Расстояние Хеминга и корректирующие возможности кодов
Определение. Код обнаруживает  ошибок, если
ошибок, если  ошибок в кодовом слове переводит его в слово, которое не входит в код.
ошибок в кодовом слове переводит его в слово, которое не входит в код.
Код "Тетраэдр" из предыдущего примера обнаруживает одну ошибку (меняется четность), но не обнаруживает две ошибки. Например, слово 101 в результате двух ошибок в первых двух знаках переходит в другое кодовое слово (реализуется третий вариант передачи на рис.7.7). Легко заметить, что данный код обнаруживает 3 ошибки, 5 ошибок и вообще любое нечетное число ошибок, но не обнаруживает любое четное число ошибок. Поэтому, в соответствии с приведенным определением, этот код не обнаруживает 3 или 5 ошибок, а только одну.
В пространстве 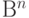 вводится мера отличия двух точек этого пространства, которая называется расстоянием Хеминга [29], [33],[34].
вводится мера отличия двух точек этого пространства, которая называется расстоянием Хеминга [29], [33],[34].
Определение. Расстоянием 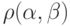 , по Хемингу, между вершинами
, по Хемингу, между вершинами 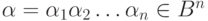 и
и 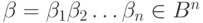 называется число разрядов, в которых эти вершины различаются.
называется число разрядов, в которых эти вершины различаются.
В виде математической формулы это можно записывать так:
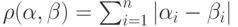
где через  обозначается абсолютная величина числа
обозначается абсолютная величина числа 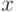 .
.
В качестве примера рассмотрим расстояние Хеминга между двумя точками (последовательностями или словами)  и
и 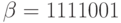 пространства
пространства 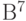 . Эти последовательности отличаются в первой, четвертой и пятой позициях, следовательно,
. Эти последовательности отличаются в первой, четвертой и пятой позициях, следовательно, 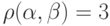 .
.
Вещественную функцию 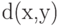 двух переменных на множестве
двух переменных на множестве 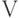 принято называть расстоянием, если она обладает следующими свойствами:
принято называть расстоянием, если она обладает следующими свойствами:
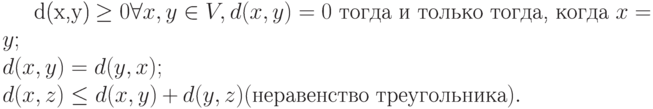
Расстояние Хеминга обладает перечисленными выше свойствами. Два первых свойства очевидным образом следуют из определения расстояния Хеминга (или из приведенной выше формулы для расстояния Хеминга), а третье свойство вытекает из следующей последовательности равенств и неравенств
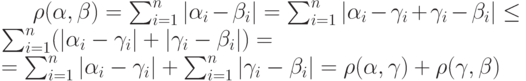
Возможности обнаруживать и исправлять ошибки с помощью кода C зависят от его характеристики, которая называется кодовым расстоянием [34].
Определение. Кодовым расстоянием  кода
кода  называется минимальное расстояние между различными кодовыми словами (векторами).
называется минимальное расстояние между различными кодовыми словами (векторами).
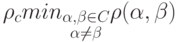
С использованием расстояния Хеминга в пространстве можно определить аналоги таких геометрических понятий, как сфера и шар [34]. Эти понятия потребуются в дальнейшем для объяснения принципов обнаружения и исправления ошибок с помощью кодов.
Сферой радиуса с центром в точке 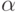 является множество
является множество
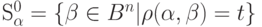
Число точек  в сфере
в сфере 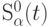 определяется выражением
определяется выражением
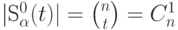
Шаром радиуса с центром в точке называется множество
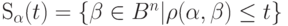
Число точек 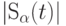 в шаре
в шаре 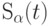 определяется выражением
определяется выражением
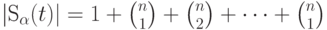
Замечание. Если имеется некоторое исходное слово , а слово 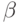 получилось из в результате одной ошибки, произошедшей, например, при передаче слова по каналу, то
получилось из в результате одной ошибки, произошедшей, например, при передаче слова по каналу, то 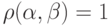 , т. е. в смысле Хеминга расстояние между ними равно 1.
, т. е. в смысле Хеминга расстояние между ними равно 1.
Аналогичным образом, если при передаче слова произошло 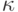 ошибок и оно превратилось в слово то
ошибок и оно превратилось в слово то 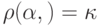 .
.
Утверждение. Код обнаруживает 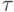 ошибок, если для любых кодовых слов и
ошибок, если для любых кодовых слов и 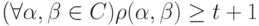 или
или  .
.
Рассмотрим, как происходит декодирование сообщения после его передачи через канал. Если при передаче не произошло ошибок, то будет получено кодовое слово. Естественно считать это кодовое слово результатом декодирования.
Если в результате передачи получено не кодовое слово, то произошла ошибка. В этом случае целесообразно использоватьдекодирование в ближайшее кодовое слово. Такой подход имеет объяснение. Действительно, пусть полученное слово 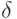 ближе к кодовому слову , чем к любому другому кодовому слову, т. е.
