучился разводить удобоваримые растения и так приготовлять пищу, чтобы она очень легко всасывалась организмом. Поэтому органы, приспособленные к условиям жизни животного до человека, становятся большею частью лишними для последнего. Многие животные виды, которым удалось добывать легко усвояемую пищу, в конце концов более или менее потеряли свои пищеварительные органы. Таковы паразитические животные; некоторые из них, как, например, солитер, погружены в кишечнике человека в совершенно готовую для их питания жидкость, вследствие чего окончательно утратили собственный кишечный канал.
У человека не совершилось этой эволюции, и он сохранил исключительно вредные ему толстые кишки. Это мешает людям усовершенствовать свою пищу, насколько было бы возможно. Человек не должен питаться слишком легко и безостановочно усваиваемыми веществами, потому что при этом толстые кишки опоражниваются с трудом, что может вызвать серьезную болезнь. Поэтому разумная гигиена должна принимать во внимание устройство нашего кишечного канала и вводить в нашу пищу растительные вещества, дающие достаточное количество остатков".
Рассуждения Мечникова не бесспорны, но заслуживают внимания. В пользу его гипотезы, что микробы кишечника скорее вредны, говорят некоторые исследования на мышах, выращенных в стерильных условиях. Линии таких мышей получают при помощи кесарева сечения, чтобы животные не нахватались микробов во время родов. Их кормят стерильной пищей и держат в стерильных боксах, поэтому бактерий в их кишечнике быть не должно. Такие мыши, как правило, живут не меньше, а иногда даже дольше обычных288, 289. Единственное: у таких стерильных мышей могут возникать проблемы с иммунитетом, когда их помещают в нестерильные условия, и им нужно тщательнее подбирать диету.
В 2013 году в журнале Science было опубликовано еще одно интересное исследование290 – о роли микрофлоры кишечника в ожирении. Исследователи брали однояйцовых (генетически идентичных) близнецов, один из которых страдал ожирением, а другой – нет. Мыши, которым пересаживали кишечную микрофлору от людей с ожирением, начинали набирать лишний вес, но пересадка кишечной микрофлоры от худых людей такого действия не оказывала. Сравнивая метагеномы мышей, которые набирали вес, и метагеномы мышей, которые его не набирали, можно понять, какие именно микробы способствуют ожирению, чтобы потом разрабатывать препараты для похудения. Это могут быть пробиотики – препараты, привносящие “хороших" микробов, замещающих собой плохих, или антибиотики, направленные против конкретных вредных микробов. Сам Мечников писал о пользе кисломолочных продуктов, содержащих лактобактерии. Он считал, что молочная кислота, выделяемая лактобактериями, создает кислую среду в кишечнике и подавляет развитие вредных бактерий. Впрочем, далеко не про всех бактерий на данный момент до конца ясно, вредны они или нет, а идея о пользе кефира может оказаться преувеличенной. С другой стороны, известно, что лактобактерии полезны, когда живут (и создают кислую среду) во влагалище, защищая его от урогенитальных инфекций291.
Но даже если среди существующих микроорганизмов, способных жить в нашем кишечнике, мы не найдем достаточно полезных, мы всегда можем их создать! В 2014 году были опубликованы результаты исследований на мышах, которых кормили генетически модифицированной кишечной палочкой, производящей N-ацилфосфатидилэтаноламины. Вещества эти являются предшественниками N-ацетилэтаноламидов, которые производятся в тонкой кишке после приема пищи и сигнализируют организму о насыщении. Мыши, употреблявшие генетически модифицированных бактерий вместе с питьевой водой, воздерживались от чрезмерного потребления пищи и, как следствие, меньше страдали от ожирения и иных негативных последствий переедания13. Так ГМ бактерии могут помочь в борьбе с лишним весом!
Исследовательский подход с использованием метагеномного анализа применим к изучению не только ожирения, но и многих других процессов, связанных с микробами. Например, в нашей исследовательской группе посредством метагеномного анализа292 мы изучаем отличия в составе микрофлоры поверхности здорового человеческого глаза и глаза с бактериальным кератитом, чтобы помочь врачам с выбором антибиотиков. Появляются работы, указывающие на то, что некоторые микробы, живущие в кишечнике, способны оказывать воздействие на нервную систему293, влиять на наше настроение, самочувствие, например вызывать депрессию или тревогу294, и сказываться на нашем поведении295. Это навело меня и некоторых моих коллег на мысль, что микробы могут склонять людей и к выполнению некоторых более сложных действий. Вдаваться в детали этой гипотезы я не буду, но предлагаю желающим найти и прочитать статью “Могут ли микробы вызывать пристрастие к религиозным ритуалам? Мидихлорианы: гипотеза биомемов”296.
