Общая схема аудиокодера и аудиодекодера МРЕG
Алгоритм сжатия MPEG, как и любой другой алгоритм сжатия, можно разделить на три этапа:
• предварительная обработка;
• основное преобразование;
• кодирование и упаковка компонент преобразования. На этапе предварительной обработки производится, в общем случае, подготовка исходного потока аудио данных к выполнению процедуры основного преобразования. В частности, можно выделить два вида такой подготовки: разбиение на блоки и фильтрация шумов. На втором этапе с помощью дискретного преобразования Фурье (ДПФ) входные отсчеты ИКМ преобразуются в 512 спектральных составляющих. Таким образом осуществляется переход от временного представления сигнала к
частотному [5]. На этапе кодирования и упаковки компонент производиться анализ частотной области психоакустической моделью, которая отбрасывает
неслышимые компоненты спектра и вычисляет шаг квантования, при котором шум квантования будет не слышен. Также на этом этапе осуществляется само квантование оставшихся спектральных отсчетов и, далее, они подвергаются кодированию по методу Хаффмана.
Алгоритм восстановления сигнала гораздо проще и состоит из двух
этапов [5]:
• восстановление отсчетов;
• обратное преобразование.
На этапе восстановления отсчетов происходит декодирование спектральных компонент. На втором этапе с помощью обратного ДПФ производиться переход к временному представлению сигнала. На рис. 2.17 приведены структурные схемы кодера и декодера MPEG.

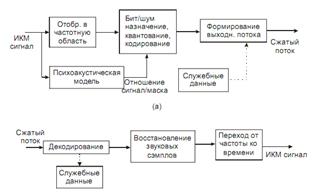
Рис. 2.17. Кодер (а) и декодер (б) MPEG.
Отображение в частотную область. Первый шаг кодирования аудио сигнала заключается в преобразовании его в частотную область. Для этого используют дискретное преобразование Фурье (ДПФ) [7]:

