Паспорт Украины: Иванов Иван Иванович, серия 1234 номер 123456.
Унифицированные идентификаторы ресурсов
В Web для идентификации элементов используются «Унифицированные идентификаторы ресурсов», или сокращенно URI (Uniform Resource Identifier). На английский манер произносится как [ю-ар-а́й], по-русски чаще говорят [у́ри]. URI — это последовательность символов, идентифицирующая абстрактный или физический ресурс. Ранее назывался Universal Resource Identifier — универсальный идентификатор ресурса.
URI используются для именования объектов. Каждый объект глобальной семантической сети имеет уникальный URI. URI однозначно называет некоторый объект. Отдельные URI создают не только для страниц, но и для объектов реального мира (людей, городов, художественных произведений и так далее), и даже для абстрактных понятий (например, «имя», «должность», «цвет»). URI можно присвоить чему угодно, и если эта сущность имеет URI, то о ней можно говорить, что она находится «в Web». Благодаря уникальности URI одни и те же предметы можно называть одинаково в разных местах семантической паутины. Используя URI, можно собирать информацию о одном предмете из разных мест.
Стандартизацию URI определяет документ, доступный по следующей ссылке: http://www.ietf.org/rfc/rfc3305. Отметим, что данная ссылка также является URI. В соответствии с данным документом, в современном интернете используется две разновидности URI – URL и URN. Основное различие между ними состоит в их задачах:
URL – Uniform Resource Locator, помогает найти какой-либо ресурс.
URN – Uniform Resource Name, помогает этот ресурс идентифицировать.
Таким образом, URL и URI – частные случаи URI.
Синтаксис URI
Синтаксис, используемый при стандартизации URI, определяется так называемым документом RFC3986, доступным по ссылке http://www.ietf.org/rfc/rfc3986. Согласно пункту 2 данного документа, URI строится из ограниченного набора символов, состоящих из цифр, букв и нескольких графических символов. Все эти символы вписываются в кодировку US-ASCII (ASCII). Зарезервированное подмножество символов может использоваться для разграничения компонентов URI, в то время как оставшиеся символы (незарезервированный набор и те зарезервированные символы, которые не действуют как разделители в данном компоненте URI) используются для идентификации каждого компонента.
Зарезервированные символы. Зарезервированные символы делятся на два типа:
1) главные разделители (gen-delims) – символы, разделяющие URI на крупные компоненты:
| : | / | ? | # | [ | ] | @ |
2) подразделители (sub-delims) – символы, которые разделяют текущую крупную компоненту, на более мелкие составляющие. Для каждой компоненты URI используются свои подразделители. К наиболее распространенным относятся:
| ! | $ | & | ' | ( | ) | * | + | , | ; | = |
Незарезервированные символы. К ним относятся символы, не входящие в группу gen-delims, а также символы из группы sub-delims, незначимые для данной компоненты URI. В общем случае это следующие символы:
| ALPHA | DIGIT | – | . | _ | ~ |
Здесь ALPHA – любая латинская буква в верхнем или нижнем регистре кодировки ASCII, DIGIT – любая цифра арабская.
Процентное кодирование. В случае, если используются символы выходящие за пределы кодировки ASCII, используется механизм т.н. «процентного кодирования». Он также применяется для передачи зарезервированных символов в составе данных. Зарезервированные символы, по правилам, не участвуют в процентном кодировании.
Процентно-кодированный (pct-encoded) символ представляет из себя символьный триплет, состоящий из знака "%" и следующих за ним двух шестнадцатиричных чисел:
pct-encoded = "%" HEXDIG HEXDIG
Здесь HEXDIG – любая цифра шестнадцатеричной системы счисления (0-9, A-F). Например, pct-encoded символ %20 эквивалентен шестнадцатеричному числу 2016=3210. Как известно, в большинстве символьных кодировок коду 3210 соответствует символ пробела.