Кроме того, выдвигаются гипотезы о связи некоторых нейродегенеративных заболеваний, таких как болезнь Альцгеймера, с распространением патогенных микроорганизмов, производящих нейротоксины в кишечнике297, 298. Воздействовать на наш мозг микробы способны либо напрямую, выделяя химические вещества, проходящие через гематоэнцефалический барьер (физиологический барьер между кровеносной и центральной нервной системой), либо опосредованно, воздействуя на нервные клетки, расположенные в самом кишечнике. Соответственно, изменив микрофлору кишечника, мы можем устранить причину некоторых заболеваний. В этом ключе соблазнительна идея использования генной инженерии для создания новых симбиотических бактерий, оптимально приспособленных для мирного сосуществования с людьми.
Метагеномика имеет интересные сферы применения на стыке науки и теологии. Предлагаю такой проект: “Теология и метагеном древних еврейских экскрементов". Дело в том, что в иудаизме есть термин “кашрут”, означающий дозволенность или пригодность чего-либо с точки зрения иудейского права. В частности, пища бывает кошерная, которую разрешено есть, и некошерная, которую есть нельзя. Но существует одна проблема: отдельные названия библейских животных, вероятно, изменили значение, и никто точно не знает, что означали некоторые древние слова. Например, “анака”, “летаа”, “хомет”, “тиншемет”, “харгол”, “хагав”, “солам”, означающие что-то кошерное. Насчет одних имеются определенные догадки, насчет других есть сомнения, но если бы нам удалось точно узнать, какие животные считались кошерными пару тысяч лет назад, мы бы обогатили рацион современных евреев. Пусть это и будут ящерицы, саранча или что-то в этом духе.
Второзаконие (23:12–13) предписывало древним евреям закапывать свои фекалии. “У вас должно быть место вне стана, куда вы могли бы выходить по нужде. Каждый должен иметь при себе лопатку, чтобы, присев там, вырыть ямку, а потом закопать нечистоты". Следовательно, нужно найти подобные древние захоронения, выкопать их и провести анализ ДНК. Разумеется, такое исследование рискует столкнуться с рядом проблем. Сохранится ли ДНК? Как понять, что найденный нужник – еврейский? Как распознать загрязнения образцов чужеродной ДНК? Тут есть о чем подумать! Отдельный интересный вопрос: отличается ли метагеном людей, употребляющих исключительно кошерную пищу?
Если говорить об уже проведенных исследованиях на стыке науки геномики и теологии, упоминания заслуживает история про Кумранские рукописи. Кумран – местность примерно в двух километрах от побережья Мертвого моря. В период с 1946 по 1956 год в Кумранских пещерах было найдено несколько сотен текстов, датированных последними веками до нашей эры – первыми веками нашей эры, представляющих исторический, религиозный и лингвистический интерес. В частности, среди них имеются тексты, соответствующие древним библейским канонам. Некоторые записи были сделаны на шкурах животных, и при помощи анализа ДНК удалось выяснить, какие фрагменты принадлежат одной рукописи. Кроме того, анализ ДНК позволил установить виды животных, чьи шкуры были использованы. В древности шкуры имели разную цену и значимость, что позволяет определить, какие из текстов считались самыми важными.
Но все-таки основная задача геномики – установить последовательности генов и разобраться в том, как они работают, чтобы мы потом могли успешно заниматься генной инженерией, исправлять генетические дефекты человека и создавать новые организмы. Для того чтобы понять, как повлияет на организм то или иное изменение его генома, полезно иметь представление о разнообразии генов уже существующих живых организмов, и именно это становится возможным благодаря современным методам чтения ДНК.
Открытие генов светочувствительных ионных каналов из водорослей позволило создать нервные клетки, реагирующие на освещение, открытие ДНК-полимеразы из термофильных бактерий сделало возможным полимеразную цепную реакцию – один из важнейших методов молекулярной биологии. Кто знает, какие еще удивительные гены мы обнаружим в природе и как они изменят наш арсенал биотехнологий?
Глава 13
Дата добавления: 2015-12-10; просмотров: 1275;