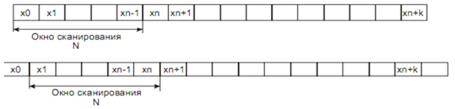
Рис. 2.19. Сканирование аудио потока "окном" N
Сдвиг может производиться как на один отсчет сигнала, так и сразу нанесколько. В кодеке MPEG сдвиг "окна" производиться на 32 отсчета, при размере "окна" 512 или 1024. Весь спектр делиться на 32 частотные полосы равной ширины (частотные поддиапазоны). На следующем этапе происходит устранение избыточности с помощью анализа спектра сигнала в психоакустической модели для каждой из частотных полос. Заметим, что
подобные идеи используются в ААС и других современных стандартах при кодировании частотных диапазонов (кодировании спектрограмм или сонограмм). Под сонограммой понимается график зависимости амплитуды от частоты и от времени. На рис.2.20 приведена для примера временная диаграмма колебаний струны, а на рис. 2.21 – соответствующая ей сонограмма. При анализе сонограмм (рис 2.21) видно, что спектр мало изменяется во времени меньшие изменения в области низких частот и чуть большие в области верхних частот верхних частот. 
Рис. 2.20. Временная диаграмма колебания струны
Рис. 2.21. Сонограмма колебания струны.
Следовательно, отличия в соседних спектрах соответствующих отсчетов
будут незначительны, а иногда их совсем не будет. Поэтому эффективнее
кодировать разность между соседними спектральными отсчетами, а не сами отсчеты. Дискретное косинусное преобразование. В большинстве современных
стандартах сжатия звука (в том числе, в стандарте МРЕG) применяется
дискретное косинусное преобразование (ДКП) выглядит следующим образом:
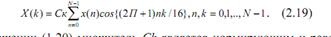 В
В
выражении (1.20) множитель Ck является нормирующим и равен 1/√2 при k=0 и равен единице для остальных значений индексов. Если производить вычисления по этой формуле, то вычислительная сложность составит 2
QДПФ= N базовых операций (БО). Но принимая во внимания особенности матрицы преобразования, можно сократить вычислительные затраты [5]. Психоакустическая модель. Психоакустическая модель позволяет
сократить спектр сигнала без изменения восприятия сжатого аудио сигнала, так как она учитывает особенности человеческого слуха и отбрасывает неслышимые частоты, которые маскируются более громкими звуками.
Психоакустическая модель дает возможность кодеру определить порог допустимого шума квантования для каждого поддипазона. Эта информация будет использована алгоритмом назначения битов, что в сочетании с
количеством имеющихся битов задаст число уровней квантования для каждой подполосы. Стандарт сжатия звука MPEG разрешает значительную свободу при реализации моделей. Изощренность этой реализации в конкретном кодере зависит от требуемой степени сжатия. В приложениях широкого потребления, в которых не требуется высокий фактор сжатия, психоакустическая модель может вовсе отсутствовать. В этом случае алгоритм назначения битов не использует соотношение сигнал/маскирование (SMR – signal to mask ratio). Основные шаги модели состоят в следующем: 1. Спектральные значения частотных полос разделяются на тональные (подобные синусоиде) и нетональные (шумоподобные) компоненты.
Компонента спектра X(k) считается тональной12, если:
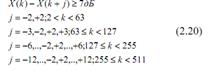
Полученные компоненты исключаются из исходного спектра, оставшиеся компоненты являются нетональными.
2. Прореживается спектр тональных компонент. Исключаются компоненты, лежащие ниже абсолютного порога слышимости. Оставшиеся компоненты прореживаются с помощью "окна" шириной 0,5 Барк.
3. В каждом поддиапазоне вычисляется порог маскирования для тональных и не тональных компонент. Маскируемые компоненты отбрасываются.
4. Вычисляется общее отношение сигнал/маскирование (SMR) для каждой субполосы кодирования. Сжатие коэффициентов. На следующем этапе происходит квантование и сжатие оставшихся спектральных компонент. Количество уровнейквантования выбираются на основании соотношения сигнал/маскирование, полученногона предыдущем этапе.
Сжатие коэффициентов осуществляется методами сжатия без потерь, например алгоритмом Хаффмана.
Декодер. Декодер MPEG проще кодера и состоит всего из двух этапов:
• восстановление отсчетов спектральной плотности;
• выполнение обратного преобразования Фурье.
Восстановление отсчетов спектральной плотности происходит из данных сжатых алгоритмом без потерь, в основном используется алгоритм Хаффмана. После выполнения обратного ПФ получается сигнал в ИКМ, готовый для воспроизведения или записи на носитель. AAC (Advanced Audio Coding). AAC - формат аудио-файла с меньшей потерей качества при кодировании, чем MP3 при одинаковых размерах. На 2005 год распространён существенно меньше, чем MP3 и другие альтернативныерешения. Этот стандарт изначально создавался как преемник MP3 с улучшеннымкачеством кодирования. Формат AAC, официально известный как ISO/IEC 13818-7, вышел в свет в 1997 как новая, седьмая, часть стандарта MPEG-2.Существует также формат AAC, известный как MPEG-4 Часть 3 [7]. AAC представляет собой широкополосный алгоритм кодирования аудио, в котором использует два основных принципа кодирования для сильного сжатия:
• удаляются не воспринимаемые слухом составляющие сигнала в
соответствии с психоакустической моделью;
• удаляется избыточность в кодированном аудио сигнале, а затем сигнал
обрабатывается MDCT согласно его сложности. Семейство алгоритмов аудио кодирования MPEG-4 охватывает диапазон от кодирования низкокачественной речи (до 2 кбит/с) до высококачественного
аудио (от 64 кбит/с на канал и выше).AAC имеет частоту сэмплов от 8 Гц до 96 кГц и количество каналов от 1 до 48. В отличие от гибридного набора фильтров MP3, AAC использует MDCT вместе с увеличенным размером окна до 2048 отсчетов. AAC более подходит для кодирования аудио с потоком сложных импульсов и прямоугольных сигналов чем MP3 или Musicam. AAC может динамически переключаться между блоками MDCT от 2048 отсчетов до 256 отсчетов. При кратковременном анализе используется малое окно в 256 отсчетов для лучшего разрешения. По умолчанию используется большое окно в 2048 отсчетов для улучшения
эффективности кодирования.
2.6. Анализ возможностей алгоритмов сжатия аудиосигналов Для того чтобы грамотно выбрать речевой кодек, достаточно представления об используемом в нем методе (на котором базируется алгоритм кодирования) и о процессе согласования сигнала, полученного после цифровой обработки, с цифровым каналом связи. Поскольку рассматриваемые методы кодирования являются методами сжатия звука с потерями, то при восстановлении (декодировании) звукового сигнала наблюдаются искажения сигнала.
Выводы. Рассмотрение существующих кодеков позволяет сформулировать ряд основных тенденций:
1. Доминирующее положение при построении низкоскоростных кодеков речи метода кодирования на основе линейного предсказания.
2. Возрастание доли адаптивных процедур обработки сигналов в современных системах кодирования речи.
3. Однозначная связь качества синтезированной речи на низких скоростях кодирования со степенью адаптации соответствующих кодеков речевых сигналов.
4. Наиболее перспективными являются алгоритмы сжатия типа CELP и его вариаций, а также векторного кодирования HVXC, положенные в основу методов МРЕG ААС, и более современных стандартов MPEG.
5. Использование более сложных алгоритмов энтропийного mкодирования (САВАС – контекстно-адаптивного арифметического кодирования)
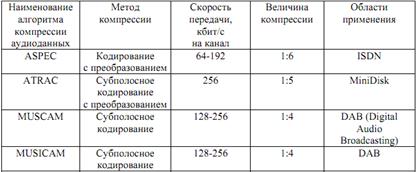
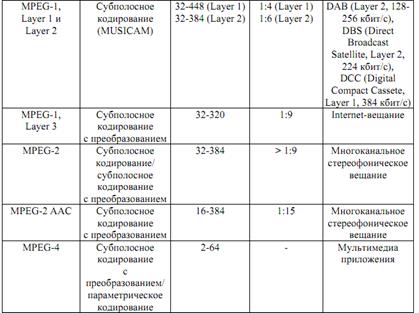
Таким образом, анализ степени адаптации современного парка кодековуказывает на перспективность перехода систем кодирования речи кмногопараметрической адаптации в условиях априорной и текущейнеопределенности в описании моделей речевого сигнала и внешней среды функционирования кодека. Наибольшая компрессия достигается в методах, которые учитываютособенности человеческого слуха, использующих разбиение на поддиапазоны и последующего проведения в них анализа. Некоторые примеры таких методов приведены в табл. 2.3. Кодеки MPEG являются наиболее распространенными и используют наиболее перспективный метод сжатия.

Дата добавления: 2015-04-07; просмотров: 2924;