ближе к кодовому слову , чем к любому другому кодовому слову, т. е. 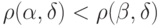 для всех кодовых слов
для всех кодовых слов  . Если сравнить различные гипотезы о том, какое исходное слово было пе-редано, то гипотеза о передаче слова при условии получения слова является наиболее вероятной. Это следует из того, что первая гипотеза (основная) соответствует меньшему числу ошибок при передаче, чем конкурирующие гипотезы.
. Если сравнить различные гипотезы о том, какое исходное слово было пе-редано, то гипотеза о передаче слова при условии получения слова является наиболее вероятной. Это следует из того, что первая гипотеза (основная) соответствует меньшему числу ошибок при передаче, чем конкурирующие гипотезы.
Утверждение. Код исправляет ошибок, если для любых кодовых слов и 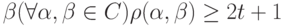 или
или 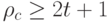 .
.
Для доказательства рассмотрим шары радиуса с центрами в кодовых словах. Из неравенства треугольника для расстояния Хеминга следует, что эти шары не пересекаются. Тогда при передаче любого кодового слова и при числе ошибок, не превышающем , полученное слово будет находиться в шаре с центром в передаваемом слове и декодироваться (по методу декодирования в ближайшее кодовое слово) в переданное слово.
Из последних двух утверждений следует, что важнейшей характеристикой кода, определяющей его корректирующие возможности, является его кодовое расстояние.
Рассмотрим, следуя [34], какие задачи требуется решать при создании кодов, с помощью которых можно эффективно обнаруживать и исправлять ошибки, возникающие при передаче сообщений. Одна из важнейших задач теории кодирования состоит в следующем. Требуется построить код, исправляющий ошибок и имеющий максимально возможное число точек. В геометрической постановке эта же задача звучит следующим образом: среди вершин единичного  -мерного куба требуется выделить максимальное число таким способом, чтобы расстояние между любыми двумя выделенными вершинами было не меньше, чем
-мерного куба требуется выделить максимальное число таким способом, чтобы расстояние между любыми двумя выделенными вершинами было не меньше, чем 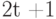 . Это максимальное число обозначается обычно через
. Это максимальное число обозначается обычно через 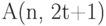 .
.
Другая, связанная с предыдущей, задача состоит в расположении 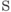 точек в вершинах так, чтобы наименьшее из попарных расстояний между ними было возможно большим. Это расстояние обозначается через
точек в вершинах так, чтобы наименьшее из попарных расстояний между ними было возможно большим. Это расстояние обозначается через  .
.
Выражения "построить", "выделить", "расположить" нуждаются в уточнении, так как нам вовсе не безразлично, в каком виде будет задан искомый код. Самый простой способ - перечисление всех кодовых точек - является неэффективным, требует большой памяти. Поэтому нужен такой способ задания кода, который позволяет просто восстановить каждую точку кода по ее номеру. Другими словами, код должен иметь простую реализацию. С некоторыми просто реализуемыми кодами мы познакомимся ниже. С другой стороны, мы хотим иметь возможность просто восстанавливать исходное сообщение на выходе.
Таким образом, "хороший код" должен удовлетворять следующим трем естественным требованиям:
1. исправлять много ошибок, т. е. иметь большое кодовое расстояние;
2. иметь несложную реализацию;
3. обладать простым алгоритмом исправления ошибок на приемном конце.
Следует отметить, что эти требования в значительной степени являются противоречивыми, так как код  , исправляющий много ошибок, вовсе не обязан иметь простую реализацию и тем более простой алгоритм декодирования. Поэтому на практике применяются коды, которые обладают в достаточной мере всеми тремя перечисленными выше качествами.
, исправляющий много ошибок, вовсе не обязан иметь простую реализацию и тем более простой алгоритм декодирования. Поэтому на практике применяются коды, которые обладают в достаточной мере всеми тремя перечисленными выше качествами.
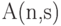 - максимальное число точек кода в , расстояние между любыми двумя кодовыми словами не меньше .
- максимальное число точек кода в , расстояние между любыми двумя кодовыми словами не меньше .
Для количественной оценки свойств кода полезно знать, насколько его параметры отличаются от параметров "идеального" кода. Для этого необходимо иметь хотя бы приближенные значения важнейших параметров "идеального" кода, т. е. значения 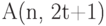 и . Следует отметить, что функции и не являются единственными параметрами, характеризующими качество кода. Не менее важными являются также такие параметры кода, как вероятностьправильного декодирования и вероятность обнаружения ошибки. Имеется также еще ряд других важных критериев, применяющихся для оценки качества кодов.
и . Следует отметить, что функции и не являются единственными параметрами, характеризующими качество кода. Не менее важными являются также такие параметры кода, как вероятностьправильного декодирования и вероятность обнаружения ошибки. Имеется также еще ряд других важных критериев, применяющихся для оценки качества кодов.
Дата добавления: 2015-08-11; просмотров: 948;