Вывод значений переменных окружения.
print "Content-Type: text/html\n\n
<HTML><HEAD><TITLE></title></head><BODY>\n
<p>Переменные окружения:<p>\n";
foreach (keys %ENV) {print "$_: $ENV{$_}<br>\n" }
print "</body></html>";
Все эти переменные могут быть использованы и даже изменены вашей CGI-программой. Однако эти изменения не затрагивают веб-сервер, запустивший программу.
Передача параметров серверу.
Командная строка.CGI допускает передачу CGI-программе аргументов в качестве параметров командной строки, которая редко используется. Редко используется она потому, что практические применения ее немногочисленны, и мы не будем останавливаться на ней подробно. Суть в том, что если переменная окружения QUERY_STRING не содержит символа « = », то CGI-программа будет выполняться с параметрами командной строки, взятыми из OUERY_STRING . Например, http://www.myseruer.com/cgi-bin/finger?root запустит finger root на www.myserver.com.
Параметры командной строки чаще всего используются вместе с тегом HTML <ISINDEX> . Тег <ISINDEX> обозначает миниформу, содержащуюся в одном теге. Обнаружив тег <ISINDEX> , броузер выводит окно, в которое пользователь может ввести текст запроса. При подаче запроса (нажатии пользователем клавиши «Enter»), броузер извлекает URL из тега <ISINDEX> и обращается к нему, передавая текст запроса в качестве командной строки.
Предшествующий finger можно написать так, что при вызове без аргументов он выведет HTML-страницу с тегом <ISINDEX> . После ввода пользователем адреса finger исполнится так же, как описано.
Стандартное устройство ввода.Как сказано выше, если клиент использует для передачи информации HTTP-методы PUT или POST, длина и тип MIME этих данных помещаются в переменные CONTENT_LENGTH и CONTENT_TYPE соответственно. Передаваемые данные посылаются на стандартное устройство ввода CGI-программы. Признак конца данных может не посылаться программе, поэтому она должна взять значение переменной CONTENT_LENGTH и прочесть столько байтов, сколько в ней указано. Это основной метод передачи данных из форм, и в наших примерах мы будем почти исключительно использовать только его.
Существуют многочисленные библиотеки почти для всех языков, которые выполняют важные задачи настройки CGI-программ, в том числе определяют, каким методом - GET или POST — переданы данные, и, соответственно, разбирают переменную окружения QUERY_STRING или читают с устройства стандартного ввода. Затем эти библиотеки помещают данные в легко доступные переменные. Обширный список ресурсов CGI для разных языков есть на Yahoo по адресу: http://www.yahoo.com/Computers_and_Internet/Internet/ World_Wide_Web/CGI_Common_Gateway_Interface/
Стандартное устройство вывода.Данные, посылаемые CGI-программой на стандартное устройство вывода, читаются веб-сервером и отправляются клиенту. Если имя сценария начинается с nph-, то данные посылаются прямо клиенту без вмешательства со стороны веб-сервера. В этом случае CGI-программа должна сформировать правильный заголовок HTTP, который будет понятен клиенту. В противном случае предоставьте веб-серверу сформировать HTTP-заголовок.
Даже если вы не используете nph-сценарий, серверу нужно дать одну директиву, которая сообщит ему сведения о вашей выдаче. Обычно это HTTP-заголовок Content-Type , но может быть и заголовок Location . За заголовком должна следовать пустая строка, то есть перевод строки или комбинация CR/LF.
Заголовок Content-Type сообщает серверу, какого типа данные выдает ваша CGI-программа. Если это страница HTML, то строка должна быть Content-Type: text/html. Заголовок Location сообщает серверу другой URL или другой путь на том же сервере, куда нужно направить клиента. Заголовок должен иметь следующий вид: Location: http:// www.myserver.com/another/place/.
После заголовков HTTP и пустой строки можно посылать собственно данные, выдаваемые вашей программой - страницу HTML, изображение, текст или что-либо еще. Среди CGI-программ, поставляемых с сервером Apache, есть nph-test-cgi и test-cgi, которые хорошо демонстрируют разницу между заголовками в стилях nph и не-nph, соответственно.