Компоненты URI
URI строится по определенным правилам и графически может быть представлен в виде следующей схемы:
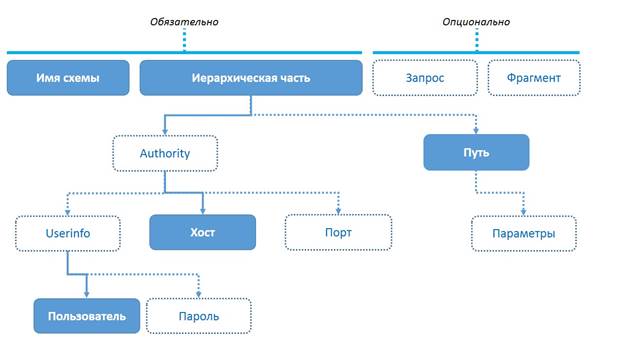
URI состоит из обязательных и необязательных элементов. Обязательными элементами являются схема и иерархическая часть, необязательными – запрос (ему предшествует знак "?") и фрагмент (ему предшествует знак "#"). Рассмотрим данные элементы.
1. Scheme (схема).
Каждый URI начинается с имени схемы, которое определяет правила описания последующих элементов URI. Поскольку синтаксис URI –расширяемая система именования, спецификация каждой схемы может ограничить синтаксис и семантику идентификаторов, использующих эту схему.
Название схемы обязательно начинается с буквы и далее может быть продолжено любым количеством разрешенных символов. Разрешенные символы для схемы:
| ALPHA | DIGIT | + | – | . |
Примерами схемы являются: http, ftp, file, ldap, mailto, urn.
2. Иерархическая часть.
Включает данные авторизации (Authority) и путь (path).
Authority (данные авторизации).
Компонента authority начинается с двойного прямого слеша (//) и может заканчиваться одинарным прямым слешем (/), знаком вопроса (?), решеткой (#), либо ничем (в этом случае URI заканчивается).
Структура поля Authority имеет следующия вид:
[userinfo "@"] host [":" port]
Здесь в квадратных скобках указаны опциональные (необязательные) компоненты, которые будут детально рассмотрены позже.
Путь (Path). Компонента пути содержит данные, обычно организованные в иерархической форме, которые, вместе с данными в неиерархическом компоненте запроса (Query), служат для идентификации ресурса в рамках схемы URI и authority (если таковая компонента указана).
Путь начинается с прямого слеша (/) и заканчивается знаком вопроса (?), решеткой (#) или концом URI. Разрешенные символы для пути:
| незарезервированные | процентно-кодированные | sub-delims | : | @ |
3. Запрос (Query).
Компонента запроса содержит иерархически организованные данные, организованные в неиерархической форме, которые, совместно компонентой «Path», служат для идентификации ресурса в рамках элементов «схема» и «Authority» (если таковой указан).
Запрос начинается с первого знака вопроса (?) и заканчивается решеткой (#) или концом URI.
Разрешенные символы для запроса:
| незарезервированные | процентно-кодированные | sub-delims | : | @ | / | ? |
В запросе чаще всего передаются данные в формате key=value (ключ=значение). При этом значение рекомендуется передавать в процентно-кодированном виде. Это обусловлено тем, что в значении может встретиться символ "&", который используется для разделения пар «ключ=значение», в результате чего дальнейшая последовательность пар «ключ=значение» может быть нарушена.
4. Фрагмент (Fragment).
Данная компонента позволяет осуществить косвенную идентификацию вторичного ресурса по отношению к первому.
Семантика фрагмента никак не ограничена. Фрагмент начинается решеткой (#), заканчивается концом URI и может состоять из абсолютно любого набора символов.
В качестве примера применения фрагментов рассмотрим оглавление некоторой статьи. Оно состоит из относительных ссылок
<a href="#someanchor"></a>,
а по статье, в определенных местах, раскиданы т.н. «якоря» – теги
<anchor>someanchor</anchor>.
Переходя по указанной в оглавлении ссылке, браузер производит переход ко вторичному ресурсу относительно данной страницы, т.е. скроллит вниз, до появления нужного <anchor> на экране.
