Представление текстовых данных.
Любой текст состоит из последовательности символов. Символами могут быть буквы, цифры, знаки препинания, знаки математических действий, круглые и квадратные скобки и т.д. Особо обратим внимание на символ "пробел", который используется для разделения слов и предложений между собой. Хотя на бумаге или экране дисплея "пробел" - это пустое, свободное место, этот символ ничем не "хуже" любого другого символа. На клавиатуре компьютера или пишущей машинки символу "пробел" соответствует специальная клавиша.
Текстовая информация, как и любая другая, хранится в памяти компьютера в двоичном виде. Для этого каждому символу ставится в соответствие некоторое неотрицательное число, называемое кодом символа, и это число записывается в память ЭВМ в двоичном виде. Конкретное соответствие между символами и их кодами называется системой кодировки.
В современных ЭВМ, в зависимости от типа операционной системы и конкретных прикладных программ, используются 8-разрядные и 16-разрядные (Windows 95, 98, NT) коды символов. Использование 8-разрядных кодов позволяет закодировать 256 различных знаков, этого вполне достаточно для представления многих символов, используемых на практике. При такой кодировке для кода символа достаточно выделить в памяти один байт. Так и делают: каждый символ представляют своим кодом, который записывают в один байт памяти. При двоичном кодировании текстовой информации каждому символу сопоставляется его код - последовательность из фиксированного количества нулей и единиц. В большинстве современных компьютеров для хранения двоичного кода одного символа выделена последовательность из 8 нулей и единиц, называемая "байтом" (byte). Учитывая, что каждый бит принимает значение 0 или 1, количество их возможных сочетаний в байте равно 28 = 256. Значит, с помощью 1 байта можно получить 256 разных двоичных комбинаций и отобразить с их помощью 256 различных символов, например, большие и малые буквы русского и латинского алфавитов, цифры, знаки препинания и т. д.
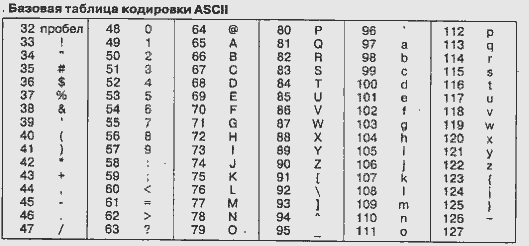
В персональных компьютерах обычно используется система кодировки ASCII (American Standard Code for Information Interchange - американский стандартный код для обмена информации). Он введен в 1963 г. и ставит в соответствие каждому символу семиразрядный двоичный код. Легко определить, что в коде ASCII можно представить 128 символов.
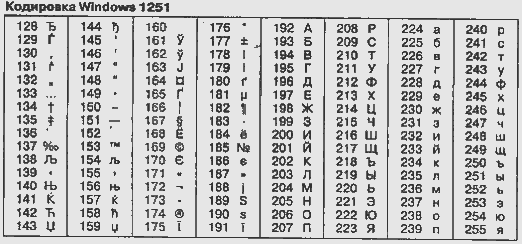
В системе ASCII закреплены две таблицы кодирования базовая и расширенная. Базовая таблица закрепляет значения кодов от 0 до 127, а расширенная относится к символам с номерами от 128 до 255.
Первые 32 кода базовой таблицы, начиная с нулевого, отданы производителям аппаратных средств. В этой области размещаются управляющие коды, которым не соответствуют ни какие символы языков. Начиная с 32 по 127 код размещены коды символов английского алфавита, знаков препинания, арифметических действий и некоторых вспомогательных символов.
Кодировка символов русского языка, известная как кодировка Windows-1251, была введена "извне" - компанией Microsoft, но, учитывая широкое распространение операционных систем и других продуктов этой компании в России, она глубоко закрепилась и нашла широкое распространение.
Другая распространённая кодировка носит название КОИ-8 (код обмена информацией, восьмизначный) - её происхождение относится к временам действия Совета Экономической Взаимопомощи государств Восточной Европы. Сегодня кодировка КОИ - 8 имеет широкое распространение в компьютерных сетях на территории России и в российском секторе Интернета.
Международный стандарт, в котором предусмотрена кодировка символов русского языка, носит название ISO (International Standard Organization - Международный институт стандартизации). На практике данная кодировка используется редко.
Универсальная система кодирования текстовых данных.
Если проанализировать организационные трудности, связанные с созданием единой системы кодирования текстовых данных, то можно прийти к выводу, что они вызваны ограниченным набором кодов (256). В то же время, очевидно, что если, кодировать символы не восьмиразрядными двоичными числами, а числами с большим разрядом то и диапазон возможных значений кодов станет на много больше. Такая система, основанная на 16-разрядном кодировании символов, получила название универсальной - UNICODE. Шестнадцать разрядов позволяют обеспечить уникальные коды для 65 536 различных символов - этого поля вполне достаточно для размещения в одной таблице символов большинства языков планеты.
Несмотря на тривиальную очевидность такого подхода, простой механический переход на данную систему долгое время сдерживался из-за недостатков ресурсов средств вычислительной техники (в системе кодирования UNICODE все текстовые документы становятся автоматически вдвое длиннее). Во второй половине 90-х годов технические средства достигли необходимого уровня обеспечения ресурсами, и сегодня мы наблюдаем постепенный перевод документов и программных средств на универсальную систему кодирования.
Ниже приведены таблицы кодировки ASCII.
Дата добавления: 2015-10-09; просмотров: 1054;