Важные особенности сценариев CGI.Вы уже знаете, в основном, как работает CGI. Клиент посылает данные, обычно с помощью формы, веб-серверу. Сервер выполняет CGI-программу, передавая ей данные. CGI-программа осуществляет свою обработку и возвращает свои выходные данные серверу, который передает их клиенту. Теперь от понимания того, как работают CGI-программа, нужно перейти к пониманию того, почему они так широко используются.
Нужно разобрать еще несколько важных вопросов, прежде чем создавать реально работающие программы. Во-первых, нужно научиться работать с несколькими формами. Затем нужно освоить некоторые меры безопасности, которые помешают злоумышленникам получить незаконный доступ к файлам вашего сервера или уничтожить их.
Запоминание состояния
Запоминание состояния является жизненно важным средством предоставления хорошего обслуживания вашим пользователям, а не только служит для борьбы с закоренелыми преступниками. Проблема вызвана тем, что HTTP является так называемым протоколом «без памяти». Это значит, что клиент посылает данные серверу, сервер возвращает данные клиенту, и дальше каждый идет своей дорогой. Сервер не сохраняет о клиенте данных, которые могут понадобиться в последующих операциях. Аналогично, нет уверенности, что клиент сохранит о совершенной операции какие-либо данные, которые можно будет использовать позднее. Это накладывает существенное ограничение на использование World Wide Web.
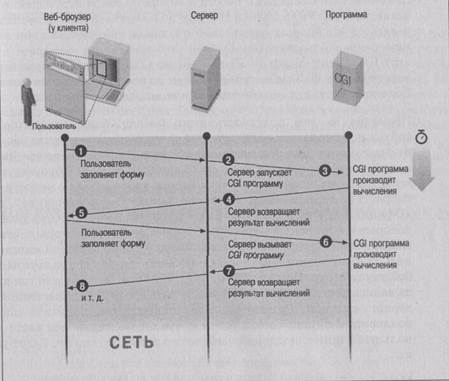
Рис. 2-1. Множественные запросы форм
Составление сценариев CGI при таком протоколе аналогично неспособности запоминать разговор. Всякий раз, разговаривая с кем-либо, независимо от того, как часто вы общались с ним раньше, вам приходится представляться и искать общую тему для разговора. Рисунок 3-1 показывает, что всякий раз, когда запрос достигает программы CGI, это совершенно новый экземпляр программы, не имеющий связи с предыдущим.
В части клиента с появлением Netscape Navigator появилось выглядящее наспех сделанным решение под названием cookies. Оно состоит в создании нового HTTP-заголовка, который можно пересылать туда-сюда между клиентом и сервером, похожего на заголовки Content-Type и Location. Броузер клиента, получив заголовок cookie, должен сохранить в cookie данные, а также имя домена, в котором действует этот соokie. После этого всякий раз при посещении URL в пределах указанного домена заголовок cookie должен возвращаться серверу для использования в CGI-программах на этом сервере.
Метод cookie используется в основном для хранения идентификатора пользователя. Сведения о посетителе можно сохранить в файле на сервере. Уникальный ID этого пользователя можно послать в качестве cookie броузеру пользователя, после чего при каждом посещении сайта пользователем броузер автоматически посылает серверу этот ID. Сервер передает ID программе CGI, которая открывает соответствующий файл и получает доступ ко всем данным о пользователе. Все это происходит незаметно для пользователя.