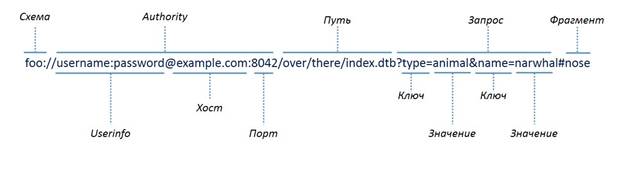
Следующий рисунок иллюстрирует рассмотренную структуру URI:
Uniform Resource Locator (URL)
URL (Uniform Resource Locator) указывает путь (локацию) объекта и метод получения доступа к нему. Например,
http://en.wikipedia.org/wiki/Main_Page
указывает на главную страницу английской Википедии и в качестве метода доступа предлагает использовать протокол http.
Стандарт URL изложен в документе RFC 1738, доступном по ссылке http://www.ietf.org/rfc/rfc1738. В этом документе указаны описаны различные схемы для протоколов ftp, http, nntp и т.д. Послкольку URL – это частный случай URI, его схема в общем случае выглядит так же, однако для разных протоколов актуальны те или иные ее части. Например, для протокола telnet, схема URL выглядит следующим образом:
telnet://<user>:<password>@<host>:<port>/
Uniform Resource Name (URN)
Унифицированные имена ресурсов (URN) предназначены, чтобы служить постоянными, независимыми от расположения, идентификаторами ресурсов и разработаны для упрощения отображения других пространств имен (которые совместно используют свойства URN) в URN-пространство. Таким образом, синтаксис URN позволяет закодировать символьные данные в форме, которая может быть отправлена посредством существующих протоколов, записана при помощи большинства клавиатур, и т.д. В отличие от URL, который ссылается на какое-то место, где хранится документ, URN ссылается на сам документ, и при перемещении документа в другое место ссылка не изменится.
URN определяется стандартом RFC 1737, доступным по ссылке http://www.ietf.org/rfc/rfc1737, и включает в себя идентификатор (название) пространства имен и имя в этом пространстве. URN состоит из NID (Namespace Identifier, идентификатор пространства имен) и NSS (Namespace-Specific String – имя, уникальное для данного пространства имен). Типичный пример URN – это имя книги в стандарте ISDN. Схематично это выглядит следующим образом:
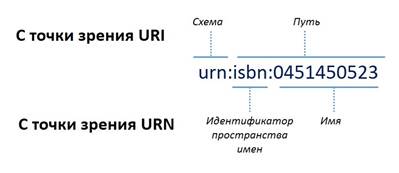
Таким образом, формально структура URN имеет следующий вид:
"urn:" <NID> ":" <NSS>
«urn:» – схема (обязательная, регистронезависимая часть, с которой начинаются все URN).
NID – Namespace Identifier, идентификатор пространства имен. Данная компонента определяет синтаксическую интерпретацию компоненты NSS. Минимальная длина – 2 символа, максимальная – 32, разрешенные символы: латинские буквы, цифры, символ "-". NID должен начинаться только с буквы или цифры. Отметим, что слово «urn» для NID является зарезервированным, дабы избежать неоднозначности при определении URN в целом.
NSS – Namespace Specific String. Данная компонента служит непосредственно для передачи каких-либо данных.
Типичным примером URN является описание книги в формате ISBN. Схематично это выглядит следующим образом:
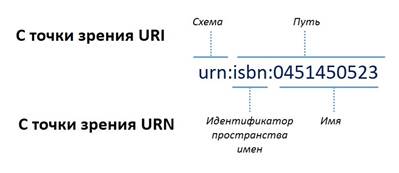
URN могут использоваться для описания различных объектов. Рассмотрим пример описания некоторого человека. URN в данном случае будет выглядеть следующим образом:
паспорт Украины: Иванов Иван Иванович, серия 1234 номер 123456.
Здесь «паспорт Украины» – название идентификатора пространства имен, а «Иванов Иван Иванович, серия 1234 номер 123456» – это уникальное имя в этом пространстве.
С помощью данного URN мы однозначно идентифицируем человека, но не сможем определить его местоположение. Здесь нам поможет URL. Выглядеть это может примерно так:
Дата добавления: 2015-12-08; просмотров: 1475;