Несмотря на всю полезность этого метода, большинство больших сайтов не использует его в качестве единственного средства запоминания состояния. Для этого есть ряд причин. Во-первых, не все броузеры поддерживают cookie. До недавнего времени основной броузер для людей с недостаточным зрением (не говоря уже о людях с недостаточной скоростью подключения к сети) - Lynx - не поддерживал cookie. «Официально» он до сих пор их не поддерживает, хотя это делают некоторые его широко доступные «боковые ветви». Во-вторых, что более важно, cookie привязывают пользователя к определенной машине. Одним из великих достоинств Web является то, что она доступна из любой точки света. Независимо от того, где была создана или где хранится ваша веб-страница, ее можно показать с любой подключенной к Интернет машины. Однако если вы попытаетесь получить доступ к поддерживающему cookie сайту с чужой машины, все ваши персональные данные, поддерживавшиеся с помощью cookie, будут утрачены.
Многие сайты по-прежнему используют cookie для персонализации страниц пользователей, но большинство дополняет их традиционным интерфейсом в стиле «имя регистрации/пароль». Если доступ к сайту осуществляется из броузера, не поддерживающего cookie, то страница содержит форму, в которую пользователь вводит имя регистрации и пароль, присвоенные ему при первом посещении сайта. Обычно эта форма маленькая и скромная, чтобы не отпугивать большинство пользователей, не заинтересованных ни в какой персонализации, а просто желающих пройти дальше. После ввода пользователем в форму имени регистрации и пароля CGI находит файл с данными об этом пользователе, как если бы имя посылалось с cookie. Используя этот метод, пользователь может регистрироваться на персонализированном веб-сайте из любой точки света.
Помимо задач учета предпочтений пользователя и длительного хранения сведений о нем можно привести более тонкий пример запоминания состояния, который дают популярные поисковые машины. Осуществляя поиск с помощью таких служб, как AltaVista или Yahoo, вы обычно получаете значительно больше результатов, чем можно отобразить в удобном для чтения виде. Эта проблема решается тем, что показывается небольшое количество результатов - обычно 10 или 20 — и дается какое-либо средство перемещения для просмотра следующей группы результатов. Хотя обычному путешественнику по Web такое поведение кажется обычным и ожидаемым, действительная его реализация нетривиальна и требует запоминания состояния. Когда пользователь впервые делает запрос поисковому механизму, тот собирает все результаты, возможно, ограничиваясь некоторым предустановленным предельным количеством. Фокус состоит в том, чтобы выдавать эти результаты одновременно в небольшом количестве, запомнив при этом, что за пользователь запрашивал эти результаты и какую порцию он ожидает следующей. Оставляя в стороне сложности самого поискового механизма, мы встаем перед проблемой последовательного предоставления пользователю некоторой информации по одной странице.
Однако если вам требуется нечто большее, чем возможность просто листать файл, то полагаться на URL бывает обременительно. Облегчить эту трудность можно через использование формы HTML и включение данных о состоянии в теги <INPUT> типа HIDDEN . Этот метод с успехом используется на многих сайтах, позволяя делать ссылки между взаимосвязанными CGI-программами или расширяя возможности использования одной CGI-программы. Вместо ссылки на определенный объект, такой как начальная страница, данные URL могут указывать на автоматически генерируемый ID пользователя.
Так работают AltaVista и другие поисковые машины. При первом поиске генерируется ID пользователя, который скрыто включается в последующие URL. С этим ID связаны один или несколько файлов, содержащих результаты запроса. В URL включаются еще две величины: текущее положение в файле результатов и направление, в котором вы хотите перемещаться в нем дальше. Эти три значения - все, что нужно для работы мощных систем навигации больших поисковых машин.
Меры безопасности
При работе серверов Интернет, будь они серверами HTTP или другого рода, соблюдение мер безопасности является важнейшей заботой. Обмен данными между клиентом и сервером, совершаемый в рамках CGI, выдвигает ряд важных проблем, связанных с защитой данных. Сам протокол CGI достаточно защищен. CGI-программа получает данные от сервера через стандартное устройство ввода или переменные окружения, и оба эти метода являются безопасными. Но как только CGI-программа получает управление данными, ее действия ничем не ограничены. Плохо написанная CGI-программа может позволить злоумышленнику получить доступ к системе сервера. Рассмотрим следующий пример CGI-программы:
Дата добавления: 2015-11-04; просмотров: 1548;